
Things are changing incredibly quickly in the AI space. Only a few short years ago, most people barely knew AI existed. Today, by comparison, they use it every day, often without realizing it, and the pace of change shows no sign of slowing.
The problem is that AI isn’t one thing. It’s a sprawling collection of concepts, techniques, architectures, tools, and technologies. And then there are the acronyms. Oh my goodness, the acronyms. LLMs, SLMs, RAG, AGI, RLHF, NPU, TPU, MCP, A2A… it’s enough to make your eyes water and your head spin.
Despite the title of this column, it’s not my intent to turn you into an AI guru. My goal is simply to gather many of the key ideas into one place and explain them at a high level. Think of this as a guided tour through the AI landscape—a handy-dandy reference you can return to the next time someone says something like, “We’re deploying a sparse MoE transformer running quantized INT4 inference on an edge NPU,” and you find yourself smiling politely while sidling towards the door, desperately wondering what on earth they are waffling about.
Rather than presenting this as an alphabetical glossary of terms, I thought it might be more useful to take a journey through the AI ecosystem and explain how the various pieces fit together. So, strap yourself in, hold on to your hat, and let’s boldly go where far too many marketing departments have boldly attempted (and sadly failed) to go before.

HISTORY: HOW DID WE GET HERE?
Before we dive into the weeds, it’s important to understand that Artificial Intelligence (AI) is an umbrella term covering many different techniques and technologies. One of the biggest sources of confusion today is that people casually throw around terms like AI, Machine Learning (ML), Deep Learning (DL), and neural networks (NNs) as though they all mean the same thing. They don’t.
AI is the broadest category. If a machine performs tasks that appear to require human intelligence, it generally falls under the AI umbrella. Machine Learning is a subset of AI in which systems learn patterns from data rather than relying solely on explicitly programmed rules. Deep Learning is a subset of Machine Learning based on large artificial neural networks. Having said this, although Deep Learning is technically a subset of Machine Learning, it has become the dominant form of ML powering most modern AI systems. And Deep Neural Networks (DNNs) are the massively layered networks powering much of today’s AI boom. In a crunchy nutshell:
- AI is the big umbrella.
- ML is one branch of AI.
- DL is one branch of ML.
- DNNs are one of the engines driving modern DL.
- Most of today’s high-profile AI systems are powered by DL.
Easy-peasy lemon squeezy. Well… perhaps not that easy.
The formal birth of AI is usually traced to the famous Dartmouth Workshop held during the summer of 1956. Organized by John McCarthy, Marvin Minsky, Claude Shannon, and others, this event introduced the term “Artificial Intelligence” to the world. The participants believed human intelligence could potentially be described so precisely that machines could simulate it. In hindsight, they may have been just a tad optimistic regarding how quickly this would happen.
Early AI systems were largely symbolic and rule-based. Researchers attempted to explicitly encode human knowledge using logical rules such as: “IF patient has fever AND rash THEN possibly measles.”
This eventually led to expert systems, which enjoyed enormous popularity during the 1980s and early 1990s. I remember this era well. Companies were convinced that expert systems would revolutionize everything from medicine to finance to industrial control. Entire businesses sprang up around “knowledge engineering,” where human expertise was painstakingly translated into collections of rules.
Marketing departments happily scampered around slapping “AI Inside” stickers on everything, even products for which AI had no obvious application (like the way companies today boast “Gluten Free” on consumables that never contained gluten in the first place). As a result, much like gluten-free cuisine, 1990s AI left a bad taste in everyone’s mouth.
The problem was that real life turned out to be annoyingly complicated. Rule-based systems worked reasonably well in narrow domains, but they struggled with ambiguity, uncertainty, and the sheer messiness of the real world (you should see my sock drawer). Maintaining large rule bases also became increasingly unwieldy. Eventually, enthusiasm cooled, funding dried up, and the industry entered one of several periods now referred to as “AI Winters” (or “Now are the AI winters of our discontent,” as the Bard might have said).
As it happened, however, another idea had been quietly bubbling away in the background…
ARTIFICIAL NEURAL NETWORKS
Modern AI is dominated by Artificial Neural Networks (ANNs), which are loosely inspired by biological brains. The basic idea dates to 1943, when Warren McCulloch and Walter Pitts developed one of the first mathematical models of an artificial neuron (see A Logical Calculus of the Ideas Immanent in Nervous Activity).
A biological neuron receives signals from other neurons, combines them, and decides whether to “fire.” Artificial neurons operate in a somewhat similar fashion. Each neuron receives multiple inputs, multiplies them by weighting values (usually called weights or coefficients), adds everything together, and then applies an activation function to determine the output.
At the heart of almost every modern neural network lies an astonishingly simple operation known as the multiply-accumulate, or MAC.
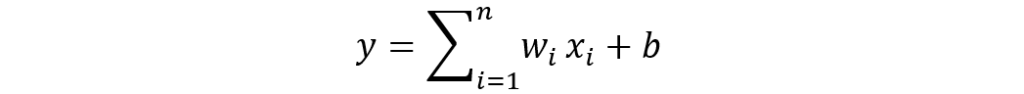
This equation may look intimidating at first glance, but it’s actually quite straightforward. Each input value is multiplied by a weighting factor, the results are summed together, and a bias term is added. The network “learns” by continuously adjusting those weights and biases during training.
What’s truly astonishing is that systems like ChatGPT, Gemini, Claude, and Grok ultimately boil down to trillions upon trillions of these “simple” MAC operations being performed over and over (and over) again.
The first generation of neural networks was relatively simple. Then came the perceptron in the late 1950s. Interest surged briefly before fading once researchers discovered severe limitations. Later, during the 1980s, the rediscovery and refinement of backpropagation breathed new life into the field by providing an effective way to train multilayer neural networks.
Even then, progress remained relatively slow because the available computing power simply wasn’t sufficient to efficiently train very large networks. The breakthrough came when researchers realized that Graphics Processing Units (GPUs), originally designed for video games, were extraordinarily good at performing the massively parallel arithmetic operations required by neural networks.
And the rest, as they say, is history.
SCALARs, VECTORs, MATRICEs, AND TENSORs (OH MY!)
This is probably a good time to briefly discuss scalars, vectors, matrices, and tensors, as these concepts appear throughout AI discussions.
- A scalar is simply a single value. For example, the number 42 is a scalar.
- A vector is an ordered collection of values. You can think of it as a one-dimensional list of numbers.
- A matrix is a two-dimensional array of values arranged in rows and columns.
- A tensor is the generalized extension of these ideas into higher dimensions. I tend to think of tensors as arrays of matrices. In practice, tensors are simply multidimensional arrays of numbers.
Neural networks spend much of their time performing operations on tensors. This is why modern AI hardware is designed to process enormous quantities of vector, matrix, and tensor arithmetic in parallel.
CPUs, GPUs, NPUs, AND TPUs
Traditional Central Processing Units (CPUs) are optimized for flexibility and sequential processing. They are wonderful general-purpose devices capable of handling a wide variety of tasks, but they are not especially efficient at the massively parallel arithmetic workloads associated with modern AI.
Digital Signal Processors (DSPs) were designed to accelerate mathematical operations commonly used in signal processing applications such as audio, video, and communications.
Graphics Processing Units (GPUs) contain thousands of relatively simple processing cores that can perform many operations simultaneously. This makes them exceptionally well-suited to neural network workloads involving large amounts of matrix and tensor arithmetic. Companies like NVIDIA rode this realization all the way to the bank… and then some.
Neural Processing Units (NPUs) are specialized accelerators designed specifically for AI workloads. They are increasingly appearing in PCs, smartphones, embedded systems, and edge devices.
Tensor Processing Units (TPUs) are AI accelerators developed by Google specifically for machine learning applications.
The exact boundaries between GPUs, NPUs, TPUs, and AI accelerators are becoming increasingly blurry. It goes without saying (but I’ll say it anyway) that marketing departments are not helping matters. Suffice it to say that modern AI hardware is largely about performing gigantic numbers of MAC operations as quickly and efficiently as possible while consuming the smallest practical amount of power.
Power matters. A lot. Training a state-of-the-art AI model may consume megawatt-hours of electricity and require data centers containing thousands upon thousands of accelerators. This is one reason companies are now obsessing over performance per watt rather than simply raw performance.
DIGITAL VS. ANALOG AI
Although most modern AI systems are implemented digitally, there’s nothing preventing neural networks from being realized using analog techniques. In fact, many researchers believe analog approaches may eventually become essential as AI workloads continue to grow and power consumption becomes increasingly problematic.
Traditional digital AI accelerators represent values using binary numbers and perform MAC operations using digital arithmetic units. This approach is flexible, reliable, programmable, and well understood. Unfortunately, moving enormous quantities of data back and forth between processors and memory consumes staggering amounts of power.
This is becoming a serious issue because modern AI models are huge. Training state-of-the-art systems may involve billions—or even trillions—of parameters. Simply moving all those numbers around can consume vast quantities of energy. As a result, researchers are exploring a variety of analog and near-analog approaches in which physics itself performs part of the computation.
One example involves floating-gate transistors, which can store analog values directly as electrical charge. Other approaches use SRAM or DRAM memory cells to perform computations inside the memory array itself, thereby reducing the need to shuttle data back and forth across power-hungry buses.
Some researchers are experimenting with operational amplifiers and analog crossbar arrays. Others are exploring memristors, exotic devices whose resistance depends on the history of the current flowing through them. Yet other groups are investigating photonic and optical AI systems in which light interference patterns perform computations at astonishing speeds.
At this point, you may be thinking, “Good grief, Max, this sounds like science fiction.” To be honest, some days it does to me too. Despite all this experimentation, however, the overwhelming majority of today’s commercial AI systems have their feet firmly planted in the digital domain. Compared to analog approaches, digital hardware is easier to manufacture reliably, easier to program, easier to debug, and generally less likely to burst into metaphorical flames at inconvenient moments.
SPIKING NEURAL NETWORKS AND NEUROMORPHIC COMPUTING
Traditional artificial neural networks process information continuously. Even when nothing particularly interesting is happening, the network keeps churning away doing unnecessary calculations. Biological brains, by comparison, tend to operate in a far more event-driven fashion. Neurons remain mostly quiet until something significant occurs (like when I hear someone say “bacon sandwich”), at which point they emit brief electrical pulses known as spikes.
This observation inspired researchers to develop Spiking Neural Networks (SNNs), which aim to more closely mimic certain aspects of biological neural behavior than conventional neural networks.
In a traditional ANN, neurons typically communicate using continuously varying numerical values. In an SNN, by comparison, neurons communicate primarily through the timing and occurrence of spikes. Information may be encoded not only in whether a neuron fires, but also when it fires.
This may sound like a subtle distinction, but it has profound implications. Since spikes occur only when meaningful events occur, spiking systems can be far more energy-efficient than conventional neural networks. Instead of continuously consuming power while endlessly crunching numbers, a spiking system can remain relatively quiet until something important happens.
Imagine a security camera watching an empty corridor. A conventional AI system might continuously process every pixel of every frame 24 hours a day, even when absolutely nothing changes. A spiking system, by contrast, could remain largely dormant until motion or some other significant event occurs.
This event-driven approach makes SNNs particularly attractive for edge AI applications where power consumption is critical. Unfortunately, nothing in engineering is ever simple. Training conventional neural networks is already challenging enough. Training spiking neural networks is even harder because spike timing introduces additional complexity. Researchers are still actively exploring the best algorithms, architectures, and learning techniques for these systems.
Closely related to SNNs is the broader field of neuromorphic computing. The term “neuromorphic” essentially means “brain-inspired.” Neuromorphic chips attempt to mimic certain organizational and operational characteristics of biological nervous systems in hardware. Unlike traditional processors, which separate memory and computation into distinct blocks, biological brains intertwine memory, communication, and computation in extraordinarily dense and efficient ways. Neuromorphic systems attempt—at least to some degree—to replicate this behavior.
Several major research efforts have explored this area. IBM developed its TrueNorth neuromorphic chip, while Intel created the Loihi family of neuromorphic research processors. These systems contain large numbers of artificial neurons and synapses communicating through spike-based signaling mechanisms.
One reason researchers find biological brains so fascinating is their extraordinary energy efficiency. The human brain consumes roughly 20 watts of power—less than many household light bulbs—yet it performs tasks that still challenge even the largest AI supercomputers. By comparison, training modern frontier AI models may require megawatts of power and data centers containing tens of thousands of accelerators.
Of course, we should be careful not to over-romanticize the brain. Biological nervous systems are messy, slow, noisy, and difficult to understand. Digital computers remain vastly superior for many forms of precise arithmetic and deterministic computation. Even so, the efficiency of biological intelligence continues to inspire researchers searching for new approaches to AI hardware and architectures.
At present, neuromorphic systems and spiking neural networks remain relatively niche compared to mainstream deep learning approaches. The overwhelming majority of today’s commercial AI systems still rely on conventional non-spiking neural networks running on digital hardware such as GPUs, NPUs, and TPUs.
Even so, many researchers believe neuromorphic and spiking approaches could eventually play an important role in ultra-low-power edge AI systems, autonomous robotics, sensory processing, and other applications where energy efficiency is paramount (see also my column Bodacious Buzz on the Brain-Boggling Neuromorphic Brain Chip Battlefront).
DIFFERENT TYPES OF NEURAL NETWORKS
As it turns out, saying “neural network” is rather like saying “vehicle.” A bicycle, a bulldozer, a Formula 1 race car, and a spacecraft are all vehicles, but they are optimized for very different purposes. Similarly, various neural network architectures have evolved to tackle different classes of problems.
Some networks are especially good at recognizing images. Others excel at processing sequences such as speech or text. Some are optimized for finding patterns in time-series data. Others are designed to generate entirely new content. Over the years, researchers have developed a bewildering variety of architectures, but a few families have proven particularly influential.
Convolutional Neural Networks (CNNs): These networks became famous for image recognition and computer vision applications. The key insight behind CNNs is that nearby pixels in an image are often related to one another. Instead of treating every pixel independently, CNNs use small filters—sometimes called kernels—that slide across the image looking for features such as edges, corners, textures, and patterns.
Early layers might detect simple features like lines and curves. Deeper layers progressively combine these into more complex structures such as eyes, wheels, faces, cats, dogs, traffic signs, or whatever else the network has been trained to recognize.
At some point, CNN researchers discovered something simultaneously fascinating and slightly alarming: networks trained to recognize ordinary objects often became astonishingly good at detecting cats.
CNNs proved enormously successful in applications such as image classification, facial recognition, medical imaging, industrial inspection, autonomous vehicles, and video analysis. For many years, CNNs dominated AI discussions, until “transformers” arrived and gate-crashed the party. But before we go there, we first need to discuss another important architecture…
Recurrent Neural Networks (RNNs): While CNNs are optimized for spatial relationships, RNNs were developed to handle sequences and time-dependent information. This is important because many real-world problems involve data arriving in order over time, including spoken language, written text, stock prices, sensor streams, weather patterns, music, and the list goes on.
Unlike ordinary feedforward networks, RNNs contain feedback connections that allow information from earlier steps to influence later processing. In effect, the network possesses a kind of internal memory. This made RNNs attractive for applications such as speech recognition, handwriting recognition, machine translation, and natural language processing.
Unfortunately, traditional RNNs suffered from problems such as vanishing and exploding gradients during training. (No, we’re not going to dive into that rabbit hole right now because life is too short and we still have another gazillion AI buzzwords to discuss.)
Researchers later developed improved variants such as Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), both of which helped address some of these issues. For a while, RNNs and LSTMs looked like the future of language AI… and then came transformers (cue dramatic music).
ATTENTION IS ALL YOU NEED
In 2017, researchers at Google published a paper with the deceptively innocent title Attention Is All You Need. This paper introduced the transformer architecture, which forever changed the AI landscape.
That may sound slightly melodramatic. It isn’t. Transformers solved several important limitations of earlier architectures. One of the biggest breakthroughs involved something called attention. Very loosely speaking, attention mechanisms allow a model to determine which parts of the input are most relevant as it processes information. Rather than treating every word or token equally, the network can “focus its attention” on the portions that matter most in the current context.
For example, consider the sentence: “The robot picked up the battery because it was heavy.” What does “it” refer to? The robot? The battery? Humans resolve these ambiguities almost effortlessly because we naturally consider context. Attention mechanisms allow transformer models to do something vaguely similar by learning relationships between different words and concepts. Even more importantly, transformers process data far more efficiently in parallel than traditional RNNs. This made them exceptionally well-suited to GPU acceleration and large-scale training.
And once researchers started scaling transformers upward—using larger datasets, larger models, and larger data centers—things became very interesting very quickly.
Transformers now form the foundation for many modern AI systems, including:
- Large Language Models (LLMs)
- Image generators
- Multimodal AI systems
- Coding assistants
- Generative AI tools
In many ways, transformers are the engines driving today’s AI revolution.
SPARSITY AND MIXTURE OF EXPERTS
One major challenge with gigantic AI models is that they are… well… gigantic. The term “frontier model” refers to a state-of-the-art AI model that sits at the leading edge—or frontier—of current AI capabilities. In practice, the term is usually used to describe the largest, most capable, most computationally expensive, and most general-purpose AI systems currently available.
Modern frontier models may contain hundreds of billions—or even trillions—of parameters, most of them weights. Running all those parameters continuously requires enormous quantities of computation, memory bandwidth, and power.
Sparsity: The basic idea here is surprisingly simple: perhaps not every neuron, weight, or connection needs to be active all the time. There are several forms of sparsity.
- Unstructured sparsity removes individual weights that contribute little to the final result.
- Structured sparsity removes entire groups, blocks, channels, or layers in ways that are more hardware-friendly.
- Dynamic sparsity allows different portions of the network to activate depending on the current task or input.
This reduces computational workload, lowers power consumption, and improves efficiency. Which brings us naturally to…
Mixture of Experts (MoE): These architectures are among the cleverest ideas to emerge in recent AI systems. Instead of building a single monolithic network in which every neuron participates in every task, an MoE model divides the system into multiple specialized subnetworks, known as experts. A separate routing mechanism then decides which experts should participate for any given input.
Imagine visiting a hospital. You probably don’t want a dermatologist performing heart surgery or a podiatrist conducting brain surgery. Different specialists handle different problems. MoE systems operate in a somewhat similar fashion. One expert might specialize in mathematics. Another in programming. Another in language translation. And another in scientific reasoning.
Rather than activating the entire model every time, the router selectively engages only the most relevant experts. This can dramatically reduce computational requirements while still allowing the overall system to become extremely large and capable.
Of course, once you start building gigantic sparse transformer-based MoE models containing trillions of parameters distributed across thousands of accelerators spread throughout hyperscale data centers, things can become just a teensy bit complicated. Welcome to the world of modern AI.
FOUNDATION MODELS, LLMs, SLMs, AND MULTIMODAL AI
But what exactly are systems like ChatGPT, Gemini, Claude, Grok, and their increasingly numerous cousins? One term we hear a lot these days is foundation model. This refers to a large, general-purpose AI model trained on enormous amounts of data, serving as the foundation for many downstream applications.
Instead of building separate AI systems for each task, researchers discovered it was often more effective to train a single, large, general-purpose model and then adapt it to many different uses.
This represented a major shift in thinking. Earlier AI systems were often highly specialized. One model might recognize faces. Another might translate languages. Another might identify defects on production lines. Foundation models, by contrast, attempt to learn broad patterns and relationships that can be applied across many domains. Some foundation models specialize primarily in language. Others process images, audio, video, code, or combinations thereof.
Closely related—but not identical—is the concept of a frontier model (as we mentioned earlier). While a foundation model describes a model’s general-purpose role, a frontier model refers to a system operating at the bleeding edge of current AI capability. These are the enormous, eye-wateringly expensive models consuming industrial quantities of compute, power, memory, and money while researchers attempt to push the boundaries of what AI can do.
In practice, most frontier models are also foundation models, but not all foundation models are frontier models. A relatively modest language model running locally on a laptop may still qualify as a foundation model because it supports many downstream applications. By comparison, systems like ChatGPT, Gemini, Claude, and Grok are both foundation models and frontier models because they sit at the leading edge of present-day AI capability.
Large Language Models (LLMs): These are transformer-based neural networks trained on vast quantities of text data. The “large” part refers both to the number of parameters in the model and the enormous datasets used during training. The “language” part refers to the fact that these systems are fundamentally designed to process and generate sequences of tokens representing human language.
Very loosely speaking, an LLM learns statistical relationships between words, phrases, concepts, patterns, and contexts. At first glance, this may sound underwhelming. “Wait,” people say, “are you telling me ChatGPT is basically just predicting the next word?”
Well, yes… and no. At the lowest level, next-token prediction really is a core part of what many LLMs do. The astonishing part is that when models become sufficiently large and are trained on sufficiently large datasets, remarkably sophisticated behaviors can emerge.
LLMs can summarize documents, answer questions, generate software, explain concepts, translate languages, write poetry, compose emails, generate marketing materials, and occasionally hallucinate with breathtaking confidence. Some modern LLMs also demonstrate forms of reasoning, planning, and tool usage that would have seemed almost magical only a few years ago.
Modern frontier models may contain hundreds of billions—or even trillions—of parameters. Running such models efficiently requires astonishing quantities of computation, memory bandwidth, storage, cooling, and electrical power.
Small Language Models (SLMs): Not every application requires a gigantic cloud-scale model consuming enough electricity to power a small town. This has led to growing interest in SLMs, which use fewer parameters and require far less memory, compute, and power than massive frontier LLMs.
Although SLMs may not match the raw capabilities of the larger systems, they can still perform remarkably well for targeted applications. This is especially important for edge AI systems running on laptops, smartphones, embedded devices, industrial controllers, autonomous sensors, and battery-powered hardware.
In many cases, a well-designed SLM running locally may be preferable to a gigantic cloud-hosted model because it offers lower latency, lower cost, improved privacy, reduced bandwidth requirements, and lower power consumption. Sometimes, smaller really is better.
Multimodal AI and Vision-Language Models (VLMs): Early AI systems often specialized in only one type of data. Some processed text, others analyzed images, and some handled speech. By comparison, modern multimodal systems attempt to combine multiple forms of information simultaneously. A multimodal AI model may be able to read text, analyze images, interpret audio, understand video, generate speech, and respond conversationally.
For example, a multimodal assistant might examine a photograph of a damaged industrial component, read associated maintenance logs, listen to spoken questions from an engineer, and then generate both textual and spoken recommendations. This is one reason modern AI systems increasingly feel less like traditional software and more like generalized digital assistants.
One particularly important category is the Vision-Language Model (VLM), which combines computer vision and natural language processing capabilities in a unified system. VLMs can analyze images and discuss their contents in a conversational manner. For example, a VLM might examine a photograph, identify objects within the scene, explain what is happening, answer questions about the image, or generate descriptive captions.
This capability lies at the heart of many modern multimodal assistants. Meanwhile, diffusion models—which power many AI image generators—use entirely different mechanisms to generate pictures, artwork, and video by progressively refining random noise into meaningful images.
Of course, none of these models magically spring into existence fully formed. Before an AI system can recognize images, answer questions, generate software, or confidently invent facts that exist only in its electronic imagination, it first needs to be trained…
DIFFERENT WAYS AI SYSTEMS LEARN
Not all AI systems learn in the same way. In fact, one of the biggest differences between AI systems lies in how they are trained. Over the years, researchers have developed several major learning paradigms, each suited to different classes of problems.
Supervised Learning: This is probably the easiest form of machine learning to understand. The system is trained on labeled examples where both the input and the correct answer are known. For example, a network might be shown millions of images labeled “cat,” “dog,” “car,” and “banana.” During training, the system repeatedly makes predictions, compares them with the correct labels, calculates its errors, and adjusts its internal weights to improve future performance.
Supervised learning powers many applications, including image recognition, speech recognition, spam filtering, medical diagnosis, and industrial inspection.
Unsupervised Learning: In unsupervised learning, the system receives data without explicit labels or correct answers. Instead of being told what patterns to look for, the AI attempts to discover structure within the data on its own. This may involve clustering similar items together, identifying anomalies, compressing information, discovering hidden relationships, or extracting meaningful features from enormous datasets.
One way to think about this is that supervised learning involves a teacher marking homework, while unsupervised learning resembles giving a child a giant box of puzzle pieces and saying, “See what patterns you can find.”
Reinforcement Learning (RL): Reinforcement learning takes a rather different approach. Instead of learning from labeled examples, the system learns through trial and error while interacting with an environment. Very loosely speaking, the AI performs actions, receives rewards or penalties, and gradually learns which behaviors produce the best long-term outcomes.
This approach is especially useful for problems involving sequential decision-making, including robotics, autonomous systems, game playing, optimization, and control systems. One famous example was DeepMind’s AlphaGo system, which learned strategies capable of defeating world champion Go players. More recently, reinforcement learning techniques have also played important roles in modern generative AI systems.
Self-Supervised Learning and RLHF: Modern Large Language Models often rely heavily on self-supervised learning, in which the system effectively generates parts of its own training signal. For example, a model may learn by predicting missing words or the next token in massive quantities of internet text.
Many frontier models are then further refined using Reinforcement Learning from Human Feedback (RLHF). In this approach, humans evaluate model outputs and provide feedback to steer the system toward responses that people find more useful, accurate, and aligned with human expectations. Or, at least, that’s the general idea. Sometimes the humans disagree. Sometimes the AI disagrees. And sometimes everyone confidently heads off in entirely the wrong direction together.
TRAINING VS. INFERENCE
Training is the process of teaching a neural network by exposing it to enormous quantities of data and continuously adjusting its internal parameters—primarily its weights—so that its outputs gradually improve over time.
Very loosely speaking, the model begins life essentially knowing nothing. During training, it repeatedly makes predictions, compares them with the correct answers, calculates how wrong it was, and then adjusts its weights to reduce future errors.
This process may be repeated billions—or even trillions—of times. Modern training runs are staggeringly computationally intensive. Frontier models may require massive datasets, thousands of accelerators, weeks or months of computation, enormous quantities of memory, elaborate cooling systems, and industrial quantities of electrical power.
Training a state-of-the-art frontier model can cost millions—or even hundreds of millions—of dollars. This is one reason only a relatively small number of organizations currently possess the resources necessary to train the largest AI systems.
Once a model has been trained, however, the heavy lifting is largely complete. The next phase is inference, which simply means using the trained model to perform useful work. Every time you ask ChatGPT a question, every time your smartphone recognizes your face, every time an AI system analyzes an image, translates text, or detects an object, the system is performing inference.
One of the most important distinctions between training and inference is frequency.
Training may happen once, or at least relatively infrequently. Inference may happen billions upon billions of times. As a result, the design priorities are often very different. Training systems prioritize maximum accuracy, massive compute throughput, enormous memory capacity, and scalability across humongous data centers. Inference systems, by contrast, often prioritize low latency, low cost, low power, reduced memory usage, and real-time responsiveness.
This distinction becomes especially important for edge AI applications running on laptops, smartphones, embedded systems, industrial controllers, autonomous sensors, and battery-powered devices. A cloud data center may happily consume megawatts of power while training a frontier model. A tiny edge device running inference may need to survive for months—or even years—on a coin-cell battery.
One important consequence is that AI systems frequently use different numerical formats during training and inference. Which brings us naturally to floating-point numbers, integers, quantization… and yet more acronyms.
DATA TYPES AND QUANTIZATION
AI systems manipulate truly enormous quantities of numerical data. Inputs, outputs, activations, gradients, weights, biases, embeddings, and attention matrices are all represented as numbers. And the way these numbers are represented has an enormous impact on accuracy, memory usage, bandwidth, performance, cost, and power consumption.
For many years, most neural network training used 32-bit floating-point arithmetic, usually abbreviated FP32. This format offers excellent numerical precision and a very large dynamic range, which makes it highly suitable for training neural networks. Unfortunately, FP32 also consumes substantial memory and bandwidth while requiring considerable computational resources.
As AI models became larger, researchers began exploring lower-precision formats. One major step was FP16, which uses 16-bit floating-point values instead of 32-bit values. FP16 reduces memory requirements and increases computational throughput, allowing accelerators to process more operations per second while consuming less power.
Another important format is BF16, which stands for Brain Floating Point. Originally developed by Google, BF16 also uses 16 bits but allocates those bits differently from FP16. BF16 sacrifices some precision while preserving a dynamic range closer to FP32, making it particularly attractive for training large neural networks. More recently, researchers and hardware vendors have begun exploring even smaller formats such as FP8.
Alongside floating-point formats, AI systems also make extensive use of integer formats such as INT8 and INT4 because Integer arithmetic is generally simpler, faster, and more energy efficient. This is especially important during inference.
A common approach is to train a model using higher-precision floating-point arithmetic and then convert it into lower-precision integer formats for deployment. This process is known as quantization. For example, a model might initially be trained using FP32 or BF16 arithmetic and later quantized into INT8 or INT4 form for inference.
Why bother? Because smaller numerical formats dramatically reduce memory requirements, storage requirements, bandwidth, power consumption, and computational workload. A model represented using INT4 values may require only a fraction of the memory required by the same model represented in FP32. This matters because modern frontier models may contain hundreds of billions—or even trillions—of parameters. Even modest reductions in storage requirements can translate into enormous savings in hardware cost, energy consumption, and inference latency.
Of course, lower precision also introduces tradeoffs. Aggressive quantization can reduce accuracy, increase numerical errors, and occasionally produce behavior that ranges from mildly amusing to deeply puzzling. Engineering, as always, is the art of balancing compromises.
The good news is that modern AI hardware increasingly includes specialized support for formats such as FP16, BF16, FP8, INT8, and INT4. As a result, AI accelerators now devote enormous amounts of silicon to performing vast quantities of low-precision arithmetic at extraordinary speeds and with ever-improving energy efficiency.
FRAMEWORKS, LIBRARIES, AND SOFTWARE ECOSYSTEMS
Of course, AI isn’t built using hardware alone. Modern AI development relies heavily on enormous software ecosystems consisting of frameworks, libraries, compilers, runtimes, drivers, and tools.
Among the best-known AI frameworks are TensorFlow, originally developed by Google, and PyTorch, originally developed by Facebook (now Meta). These frameworks provide the mathematical building blocks required to define, train, and deploy neural networks without forcing researchers to write millions of lines of low-level code from scratch.
In many ways, frameworks like PyTorch and TensorFlow are to modern AI researchers what power tools are to carpenters. Technically speaking, you could attempt everything manually using low-level programming and raw linear algebra, but most people prefer retaining at least some portion of their sanity.
Other important pieces of the ecosystem include:
- CUDA, NVIDIA’s GPU computing platform.
- ONNX for exchanging models between frameworks.
- Hugging Face for sharing and deploying models.
- Countless specialized libraries optimized for training and inference.
Earlier frameworks such as Caffe, Theano, and Torch helped lay important groundwork during the early stages of the deep-learning revolution, but newer ecosystems now dominate most mainstream AI development.
DIFFERENT FLAVORS OF AI (OOH, TASTY!)
You may have noticed that people increasingly talk about different “types” or “flavors” of AI. To be honest, the ever-expanding body of terminology is evolving so rapidly that merely keeping track of the buzzwords can feel like a full-time occupation. In some cases, we’re retroactively assigning new names to older technologies simply to distinguish them from their more recent cousins. The good news is that most of these terms do not describe entirely different underlying technologies. In many cases, they simply describe different ways AI systems interact with the world
Assistive AI sits somewhere between “helpful sidekick” and “turbocharged tool.” Rather than doing the job for you, it helps you do a better job yourself—offering suggestions, highlighting issues, and nudging you in the right direction. Think spell checkers, grammar checkers, code assistants, and recommendation engines. In all these cases, humans remain firmly in charge; the AI just makes them faster, sharper, and (one hopes) slightly less error-prone.
Perceptive AI refers to systems that can sense, interpret, and understand the physical world using data from sensors, especially vision, audio, and other real-world inputs. We can think of it as AI that can answer questions like “What am I looking at?”, “What am I hearing?”, and “What’s happening around me right now?”
Typical capabilities include object detection (cars, people, cats, etc.), image classification, facial recognition, speech recognition, and sensor fusion. In perceptive AI systems, sensor fusion is the process of combining data from multiple sensors to create a more accurate and reliable understanding of the real world than any single sensor could provide alone. If Perceptive AI gives machines their senses, then sensor fusion is what stops them from jumping to conclusions. It’s the difference between “I heard a noise” and “I heard a noise, saw something move, and yes—that’s definitely the stupid cat again.”
Enhancive AI refers to systems that improve, restore, refine, or augment existing data, content, or processes. Instead of asking “What is this?” (perceptive AI), enhancive AI asks “How can I make this better?”
To put this another way, enhancive AI doesn’t create something new; it takes what you already have and makes it better. Typical examples include upscaling low-resolution images, removing noise from audio signals, enhancing video quality and frame rates, cleaning up sensor data, and optimizing workflows and system performance. In all these cases, the input already exists; the AI’s job is to polish, sharpen, or otherwise improve its quality or usefulness.
For example, an image enhancement system might take a blurry, low-resolution photo and transform it into a crisp, detailed image. Similarly, an audio enhancement system might remove background noise and clarify speech, while a signal-processing system might extract meaningful information from noisy sensor readings.
Generative AI (GenAI) refers to systems that can create new content—text, images, audio, video, code, and more—based on patterns learned from vast amounts of data. Instead of simply interpreting existing information, Generative AI can produce entirely new material in response to prompts like “Write me a story about…”, “Draw me a picture of…”, and “Generate some code that does…”
Typical examples include large language models, image generators, music generators, and code-generation tools. The key thing to remember is that Generative AI doesn’t “know” things the way humans do. Instead, it has learned statistical patterns and uses those patterns to produce outputs that are often remarkably convincing (and occasionally hilariously wrong).
Agentic AI refers to autonomous systems that can act independently to achieve complex, multi-step goals with minimal human oversight. Unlike passive, generative AI systems that simply respond to prompts, agentic systems ask, “What needs to be done—and how do I get it done?”
These systems combine reasoning, planning, and the use of external tools to proactively execute full workflows. Instead of generating a single response, they can break a task into steps, decide what actions to take, call tools or application programming interfaces (APIs), evaluate results, and adjust their approach as needed.
For example, an agentic system might research a topic, generate a report, refine it, and send it to the appropriate people—all with minimal human intervention. Of course, “autonomous” doesn’t mean “infallible.” Left unsupervised, some agents can wander off course like an overconfident intern with admin privileges.
A common analogy is to think of Agentic AI as the conductor of an orchestra, with individual AI agents acting as the musicians. The conductor interprets the goal, decides who should do what and when, and keeps everything in sync, while each agent performs a specific task—researching, coding, writing, or analyzing. In more advanced systems, the conductor can even “bring in” new musicians as needed, spawning additional agents to handle different parts of the job. The result is a coordinated ensemble capable of tackling complex, multi-step problems that would overwhelm any single player.
Of course, as with any orchestra, things can occasionally go awry. Left unchecked, one enthusiastic violinist (agent) may decide to improvise, while the percussion section (another agent) enthusiastically follows along, and before you know it, the whole performance has taken on a life of its own, and instead of listening to a stately classical piece, we find ourselves tap-dancing to a polka.
Physical AI refers to systems that interact directly with the physical world through machines and devices such as robots, autonomous vehicles, drones, industrial systems, and embodied agents. Instead of just perceiving, enhancing, generating, or deciding, Physical AI asks, “What action should I take—and how do I physically carry it out?”
CLOUD AI, EDGE AI, AND EVERYTHING IN BETWEEN
All of our AI computation must ultimately run somewhere. In many people’s minds, AI lives “in the cloud,” floating around in some magical digital realm inhabited by chatbots, recommendation engines, and suspiciously cheerful virtual assistants.
In reality, the so-called “cloud” consists of gigantic data centers packed with eye-wateringly expensive hardware. Modern AI data centers may contain tens of thousands of GPUs, specialized AI accelerators, ultra-high-bandwidth memory systems, high-speed optical interconnects, and cooling systems substantial enough to make small hydroelectric projects feel slightly inadequate. Some of these systems are dedicated primarily to training frontier models, while others are optimized to handle the staggering volume of inference requests generated by billions of users.
Companies such as NVIDIA, Google, Microsoft, Amazon, and OpenAI are investing staggering sums of money in building the infrastructure required to train and deploy frontier AI models. This is one reason AI has rapidly become as much an infrastructure and energy story as it is a software story.
Training frontier models is one thing. Running inference at a planetary scale is something else entirely. Every AI-generated response, image, recommendation, translation, or search result consumes computation somewhere. Multiply that by billions of users, and the infrastructure requirements quickly become enormous. This has triggered an industry-wide obsession with performance per watt, memory bandwidth, cooling, latency, and accelerator efficiency. In turn, this is why researchers are exploring alternatives to traditional GPU-centric AI infrastructure.
FPGA-Based Inference: One particularly intriguing development involves the use of Field Programmable Gate Arrays (FPGAs) for AI inference workloads. Traditionally, GPUs and NPUs have dominated AI acceleration because they are extremely good at parallel numerical processing. However, FPGAs offer several potential advantages, including custom data paths, highly optimized pipelines, deterministic latency, and potentially superior energy efficiency.
One company making waves in this area is ElastixAI, which claims its FPGA-based approach can outperform GPUs for certain Large Language Model inference tasks. Part of the attraction is that FPGAs can be configured to match specific workloads extremely efficiently. Instead of relying on general-purpose processing structures, designers can create highly specialized dataflow architectures optimized for particular AI models and numerical formats (see my column, FPGAs Beating GPUs at LLM Inference, for more details).
Edge AI: Although cloud AI receives enormous attention, many AI workloads are increasingly moving toward the edge, where the “digital rubber” meets the “real-world road.” In this context, the “edge” refers to systems operating close to where data is generated rather than in distant cloud data centers. Examples include smartphones, industrial controllers, robots, autonomous vehicles, medical devices, drones, smart cameras, wearables, and battery-powered sensors.
Edge AI offers several important advantages. First, local inference reduces latency because data no longer needs to travel to and from the cloud. This can be critically important for real-time systems such as industrial automation, autonomous vehicles, and robotics. Second, local processing improves privacy because sensitive data can remain on the device rather than being transmitted across networks. And third, edge AI reduces bandwidth requirements and cloud infrastructure costs.
Of course, edge devices typically operate under severe constraints involving power, memory, thermal dissipation, cost, and physical size. Running AI on a tiny embedded system is very different from running it inside a hyperscale data center containing megawatts of cooling infrastructure and enough GPUs to frighten the national power grid.
This has fueled enormous interest in highly efficient AI-enabled microprocessors (MPUs) and microcontrollers (MCUs).
AI-Enabled MCUs and MPUs: Many semiconductor companies are now integrating NPUs and AI accelerators directly into microcontrollers (MCUs) and microprocessors (MPUs).
This allows devices to perform local inference while consuming relatively modest amounts of power.
One particularly interesting example is Alif Semiconductor, whose devices combine traditional processing cores with AI acceleration hardware to target edge applications (see also my column AI+AR Glasses That Remember Where You Left Your Keys).
The goal is to enable intelligent embedded systems capable of voice recognition, computer vision, sensor fusion, predictive maintenance, anomaly detection, and contextual awareness, all without requiring constant cloud connectivity.
New Ideas Bubbling to the Surface: The AI boom is also stimulating renewed interest in entirely new processor architectures. For decades, mainstream computing largely revolved around variations of the same general-purpose CPU concepts. AI, however, places unusually heavy emphasis on parallelism, data movement, memory bandwidth, and energy efficiency. As a result, researchers and startups alike are exploring radically different approaches.
One especially intriguing company is Efficient Computer, whose architecture attempts to dramatically improve energy efficiency compared to traditional processors. The company claims its approach can deliver orders-of-magnitude improvements in efficiency for certain workloads (see also my column Efficient Computer’s Efficient Computer is 100X More Energy Efficient than Other General-Purpose Processors).
Whether any particular architecture ultimately succeeds remains to be seen. The history of computing is littered with brilliant ideas that failed commercially for one reason or another. Even so, the sheer scale of AI workloads is forcing the industry to rethink long-standing assumptions about computing architectures, memory hierarchies, interconnects, and accelerator design. And this brings us naturally to one of the hottest topics in modern AI: agents.
RAG, AGENTS, MCP, AND A2A: One of the biggest limitations of traditional Large Language Models is that they do not inherently “know” anything beyond the data used during training.
An LLM may have been trained months ago. It may not know about recent events, private company documents, live databases, or your latest engineering specification.
This is where Retrieval-Augmented Generation (RAG) enters the picture. Very loosely speaking, RAG allows an AI system to retrieve relevant information from external sources before generating its response. Instead of relying entirely on internal statistical patterns learned during training, the AI can search documents, query databases, retrieve web content, access knowledge bases, and incorporate fresh information into its responses.
We can think of a RAG-enabled system as rather like an engineer quietly consulting the datasheet before confidently pretending to have known everything all along (that’s certainly how I do things).
Closely related to RAG is the rapidly emerging field of AI agents. Traditional generative AI systems typically respond to prompts one interaction at a time. Agentic AI systems, by contrast, attempt to pursue goals.
An agentic system may break problems into smaller tasks and use specialized agents to plan workflows, search for information, execute software tools, call APIs, maintain memory, evaluate intermediate results, revise plans, and interact with other agents.
In effect, the system behaves less like a simple chatbot and more like a team of autonomous software workers.
One useful analogy is to think of Agentic AI as the conductor of an orchestra, with individual AI agents acting as the musicians. The conductor interprets the goal, decides who should do what and when, and keeps everything synchronized while each agent performs a specific task—researching, coding, analyzing, or writing.
In more advanced systems, the conductor may even spawn additional agents dynamically to handle specialized subtasks. Naturally, this can occasionally lead to situations in which one enthusiastic agent decides to improvise while another agent enthusiastically follows along, and before you know it, the entire system has wandered off into computational jazz fusion territory. This is one reason human oversight remains rather important.
Several emerging technologies are helping standardize these increasingly complex AI ecosystems. Model Context Protocol (MCP) provides standardized mechanisms allowing AI systems to interact with external tools, services, and information sources. Agent-to-Agent communication (A2A) focuses on enabling AI agents to coordinate and collaborate.
Taken together, these developments are transforming AI systems from isolated models into interconnected ecosystems capable of increasingly sophisticated autonomous behavior. All of which brings us to the elephant in the room and the fly in the ointment (I never metaphor I didn’t like)…
AGI, THE SINGULARITY, AND THE FUTURE
Current AI systems are generally narrow in scope. Even extremely capable models remain fundamentally specialized systems trained to perform particular classes of tasks. This is the point at which discussions about AI often drift toward Artificial General Intelligence, usually abbreviated as AGI.
AGI refers to a hypothetical future system possessing broad, human-like general intelligence capable of learning, reasoning, adapting, and operating across many domains at or beyond human levels. Whether AGI is imminent, decades away, fundamentally impossible, or already quietly running your social media feed remains a topic of intense debate.
Closely related is the concept of the technological singularity. This represents the theoretical turning point at which AI systems become capable of recursively improving themselves. Once machine intelligence surpasses human intelligence, further advances could potentially accelerate beyond human comprehension, leading to rapid and unpredictable societal transformation (cue nervous laughter).
Supporters view this possibility with excitement. Critics view it with the same enthusiasm one might reserve for an incoming asteroid. As is often the case, reality will probably turn out to be more complicated than either extreme predicts.
It’s amazing to me that, as far back as 1843, while working with Charles Babbage on his Analytical Engine, Ada Lovelace speculated that sufficiently advanced analytical engines might someday compose elaborate and scientific pieces of music. Nearly two centuries later, machines are composing music, generating artwork, writing software, designing hardware, driving vehicles, generating video, and engaging in increasingly sophisticated conversations with humans.
If only Ada could see us now (if I ever get my time machine working…). Whether this ultimately leads to AGI remains uncertain (although, if I were a betting man…). What is certain is that AI is no longer a futuristic curiosity confined to science fiction novels and late-night academic discussions. It is rapidly becoming one of the defining technologies of our age. Which means those bewildering acronyms probably aren’t going away anytime soon.
Related


