
During the opening session of the 2024 Computer Vision and Pattern Recognition (CVPR) Conference, the CVPR Awards Committee announced the winners of the prestigious Best Paper Awards, which annually recognize outstanding research in areas such as computer vision, artificial intelligence (AI), machine learning (ML), augmented reality, virtual reality, and mixed reality (AR/VR/MR), and deep learning.
This year, from among more than 11,500 paper submissions, the CVPR 2024 Awards Committee selected the following recipients for “Best Paper” honors during the awards program at CVPR 2024, running now through June 21 at the Seattle Convention Center. The top two recipients are:
Outstanding Papers
● Generative Image Dynamics
Authors: Zhengqi Li, Richard Tucker, Noah Snavely, Aleksander Holynski (link)
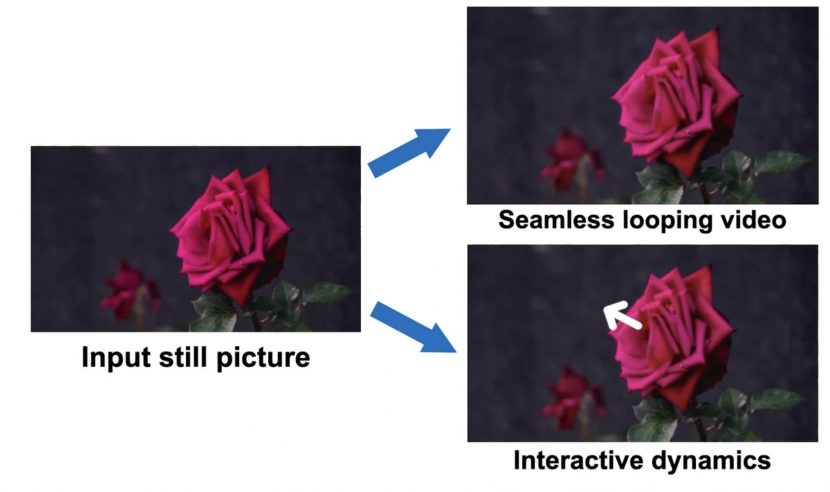
In this paper, we present a new approach to model the dynamics of natural vibrations from a single still image, which produces a photorealistic animation from the image. Check out the interactive demo here – give it a trySimply put, you can click and drag on an image to move objects in the image, and they will return to their original position, as if you had touched the real object. In other words, this is fun to play with and could be a great way to bring images to life with compelling interactive experiences. It also shows the potential to enable several downstream applications, such as seamless looping and creating interactive image dynamics. Now imagine this at scale in a fully interactive, immersive Apple Vision Pro high-resolution environment built from real-world photographs. The effect would be astounding; it would bring panoramas and environments to life.
● Rich human feedback for text-to-image generation
Authors: Youwei Liang, Junfeng He, Gang Li, Peizhao Li, Arseniy Klimovskiy, Nicholas Carolan, Jiao Sun, Jordi Pont-Tuset, Sarah Young, Feng Yang, Junjie Ke, Krishnamurthy Dj Dvijotham, Katherine M. Collins, Yiwen Luo, Yang Li, Kai J. Kohlhoff, Deepak Ramachandran, Vidhya Navalpakkam

This paper focuses on the first rich human feedback dataset for image generation. The authors designed and trained a multimodal transformer to predict rich human feedback and demonstrated several instances to improve image generation. Text-to-image generative AI models such as Stable Diffusion and Imagen have made great progress in generating high-resolution images based on text descriptions. However, many of the generated images still suffer from issues such as artifacts/unnaturalness, inconsistency with the text description, and therefore low quality. Supervised learning is key to ML, and there is a great need to have more and better labeled data.
Link to the paper here
CVPR is the premier computer vision event for new research supporting artificial intelligence (AI), machine learning (ML), augmented, virtual and mixed reality (AR/VR/MR), deep learning and more. It is organized by the IEEE Computer Society and the Computer Vision Foundation. CVPR delivers important advancements to all areas of computer vision and pattern recognition and the diverse fields and industries they impact. It includes tutorials and workshops, a cutting-edge exhibition, networking opportunities and more. CVPR attracts more than 10,000 scientists and engineers each year.


