

Image by author
In today’s world, all organizations want to use machine learning to analyze the data they generate daily from their users. Data can be analyzed with the help of machine or deep learning algorithms. You can then make predictions on test data in production. But let’s say you start following the process above. In that case, you may face problems such as building and training machine learning models. This is time consuming and requires expertise in areas such as programming, statistics, and data science.
So, to overcome such challenges comes Automated Machine Learning (AutoML), which has emerged as one of the most popular solutions that can automate many aspects of the machine learning pipeline. So, in this article, we’ll explore his AutoML with Python through a real-world case study on heart disease prediction.
It is easy to observe that heart-related problems are the leading cause of death worldwide. The only way to mitigate these types of effects is through some automated method of early detection of the disease to reduce the time spent there and then preventative measures to mitigate its effects. So, with this issue in mind, we look at one of our datasets related to medical patient records to build a machine learning model that can predict the likelihood or probability of a heart disease patient . This type of solution can be easily applied and checked in the hospital, allowing doctors to provide treatment as soon as possible.
The complete model pipeline used in this case study is shown below.
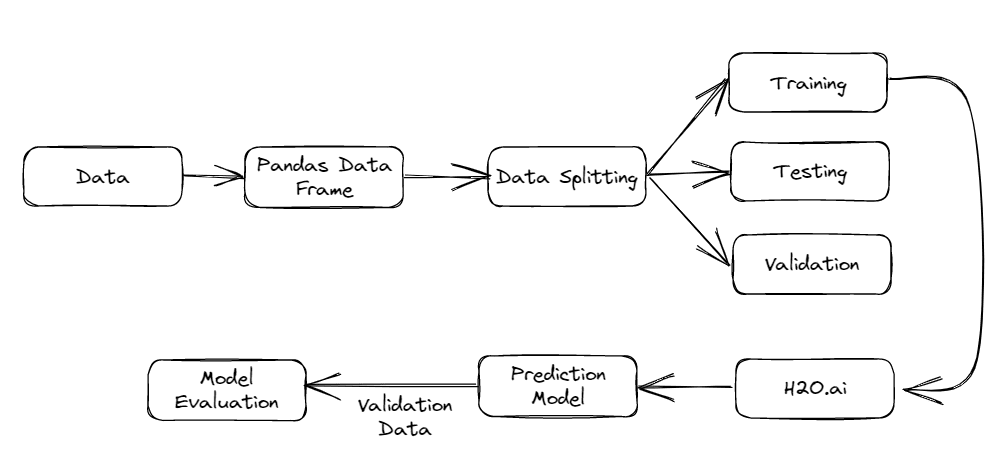
Figure 1 AutoML model pipeline | Image by author
implementation
step 1: Before we start the implementation, let’s import the necessary libraries such as NumPy for matrix manipulation, Pandas for data analysis, and Matplotlib for data visualization.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import h2o
from h2o.automl import H2OAutoMLStep 2: After importing all the necessary libraries in the steps above, we will try to load the dataset while saving it in an optimized way utilizing a Pandas data frame. Data structures such as linked lists, arrays, and trees.
Additionally, data preprocessing can be performed to prepare the data for further modeling and generalization. See the link to download the dataset used here.
# Initialize H2O
h2o.init()
# Load the dataset
data = pd.read_csv("heart_disease.csv")
# Convert the Pandas data frame to H2OFrame
hf = h2o.H2OFrame(data)Step-3: After preparing the data for your machine learning model, use one of the popular automated machine learning libraries called H2O.ai. This is useful for building and training models.

Image by H2O.ai
A major advantage of this platform is that it provides a high-level API that allows easy automation of many aspects of the pipeline, such as feature engineering, model selection, data cleaning, and hyperparameter tuning. Machine learning models for data science projects.
Step-4: Now, to build the model, we will use the APIs of the H2O.ai library. To use this, be it a regression or classification problem, or the target variable is mentioned. The library then automatically selects the best model for a given problem statement, including algorithms such as support vector machines, decision trees, and deep neural networks.
# Split the data into training and testing sets
train, test, valid = hf.split_frame(ratios=[0.7, 0.15])
# Specify the target variable and the type of problem
y = "target"
problem_type = "binary"Step-5: After completing the optimal model from a set of algorithms, the most important task is to fine-tune the model based on the relevant hyperparameters. This tuning process involved a number of techniques such as grid search cross-validation to find the optimal set of hyperparameters for a given problem.
# Run AutoML
aml = H2OAutoML(max_models=10, seed=1, balance_classes=True)
aml.train(y=y, training_frame=train, validation_frame=valid)
# View the leaderboard
lb = aml.leaderboard
print(lb)
# Get the best model
best_model = aml.leaderstep-6: The final task is to check the performance of the model. Use metrics such as confusion matrix, accuracy, and recall for classification problems, and MSE, MAE, RMSE, and R-squared for regression models to help you: Find the inference that our model is working in production.
# Make predictions on the test data
preds = best_model.predict(test)
# Convert the predictions to a Pandas dataframe
preds_df = preds.as_data_frame()
# Evaluate the model using accuracy, precision, recall, and F1-score
accuracy = best_model.accuracy(test)
precision = best_model.precision(test)
recall = best_model.recall(test)
f1 = best_model.f1(test)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)
print("F1-score:", f1)step-7: Finally, the false positive rate (meaning that the model is predicting the wrong result compared to the actual result, meaning the model is predicting the positive class that belongs to the negative class) and false Plot the ROC curve showing the graph. Negative rate (meaning that the model is predicting the wrong result compared to the actual, and the model is predicting the negative class that belongs to the positive class), output the confusion matrix, and finally At , the model’s predictions and evaluations on the test data are complete. Then shut down H2O.
# Plot the ROC curve
roc = best_model.roc()
roc.plot()
plt.show()
# Plot the confusion matrix
cm = best_model.confusion_matrix()
cm.plot()
plt.show()
# Shutdown H2O
h2o.shutdown()You can access the notebook for the above code here.
To conclude this article, we examined various aspects of one of the most popular platforms for automating the entire process of machine learning or data science tasks. It makes it easy to create and train machine learning models using the Python programming language. It covers one of the famous case studies of heart disease prediction and provides a better understanding of how to effectively use such a platform. With such a platform, you can easily optimize your machine learning pipelines, saving engineers in your organization time and reducing system latency and utilization of resources such as GPU and CPU cores.
Aryan Garg It’s B.Tech. I am an electrical engineering student and currently in my final year of undergraduate studies. His interests are in the fields of web development and machine learning. He has been pursuing this interest and would like to work more in these directions.


