Model selection is critical to solving real-world data science problems. Tree ensemble models such as XGBoost have traditionally been preferred for classification and regression on tabular data. Despite their success, deep learning models have emerged recently, claiming to perform better on specific tabular datasets. Deep neural networks excel in areas such as image, speech, and text processing, but their application to tabular data presents challenges including data sparsity, mixed feature types, and lack of transparency. New deep learning approaches for tabular data have been proposed, but inconsistent benchmarking and evaluations make it unclear whether they are actually superior to established models such as XGBoost.
Researchers from Intel's IT AI group conducted a rigorous comparison of deep learning models and XGBoost on tabular data to determine their effectiveness. After evaluating performance on a variety of datasets, they found that XGBoost consistently outperformed deep learning models, even on datasets that were used to initially introduce deep learning models. Additionally, XGBoost required significantly less hyperparameter tuning. However, combining deep models and XGBoost in an ensemble produced the best results, outperforming both standalone XGBoost and deep models. This study highlights that despite advances in deep learning, XGBoost remains a good and efficient choice for tabular data problems.
Traditionally, gradient boosting decision trees (GBDTs), such as XGBoost, LightGBM, and CatBoost, have dominated tabular data applications due to their excellent performance. However, recent research has introduced deep learning models tailored for tabular data, such as TabNet, NODE, DNF-Net, and 1D-CNN, which are expected to outperform traditional methods. These models include differentiable trees and attention-based approaches, but GBDTs remain competitive. Ensemble learning, which combines multiple models, can further improve performance. Researchers have evaluated these deep models and GBDTs on various datasets and found that while XGBoost generally outperforms, combining deep models with XGBoost produces the best results.
The study thoroughly compared deep learning models against traditional algorithms such as XGBoost on 11 different tabular datasets. Deep learning models investigated included NODE, DNF-Net, and TabNet, which were evaluated side-by-side with XGBoost and ensemble approaches. These datasets, selected from prominent repositories and Kaggle competitions, exhibited a wide range of characteristics in terms of features, classes, and sample sizes. Evaluation criteria included accuracy, training and inference efficiency, and time required to tune hyperparameters. Findings revealed that XGBoost consistently outperformed deep learning models on most datasets that were not included in the original training set of the model. Specifically, XGBoost achieved superior performance on 8 of the 11 datasets, demonstrating its versatility across different domains. Conversely, deep learning models performed best only on the datasets for which they were originally designed, suggesting that they tend to overfit on their initial training data.
Additionally, the study also explored the effectiveness of combining deep learning models with XGBoost in an ensemble method. We observed that ensembles integrating both deep models and XGBoost often yielded superior results compared to individual models and ensembles of traditional machine learning models such as SVM and CatBoost. This synergy highlights the complementary strengths of deep learning and tree-based models, with deep networks capturing complex patterns and XGBoost providing robust and generalized performance. Despite the computational advantages of deep models, XGBoost proved significantly faster and more efficient in optimizing hyperparameters, converging to optimal performance with fewer iterations and fewer computational resources. Overall, the findings highlight the need for careful consideration of model selection and the benefits of combining different algorithmic approaches to leverage their unique strengths for different tabular data challenges.

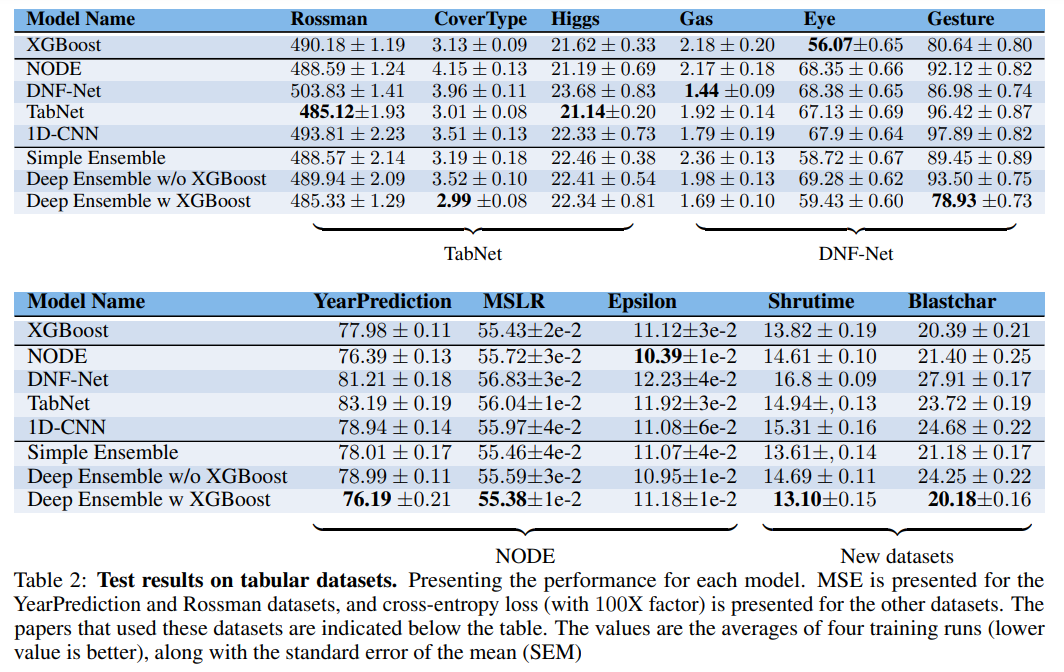
This study evaluated the performance of deep learning models on tabular datasets and found that they generally performed less well than XGBoost on datasets outside of the original paper. Ensembles of deep models and XGBoost performed better than single models and traditional ensembles, highlighting the strength of combining techniques. XGBoost is easy to optimize and efficient, making it the preferred choice in time-constrained environments; however, integrating a deep model could improve performance. Future research should test models on diverse datasets and focus on developing deep models that are easier to optimize and more competitive with XGBoost.
Please check paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us. twitter.
participate Telegram Channel and LinkedIn GroupsUp.
If you like our work, you will love our Newsletter..
Please join us 46k+ ML Subreddits


Sana Hassan, a Consulting Intern at Marktechpost and a dual degree student at Indian Institute of Technology Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, she brings a fresh perspective to the intersection of AI and real-world solutions.