As LLMs become increasingly essential for various AI tasks, their huge parameter sizes lead to high memory requirements and bandwidth consumption. Quantization-aware training (QAT) offers a potential solution by allowing models to operate with low-bit representations, but existing methods often require large training resources, making them impractical for large models. In this research paper, we address the challenge of managing the large memory requirements of large language models (LLMs) in natural language processing and artificial intelligence.
Current quantization techniques for LLM include Post-Training Quantization (PTQ) and Quantization Parameter Efficient Fine-tuning (Q-PEFT). PTQ minimizes memory usage during inference by converting pre-trained model weights to a lower-bit format, but can result in reduced accuracy, especially in the low-bit domain. Q-PEFT methods such as QLoRA allow fine-tuning on consumer-grade GPUs, but can result in reduced performance due to the need to convert back to a higher-bit format for additional tuning and then run PTQ again.
To address these limitations, researchers propose Efficient Quantization-Aware Training (EfficientQAT). The EfficientQAT framework operates in two main phases. In the Block-AP phase, quantization-aware training is performed on all parameters in each transformer block, leveraging block-wise reconstruction to maintain efficiency. This approach avoids the need for full model training and saves memory resources. Then, in the E2E-QP phase, the quantized weights are fixed and only the quantization parameters (step size) are trained. This improves model efficiency and performance without the overhead associated with training the entire model. This dual-phase strategy improves convergence speed and enables effective order tuning of quantized models.

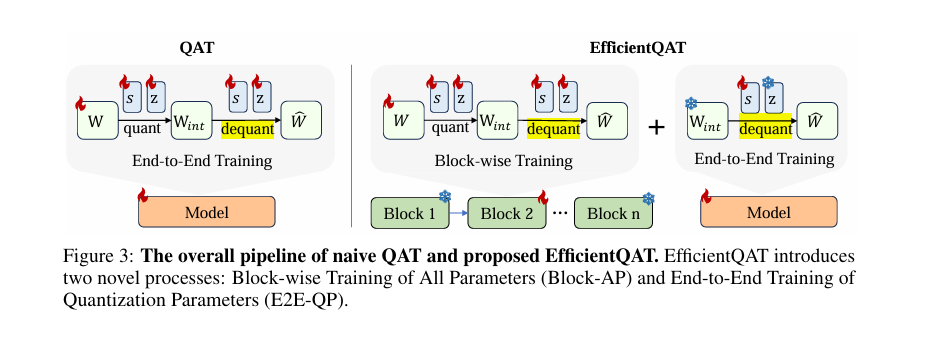
The Block-AP phase of EfficientQAT starts with a standard uniform quantization method, then quantizes and dequantizes the weights block-wise. Inspired by BRECQ and OmniQuant, this method requires less data and memory and allows for more efficient training compared to traditional end-to-end QAT approaches. By training all parameters, including scaling coefficients and zero points, Block-AP ensures accurate calibration and avoids the overfitting issues that typically occur when training the entire model simultaneously.
In the E2E-QP phase, only the quantization parameters are trained end-to-end while keeping the quantization weights fixed. This phase leverages the robust initialization provided by Block-AP to efficiently and accurately tune the quantization model for a specific task. E2E-QP enables imperative tuning of the quantization model and ensures memory efficiency as the trainable parameters only occupy a small fraction of the entire network.
EfficientQAT demonstrates significant improvements over traditional quantization methods. For example, it achieves 2-bit quantization of the Llama-2-70B model in just 41 hours on a single A100-80GB GPU, with less than 3% accuracy loss compared to the full-precision model. Furthermore, it outperforms existing Q-PEFT methods in low-bit scenarios, providing a more hardware-efficient solution.
The EfficientQAT framework offers a compelling solution to the challenges posed by large-scale language models in terms of memory and computational efficiency. By introducing a two-stage training approach that focuses on block-wise training and end-to-end quantization parameter optimization, researchers effectively reduce the resource requirements of quantization-aware training while maintaining high performance. This method represents a major advancement in the field of model quantization and provides a practical way to deploy large-scale language models in resource-constrained environments.
Please check Papers and GitHub. All credit for this research goes to the researchers of this project. Also, don't forget to follow us. twitter.
participate Telegram Channel and LinkedIn GroupsUp.
If you like our work, you will love our Newsletter..
Please join us 46k+ ML Subreddit


Shreya Maji is a Consulting Intern at MarktechPost. She did her B.Tech from Indian Institute of Technology (IIT), Bhubaneswar. An AI enthusiast, she enjoys staying updated with the latest advancements. Shreya is particularly interested in practical applications of cutting edge technologies, especially in the field of Data Science.