
This section details the methodology employed to diagnose depression from audio data.
Mel Frequency Cepstral Coefficient
Mel Frequency Cepstral Coefficient (MFCCS)twenty three It is widely used in audio processing and feature extraction. The coefficients represent the short-term power spectrum of an acoustic signal. This is the result of the linear cosine transformation of the logarithmic power spectrum calculated on a nonlinear MEL frequency scale. MFCCS works as follows: The audio signal is segmented into overlapping frames to accurately represent the temporal dynamics of the audio. The Fourier transform is applied to each frame to convert the time domain signal into the frequency domain. Next, power spectral mapping to the MEL scale is performed via a filter bank. The MEL scale approximates the response of the human ear more closely than the linear frequency axis. The power of each Mel frequency is logarithmically transformed to model loudness perceptions of human auditory systems. Discrete cosine transform (DCT) is applied to the Logmer spectrum, which decorrelates coefficients and reduces dimensions. The MFCC is the coefficient obtained after this step, showing the steps shown in Figure 1. MFCC is essential for speech recognition applications and speaker identification.
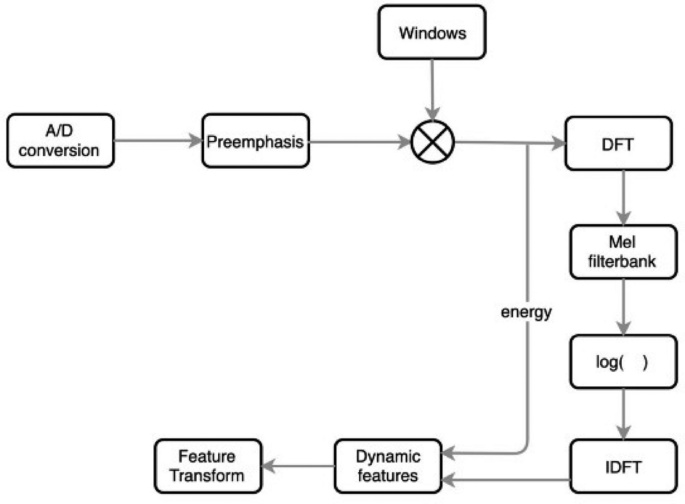
Mel Frequency Cepstral Coefficient Frameworktwenty four.
dragonfly algorithm
Dragonfly Algorithm (DA)twenty five is a naturally inspired metaheuristic optimization technique conceptualized based on static and dynamic group behavior of dragonflies. Therefore, it is highly efficient to solve complex optimization problems such as feature selection in dimension reduction, and a subset of features that best represent the original dataset has been selected. DA allows for manifold reductions that reduce feature dimensions and holds all the critical information for further use with continuous machine learning models, with high efficiency and improved performance.
The DA algorithm works in the following phases
Initialization: The algorithm initializes a population of randomly arranged dragonflies at random speeds in the search space.
Dragonfly herds exhibit two main types of behavior: static exploration and dynamic exploitation. Exploration expands to search for global optimals, while exploitation concentrates searches in the most promising areas.
Objective Function: The suitability of each dragonfly is evaluated using an objective function that, with dimension reductions, can usually be a minimization problem associated with reconstruction errors, or a maximization problem associated with the variance described.
Update position: The dragon changes position according to five influencers – dispersion (steering to avoid collisions with other dragonflies), alignment (adjusting speed with adjacent dragonflies), aggregation (moving to the center of the cluster), attraction to food, distraction from predators.
It is mathematically expressed by equation (1).
$$\begin{aligned}\textbf{x}_{new}=\textbf{x}_{old}+\alpha\cdot\textbf{r}+\beta\cdot\varvec{\delta}\end{aligned}$$$
(1)
where \(\ textbf {x} _{old} \) and \(\ textbf {x} _ {new} \) The old and new positions of dragonflies, respectively. \(\ textbf {r} \) It's a random vector \(\varvec {\delta} \) A vector of differences between two randomly selected Dragovs. here \(\varvec {\alpha}\) Represents the effect of a random vector \(\ textbf {r} \) Controls the degree of randomness in dragonfly movement. \(\ varvec {\ beta} \) Represents the effect of the difference vector \(\varvec {\delta} \)controls how much the movement of dragonflies is affected by the relative position of other dragonflies.
Iteration: This involves applying the procedure iteratively until several convergence criteria are met, such as maximum number of iterations and fitness level satisfaction.

Firefly Algorithm
Firefly Algorithm (FA)26 It is one of the optimization techniques that draws inspiration from the flashing fireflies action. This technique is primarily effective in solving complex optimization problems and in selecting features to reduce dimensions. Dimensional reduction using the Firefly algorithm may be performed without loss of important information. This could improve the efficiency and effectiveness of further machine learning models.
The FA algorithm works in the following phases
Charm: The charm of fireflies is influenced by their brightness. This correlates with the objective function. Brighter fireflies attract others, but the level of attraction decreases as distance increases.
Movement: One Firefly \((I)\) Fascinated by fireflies in flight \((j)\) The ones of the higher intensity flash that move towards it are mathematically defined
$$\begin {aligned} x_i = x_i +\beta(x_j -x_i) +\alpha(\rho -0.5)\end {aligned} $$
(2)
where \(x_i \) and \(x_j \) The fireflies' position \(I\) and \(j \), \(\beta\) It's an attractive parameter and determines how strong it will become \(x_i \) I'm attracted to \(x_j \), \(\alpha\) Randomization parameters \(\ rho \) Random numbers between 0 and 1.

Moth Flame Optimization Algorithm
moth-flame optimization (MFO)27 It probably represents the proposed method and draws inspiration from the navigation mechanisms moth put into practice. Therefore, it is possible to infer metaheuristic optimization techniques that promise to handle complex optimization problems.
The MFO algorithm works in the following phases:
Moth and Flame Representation: MFO represents a solution as MOTH, and induced flames of MOTH are potential solutions. Each moth is attracted to the flame and simulates a moth navigating towards the light.
Update position: All Moths update their positions for all flames, and all Moths move towards the flames. Mathematically, the motion of moth can be expressed by the following logarithmic helix equation:
$$\begin{aligned} x_i(t+1)=d_i\cdot e^{b\cdot t}\cdot\cos(2\pit)+f_j\end{aligned} $$
(3)
That means it here \(x_i(t+1)\) This is the location of moth, \(d_i \) Distance between Moth and Flame, b A constant that defines a shape from a logarithmic spiral, t Random variable of range \([-1, 1]\)and \(f_j \) The location of the flame.
Flame Update: This reduces the number of flames in all iterations, and balances exploitation and exploitation.
Therefore, starting with a large number of flames to explore the search space, further steps reduce the number of flames in the exploitation stage.

Moth Flame Optimization Algorithm
System Architecture
As shown in Figure 2, the proposed system architecture starts with feature extraction via MFCC and captures important features of audio. Features selection is optimized using Swarm Intelligence Techniques, which improves performance and reduces dimensions. The architecture consists of three 1D convolutional layers with increasing filter size, followed by a maximum pool and dropout for regularization. Batch normalization is used to stabilize the learning process. Global average pooling reduces the dimensions further before feeding data into two LSTM layers designed for sequence learning. Finally, a high density layer is employed for the binary classification task.

The proposed system architecture.
Convolutional layer
Convolutional layer28 CNNS performs convolution operations. The filter slides over the input data to detect the functionality. Each filter generates a functional map by applying element-by-element multiplication and summing the results. The Stride controls the movement of the filter, and the padding preserves the spatial dimensions. So, you usually add nonlinearity via the relu activation function. This is an important layer in extracting hierarchical features from input data used for image classification, object detection, and segmentation. In this way, by learning spatial hierarchies, the convolutional layer enhances the ability of the model to discover complex patterns and structures from the data.
Maximum pooling layer
Max Pooling28 It involves sliding the window over the input function map and taking the maximum value from each window. Reduces feature map size and reduces calculations and reduces overfitting. This holds the most dominant features, making the network more sensitive to storing spatial hierarchies and recognizing the patterns and structure of data. This is very important for image classification, object detection, and more.
Dropout Layer
Dropout28 It involves setting a random percentage of neuronal output to zero in each training iteration. The effect is that the network learns redundant representations because it cannot depend on a single neuron. In doing so, dropouts improve the generalizability and robustness of the model. Typically, you specify the dropout rate. This shows how large some of the dropped neurons are. This technique works very well, especially in deep networks. This is to prevent overfitting on invisible data and improve performance.
Long term memory
Long-term memory (LSTM)29 The network represents a special variation of RNNs, avoiding the problem of annihilation of naturally occurring gradients in traditional RNNs. This is because the model loses its ability to learn efficiently as the gradient used during training becomes very small. This is resolved by LSTM, which maintains long-term dependencies of data sequences thanks to the architecture. Three gates – the input gate, the output gate, the forgotten gate and the cell make up the LSTM unit. The gates cause information flows to and from the cell, but the cell must hold the value for a very long time. As a result, this structure allows LSTM to eliminate unrelated information and hold important information for a very long time. LSTM has proven to be extremely useful for jobs that require continuous data, such as time series prediction, machine translation, and speech recognition. It is also used in many other fields such as healthcare, robotics control, and handwriting recognition.


