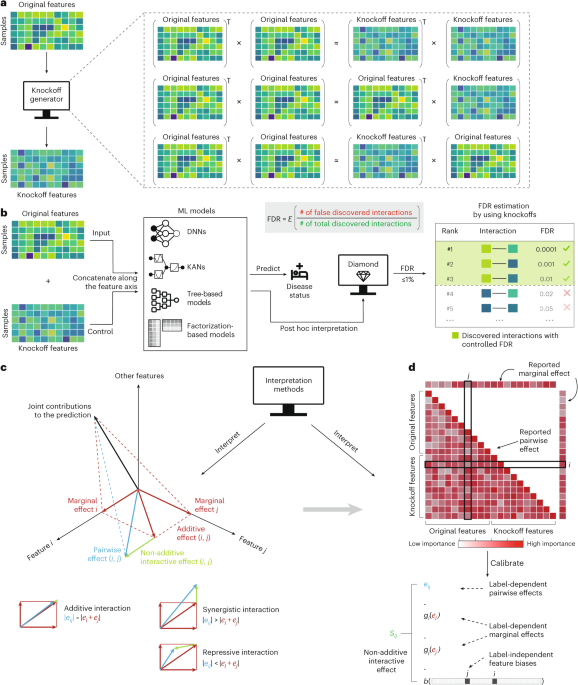
Diamond overview
Consider a prediction task in which we have n independent and identically distributed samples \({\bf{X}}={\left\{{x}_{i}\right\}}_{i = 1}^{n}\in {{\mathbb{R}}}^{n\times p}\) and \({\bf{Y}}={\left\{{y}_{i}\right\}}_{i = 1}^{n}\in {{\mathbb{R}}}^{n\times 1}\), denoting the data matrix with p-dimensional features and the corresponding response, respectively. The response of the prediction task can be categorical labels such as disease status or numerical measurements such as body mass index (BMI), and the features could include gene expression data, microbial taxa abundance profiles and so on. The prediction task can be described using an ML model \(f:{{\mathbb{R}}}^{p}\mapsto {\mathbb{R}}\) that maps from the input \(x\in {{\mathbb{R}}}^{p}\) to the response \(y\in {\mathbb{R}}\). When modelling the task, the function f learns the dependence structure of Y on X, enabling effective prediction with the fitted ML model.
In this study, we focus on interpreting the fitted ML model for data-driven scientific discovery by identifying the non-additive feature interactions that contribute most to the model’s predictions. We say that \({\mathcal{I}}\subset \{1 \ldots p\}\) is a non-additive interaction of function f if and only if f cannot be decomposed into an addition of \(\left\vert {\mathcal{I}}\right\vert\) subfunctions fi, each of which excludes a corresponding interaction feature10,30, that is, \(f(x)\ne {\sum }_{i\in {\mathcal{I}}}\;{f}_{i}\left({x}_{\{1,\ldots ,p\}\backslash i}\right)\). For example, the multiplication between two features xi and xj is a non-additive interaction because it cannot be decomposed into a sum of univariate functions, that is, f(xi, xj) = xixj ≠ fi(xj) + fj(xi). On the other hand, log(xixj) is considered to be an additive interaction because it can be decomposed in the logarithmic space, that is, f(xi, xj) = log(xixj)= log(xj) + log(xi). Assume that there exists a group of interactions \({\mathcal{S}}=\left\{{{\mathcal{I}}}_{1},{{\mathcal{I}}}_{2},\ldots \,\right\}\) such that, conditional on interactions \({\mathcal{S}}\), the response Y is independent of interactions in the complement \({{\mathcal{S}}}^{c}=\{1,\ldots \,,p\}\times \{1,\ldots \,,p\}\backslash {\mathcal{S}}\). In this setting, our goal is to accurately discover feature interactions in \({\mathcal{S}}\) without erroneously reporting too many incorrect interactions in \({{\mathcal{S}}}^{c}\).
Diamond is designed to discover feature interactions from fitted ML models and maintain a controlled FDR25. For a set of feature interactions \(\widehat{S}\subset \{1,\ldots \,,p\}\times \{1,\ldots \,,p\}\) discovered by some interaction detection method, the FDR is defined as
$${\rm{FDR}}={\mathbb{E}}[{\rm{FDP}}]\,{\rm{with}}\,{\rm{FDP}}=\frac{| \widehat{S}\cap {{\mathcal{S}}}^{c}| }{| \widehat{S}| }.$$
(1)
Commonly used procedures, such as the Benjamini–Hochberg procedure25, achieve FDR control by working with p values computed against some null hypothesis. In the interaction discovery setting, for each feature interaction, one tests the significance of the statistical association between the specific interaction and the response, either jointly or marginally, and obtains a p value under the null hypothesis that the interaction is irrelevant. These p values are then used to rank the features for FDR control. However, controlling FDR in generic ML models, especially deep learning models, is challenging because, to our knowledge, the field lacks a method for producing meaningful p values that reflect interaction importance. To bypass the use of p values but still achieve FDR control, we draw inspiration from the model-X knockoffs framework26,27. The core idea of knockoffs is to generate dummy features that perfectly mimic the empirical dependence structure among the original features but are conditionally independent of the response given the original features. These knockoff features can then be used as a control by comparing the feature importance between the original features and their knockoff counterparts to estimate the FDR (Fig. 1a).
Diamond trains a generic ML model that takes as input an augmented data matrix \(({\bf{X}},\tilde{{\bf{X}}})\in {{\mathbb{R}}}^{n\times 2p}\), created by concatenating the data matrix \({\bf{X}}\in {{\mathbb{R}}}^{n\times p}\) with its knockoffs \(\tilde{{\bf{X}}}\in {{\mathbb{R}}}^{n\times p}\) along the feature axis. After training, Diamond quantifies the feature interactions by interpreting the trained model and produces a ranked list of these interactions (Fig. 1b). However, existing feature importance measures cannot directly capture non-additive interactions. Geometrically, the marginal or interaction importance reported by current interpretation methods correspond to the projection of the total contribution to the prediction onto a one-dimensional feature axis or a two-dimensional feature–feature plane. Non-additive effects, however, represent the difference between the interaction effects and the marginal effects (Fig. 1c). Hence, Diamond distils non-additive interaction effects from the reported interaction importance measures from existing methods, thereby maintaining FDR control at the target level. The distillation process is designed to remove both label-dependent marginal effects and label-independent feature biases from the reported feature interactions, leaving only the label-dependent non-additive interaction effects (Fig. 1d).
Diamond discovers FDR-controlled interactions on simulated datasets
We started by evaluating the performance of Diamond on simulated datasets, assessing its ability to identify important non-additive interactions and controlling the FDR. We benchmarked Diamond on a test suite of ten simulated datasets generated by different simulation functions proposed in ref. 10. These datasets contain a mixture of univariate functions and multivariate interactions, exhibiting varied order, strength and nonlinearity (Fig. 2a). Since our goal is to detect pairwise interactions, high-order interaction functions (for example, F(x1, x2, x3) = x1x2x3) are decomposed into pairwise interactions (for example, (x1, x2), (x1, x3), and (x2, x3)) to serve as the ground truth.

a, Evaluation based on a test suite of ten data-generating simulation functions proposed in ref. 10. b, Reported interaction importance from existing methods in simulation function F1 reveals a clear distribution disparity between original-only interactions and those involving knockoffs. The distilled non-additive interactions help mitigate distributional disparities. c, Baseline methods fail to correctly control the FDR, thereby rendering the reported high power and AUROC invalid. d, Diamond identifies important non-additive interactions with controlled FDR, compatible with various ML models. The non-additivity distillation procedure is critical; without it, the FDR cannot be controlled. To ensure robustness, we repeated each experiment 20 times with different random seeds and reported the mean performance with 95% confidence intervals.
Following the settings used in ref. 10, we used a sample size of n = 20,000, equally divided into training and test sets. In addition, the number of features is set at p = 30, and all features are sampled randomly from a continuous uniform distribution, U(0, 1). Only the first 10 out of 30 features contribute to the corresponding response, whereas the remaining features serve as noise to increase the task’s complexity. For robustness, we repeated the experiment 20 times for each simulated dataset using different random seeds. Each repetition involved data generation, knockoff generation using KnockoffsDiagnostics31, ML model training and interaction-wise FDR estimation. For all simulation settings, we reported the mean performance with 95% confidence intervals, fixing the target FDR level at q = 0.2.
Our analysis shows that Diamond consistently identifies important non-additive interactions with controlled FDR across all ML models (Fig. 2d). Under controlled FDR, the multilayer perceptron (MLP) and feature tokenizer transformer (FT-Transformer) models29 demonstrate better performance in identifying important interactions than other ML models, as measured by the statistical power and the area under the receiver operating characteristic curve (AUROC). This superior performance is attributed to the inclusion of a knockoff-tailored plug-in pairwise-coupling layer design32, which has been shown to maximize statistical power (Supplementary Section 1). It is important to note that certain ML models, such as convolutional neural networks, are not well suited for modelling tabular data due to their design for capturing local patterns in images or text. Even in the presence of model misspecification, Diamond maintains FDR control, although with a loss of power. This highlights Diamond’s robustness and its broad applicability across various ML models.
We discovered that the proposed non-additivity distillation (see the ‘Measuring the non-additive interaction effect’ section) is critical; without it, the FDR cannot be controlled by naively using reported interaction importance values from existing methods (Fig. 2d and Supplementary Fig. 2). To gain insights into the FDR control failure in the absence of non-additivity distillation, we conducted a qualitative comparison assessing the interaction importance before and after distillation using the simulation function F1 (Fig. 2b and Supplementary Fig. 3). The primary cause of the FDR control failure appears to lie in the distributional disparity between original-only interactions (that is, interactions involving two features from the original feature set rather than knockoffs) and interactions involving knockoffs. This observation suggests a violation of the knockoff filter’s assumption in controlling the FDR (see the ‘Measuring the non-additive interaction effect’ section). The proposed non-additivity distillation procedure mitigates the disparity by extracting non-additive interaction effects from the reported interaction importance measures, thereby enhancing the utility of knockoff-involving interactions as a negative control for FDR estimation.
Finally, we verified whether alternative baseline methods can accurately identify important non-additive interactions with controlled FDR (Fig. 2c). We compared three baseline methods for FDR estimation: two relying on permutation-based interaction-wise p values, combined with the Benjamini–Hochberg and Benjamini–Yekutieli procedures, and one that represents interaction-wise FDR as an aggregation of feature-wise FDR (see the ‘Alternative FDR estimation methods’ section). Our analysis reveals that none of these baseline methods effectively control the FDR. This greatly reduces the utility of these methods, despite their reported high power and AUROC.
Diamond finds FDR-controlled interactions in simulations
The design of Diamond incorporates several key components, including knockoff generation and interaction importance measures. To demonstrate the robustness of Diamond in FDR control, we conducted a control study in which we modified Diamond by replacing these two components with alternative solutions. Specifically, we considered two variants of Diamond using the MLP model. In the first setting, we replaced KnockoffsDiagnostics with three alternatives: KnockoffGAN33, Deep knockoffs34 or VAE knockoffs35, and we kept the MLP model and the interaction importance measure (that is, Expected Hessian36) unchanged. In the second setting, we replaced the interaction importance measure, Expected Hessian, with two alternatives: Integrated Hessian16 and a model-specific interaction importance measure derived from the MLP weights (Supplementary Section 2), and we kept the MLP model and the knockoff generation unchanged. For each variant, we applied Diamond to the test suite of ten simulated datasets using the same settings.
The results indicate that Diamond is robust to various knockoff designs and importance measures. In the first study, our analysis shows that Diamond consistently discovers important non-additive interactions with controlled FDR across various knockoff designs (Fig. 3a). Despite the methodological differences in knockoff generation between KnockoffsDiagnostics, KnockoffGAN, Deep knockoffs and VAE knockoffs, Diamond achieves comparable statistical power and AUROC in each case. This result demonstrates the Diamond’s stability in identifying important interactions in knockoff-based FDR estimation. Furthermore, it is worth noting that Diamond is robust even when the knockoffs are poorly generated. Specifically, we generated invalid knockoffs by independently permuting each feature across samples, thereby violating the definition of knockoffs outlined in the ‘FDR control with knockoffs’ section. Our analysis demonstrates that even in this extreme scenario, Diamond maintains FDR control, although with reduced power (Fig. 3b).

a, Diamond demonstrates robustness across knockoffs generated by various methods, including KnockoffsDiagnostics, KnockoffGAN, Deep knockoffs and VAE knockoffs. b, Diamond maintains FDR control when paired with invalid knockoffs, generated by independently permuting each feature across samples, although at the cost of reduced power. c, Diamond demonstrates robustness across methodologically different interaction importance measures: Expected Hessian, Integrated Hessian and model-specific measures. To ensure robustness, we repeated each experiment 20 times with different random seeds and reported the mean performance with 95% confidence intervals.
In the second study, our analysis shows that Diamond robustly identifies FDR-controlled non-additive interactions across a range of interaction importance measures (Fig. 3c). Despite the methodological differences between Expected Hessian, Integrated Hessian and model-specific measures, which involve mechanistic disparities in elucidating the relationships between features and responses, Diamond achieves valid FDR control and maintains reasonably good statistical power and AUROC. This result demonstrates Diamond’s flexibility in identifying interactions based on various importance measures.
Finally, it is worth mentioning that regardless of the knockoff generation and interaction importance measures we used, there is room for improvement in achieving better statistical power and maintaining controlled FDR. Diamond tends to be conservative by overestimating the FDR, suggesting that an improved FDR control procedure could potentially boost statistical power.
Diamond finds interactions explaining disease progression
We then evaluated the performance of Diamond on a real dataset37, assessing its ability to identify important interactions in the progression of disease. We used a quantitative study with n = 442 diabetes patients, each characterized by ten standardized baseline features, including age, sex, BMI, average blood pressure and six blood serum measurements (Fig. 4a). The task is to construct an ML model to predict the response of interest, which is a quantitative measure of disease progression one year after the baseline. We considered different types of ML model: MLP, FT-Transformer, KAN, LightGBM, XGBoost and factorization machines (FMs). We assessed the trained ML model using fivefold cross-validation and selected the one with the best performance for model interpretation and interaction discovery. For robustness, we repeated each experiment 20 times using different random seeds. Each repetition involved knockoff generation, ML model training and interaction-wise FDR estimation.

a, Each feature contributes differently to predicting disease progression, as measured by the Expected Gradient scores in the MLP model. b, Diamond is compared against three baseline methods. The blue stars indicate interactions supported by literature evidence, referenced by the accompanying PubMed identifiers. c, Diamond is used with various ML models to identify important non-additive interactions. Each possible interaction is measured by the minimum FDR threshold cut-off at which it is selected, with the top interaction annotated. d, Top interaction, between BMI and STL, is qualitatively evaluated from three aspects: the marginal importance measure, the interaction importance measure and the contribution of the marginal importance measures to the interaction importance measure.
Our analysis shows that Diamond identifies the important interaction between BMI and serum triglyceride level (STL) across three different ML models (Fig. 4c). We investigated the identified interaction via literature search and found that high BMI and high STL are associated with an increased risk of diabetes, as reported by multiple studies38,39,40. The literature evidence is further supported by qualitative evaluation (Fig. 4d). Specifically, we examined the identified interactions from three perspectives: the marginal importance measure, the interaction importance measure and the contribution of the marginal importance measures to the interaction importance measure. This analysis showed that high BMI and high STL contribute to more severe progression of diabetes. Meanwhile, higher STL further synergistically reinforces the contribution of BMI to the progression of diabetes.
Unlike other ML models, FT-Transformer identifies two distinct interactions: the interaction between blood pressure and high-density lipoproteins, and the interaction between age and sex. We investigated the identified interactions through a literature search and found that high-density lipoprotein levels are positively associated with hypertension in individuals with elevated levels of circulating CD34-positive cells41. We also found that the prevalence of diabetes varies by sex, with men typically being diagnosed at a younger age and lower BMI, whereas young women with diabetes are currently less likely than men to receive treatment42.
Finally, we find that Diamond does not necessarily report a lower FDR for interactions composed of two marginally important features. All ten baseline features from diabetes patients are effective in predicting disease progression, as measured by the Expected Gradient scores in the MLP model (Fig. 4a). Among these features, in addition to BMI and STL, blood pressure, blood sugar level and high-density lipoproteins are more predictive than others. It is important to note that Diamond still associates most interactions composed of these highly predictive features with a high FDR threshold.
Diamond probes enhancer activity in Drosophila embryos
We then evaluated the performance of Diamond on a Drosophila enhancer dataset43 to investigate the relationship between enhancer activity and DNA occupancy for transcription factor (TF) binding and histone modifications in Drosophila embryos. We used a quantitative study of DNA occupancy for 23 TFs and 13 histone modifications with the enhancer status labelled for 7,809 genomic sequence samples from blastoderm Drosophila embryos (Fig. 4a). The enhancer status for each sequence is binarized as the response, depending on whether the sequence drives patterned expression in blastoderm embryos. To predict the enhancer status, the maximum value of normalized fold enrichment44 of ChIP-seq and ChIP-chip assays for each TF or histone modification served as our features. We considered different types of ML model: MLP, FT-Transformer, KAN, LightGBM, XGBoost and FM. We assessed the trained ML model using fivefold cross-validation and selected the one with the best performance for model interpretation and interaction discovery. For robustness, we repeated the experiment 20 times using different random seeds. Each repetition involved knockoff generation, ML model training and interaction-wise FDR estimation.
We started by comparing the identified interactions against a list of well-characterized physical interactions in the early Drosophila embryos, collected in ref. 43. These interactions have been identified over decades and have been confirmed to play a critical role in regulating spatial and temporal patterning45. If Diamond is successful in identifying important interactions and controlling the FDR, then the identified interactions should considerably overlap with these previously reported physical interactions. Meanwhile, it is important to acknowledge that this list of interactions, proposed years ago, represents only a partial set of true interactions. Therefore, a detected interaction not appearing in the list does not necessarily indicate it is incorrect. Our results show that three of the top five interactions reported by Diamond are included in the ground-truth list for MLP and tree-based models, four out of five for FM, and all five for FT-Transformer (Fig. 5c). The only exception is KAN, which reported all but one interaction at the same FDR levels. In comparison, the baseline methods exhibit significantly different behaviours (Fig. 5b). Two baseline methods, which are based on permutation-based interaction-wise p values combined with the Benjamini–Hochberg and Benjamini–Yekutieli procedures, reported no ground-truth interactions among its top five identifications. Another method, which aggregates feature-wise FDR, reported ground-truth interactions along with a large number of non-ground-truth interactions.

a, Each feature contributes differently to predicting enhancer status, as measured by the Expected Gradient scores in the MLP model. b, Diamond is compared against three baseline methods. The annotated TFs are labelled by their UniProt identifiers. The red stars indicate well-characterized physical interactions in early Drosophila embryos as ground truth. The blue stars indicate interactions supported by literature evidence, referenced by the accompanying PubMed identifiers. c, Diamond is used with various ML models to identify important non-additive interactions. Each possible interaction is measured by the minimum FDR threshold cut-off at which it is selected, with the top five interactions annotated. The top interactions reported by the MLP model are qualitatively evaluated from three aspects: the contribution of feature values to the marginal (d) and interaction (e) importance measures, and the contribution of the marginal importance measures to the interaction importance measure (f).
Next, we investigated the identified interactions that are not included in the ground-truth list. For example, we investigated the interaction between the TFs Snail (UniProt ID: P08044) and Twist (UniProt ID: P10627) identified by Diamond+MLP through databases containing assorted experimentally verified interactions46 and literature47. Research indicates that Snail represses Twist targets because their target sequences are very similar, and their binding is mutually exclusive. This literature evidence is further supported by a qualitative evaluation (Fig. 5d–f and Supplementary Figs. 4–6). Specifically, we examined the Snail–Twist interaction in terms of the contribution of feature values to the enhancer status prediction, observing that high Twist expression suppresses the contribution of Snail to enhancer activation.
Furthermore, we investigated the remaining identifications that lack supporting ground-truth or literature evidence. We discovered that these interactions can be logically explained through transitive effects. Specifically, even without a direct interaction between TF1 and TF3, we might still expect a strong interaction between them if solid interactions exist between TF1 and TF2 and between TF2 and TF3. On this basis, for example, the interaction between the TFs Twist (UniProt ID: P10627) and Zeste (UniProt ID: P09956), identified by Diamond+MLP, can be classified as a transitive interaction, supported by experimentally validated interactions48: (1) the interaction between Twist and Ultrabithorax (UniProt ID: P83949), Decapentaplegic (UniProt ID: P07713), Pho (UniProt ID: Q8ST83), Raf (UniProt ID: P11346), Psc (UniProt ID: P35820) and Trr (UniProt ID: Q8IRW8); and (2) the interaction between these proteins and Zeste. Analogously, the interaction between the TFs Twist (UniProt ID: P10627) and Dichaete (UniProt ID: Q24533), identified by Diamond together with two tree-based models, can also be supported by transitive interactions48: (1) the interaction between Twist and Pho, Raf, Psc, Trr, Myc (UniProt ID: Q9W4S7) and Trx (UniProt ID: P20659); and (2) the interaction between these proteins and Dichaete.
Finally, Diamond is able to identify non-additive interactions with various interactive patterns (Fig. 5d–f). Among the top five interactions reported by Diamond with MLP, the Zelda–Twist interaction, the Bicoid–Twist interaction and the Krueppel–Twist interaction exhibit synergistic effects. The high expression of both TFs in these interactions reinforces the contribution of each individual factor to enhancer activation. By contrast, the Snail–Twist interaction, which was mentioned earlier, exhibits repressive effects, where high expression of one TF suppresses the contribution of the other to enhancer activation. Last, the Twist–Zeste interaction exhibits alternative effects, where the high expression of either TF enhances the contribution of each to enhancer activation.
Diamond reveals drivers of health-related mortality
Last, we evaluated the performance of Diamond on a real mortality risk dataset49 to investigate the relationship between mortality risk factors and long-term health outcomes within the US population. We used a mortality dataset from the National Health and Nutrition Examination Survey (NHANES I) and NHANES I Epidemiologic Follow-up Study (NHEFS). The dataset incorporates 35 clinical and laboratory measurements from 14,407 US participants between 1971 and 1974 (Fig. 6a). Note that some of the features are presented categorically, which makes model’s trained from these data challenging to interpret. We addressed this problem by converting each categorical feature into a list of binary features using one-hot encoding. The dataset also reports the mortality status of participants as of 1992, with 4,785 individuals known to have passed away before 1992. The task is to construct an MLP-based model to predict the mortality status using a survival loss function. We assessed the trained model using fivefold cross-validation and selected the one with the best performance for model interpretation and interaction discovery. For robustness, we repeated the experiment 20 times using different random seeds. Each repetition involved knockoff generation, ML model training and interaction-wise FDR estimation.

a, Each feature contributes differently to predicting the mortality status, as measured by the Expected Gradient scores. It is worth mentioning that two marginally important features do not necessarily result in important interactions, as anticipated in Diamond’s design. b, Diamond is used with the MLP model to identify important non-additive interactions and is compared against other baseline methods. Each possible interaction is measured by the minimum FDR threshold cut-off at which it is selected, with the top five interactions annotated. The blue stars indicate interactions supported by literature evidence, referenced by the accompanying PubMed identifiers. The survival loss function for predicting mortality restricts the modelling to DNNs, and we use MLP specifically due to memory limitations with other DNN models. The top interactions reported by Diamond are qualitatively evaluated from three aspects: the contribution of feature values to the marginal (c) and interaction (d) importance measures, and the contribution of the marginal importance measures to the interaction importance measure (e).
Given the absence of ground-truth interactions for this task, we began by evaluating the interactions identified by Diamond through literature support. Our analysis shows that three of the top ten selected interactions are directly supported by existing literature (Fig. 6b). For example, we investigated the interaction between sex and sedimentation rate (SR) and found that although a high SR is strongly associated with a higher risk of overall mortality, this association can be attenuated by sex50. Additionally, we investigated the interaction between creatinine and the blood urea nitrogen (BUN) identified by Diamond. Research indicates that the BUN/creatinine ratio is recognized to have a nonlinear association with all-cause mortality and a linear association with cancer mortality51. The literature evidence is further supported by qualitative evaluation (Fig. 6c–e). Specifically, we examined the BUN–creatinine interaction in terms of the contribution of feature values to mortality status prediction, observing that when the creatinine level exceeds a certain level, a high BUN level further increases the mortality risk. By contrast, the baseline methods display significantly different behaviour, reporting an overwhelming number of interactions at the significant FDR level, which appears to overestimate false positives.
Finally, we probed into the remaining identifications that lack supporting literature evidence. As in the Drosophila analysis, we discovered that these interactions can be logically explained through transitive effects. For example, the interaction between BUN and potassium can be justified by combining the following two established facts: (1) BUN level is indicative of chronic kidney disease development52, and (2) patients with chronic kidney diseases show a progressively increasing mortality rate with abnormal potassium levels53. Additionally, the interaction between BUN and SR reflects the fact that (1) the creatinine level and SR are strongly associated to clinical pathology types and prognosis of patients54, and (2) creatinine and BUN have a nonlinear association51.


