


Deep learning inference usually requires explicit modeling of input modalities. For example, Vision Transformer (ViT) directly models her 2D spatial organization of images by encoding image patches into vectors. Similarly, computing spectral characteristics (such as MFCC) to send to the network is frequently involved in speech inference. Before users can infer files stored on disk (like JPEG image files or MP3 audio files), they must first decode the files into modality-specific representations (like RGB tensors or his MFCC). Shown in Figure 1a. Decoding the input into a modality-specific representation actually has two drawbacks.
First, we need to manually create the input representations and model stems for each input modality. Recent projects such as PerceiverIO and UnifiedIO demonstrate the versatility of the Transformer backbone. However, these techniques still require modality-specific input preprocessing. For example, before sending image files to the network, PerceiverIO decodes them into tensors. Other input modalities are converted into various formats by PerceiverIO. They hypothesize that all modality-specific input preprocessing can be eliminated by performing inference directly on the file bytes. A second drawback of decoding the input into a modality-specific representation is the exposure of the analyzed material.
Consider smart home gadgets that use RGB photos to make inferences. If an adversary accesses this model input, the user’s privacy can be compromised. They argue that deductions can be performed on the privacy-preserving input instead. To overcome these drawbacks, they found that many input modalities share the ability to save as file bytes. As a result, we feed the file bytes into the model during inference without decoding (Figure 1b). We employ a modified Transformer architecture in our model to allow for the ability to handle different modalities and variable-length inputs.
Apple researchers introduced a model known as ByteFormer. They demonstrated the effectiveness of ByteFormer in ImageNet classification using data stored in TIFF format, achieving an accuracy rate of 77.33%. Their model uses DeiT-Ti transformer backbone hyperparameters and achieved 72.2% accuracy with RGB input. In addition, JPEG and PNG files also give excellent results. Furthermore, we showed that our classification model reached 95.8% accuracy on Speech Commands v2, comparable to the state-of-the-art (98.7%), without any architectural changes or hyperparameter tweaks.
ByteFormer can also handle multiple input forms, so it can be used to handle private input as well. They show that the input can be falsified without sacrificing precision by remapping the input byte values using the permutation function ϕ. [0, 255] → [0, 255] (Fig. 1c). While this does not guarantee cryptographic-level security, it shows how this approach can be used as a basis for masking inputs to learning systems. Higher privacy can be achieved by using ByteFormer to perform inference on partially generated images (Figure 1d). They show that ByteFormer can be trained on images with 90% of the pixels hidden and on ImageNet he can achieve 71.35% accuracy.

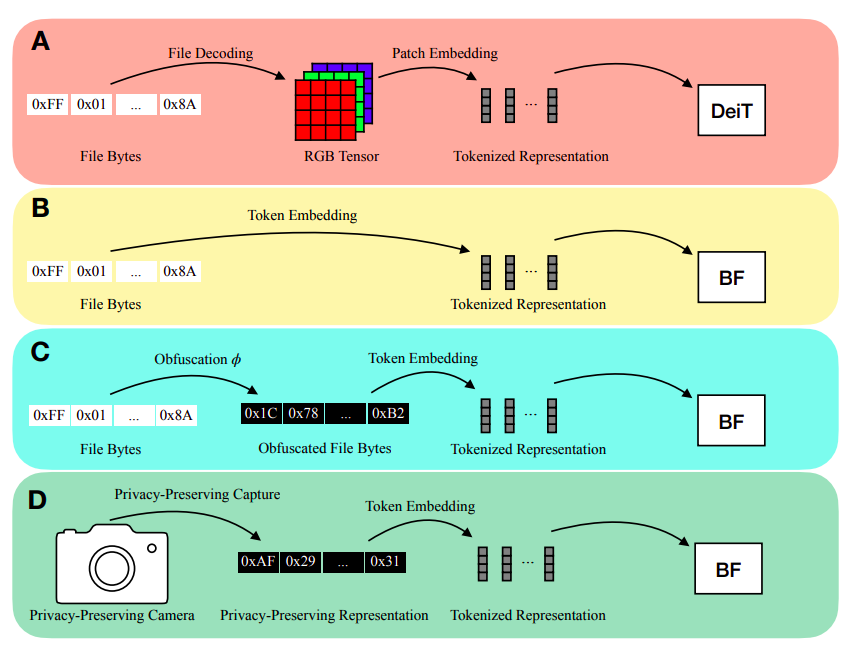
You don’t need to know the exact location of unmasked pixels to use ByteFormer. Avoiding general image capture ensures the anonymity of the representation given to the model. Here’s an overview of their contributions: (1) Created a model called ByteFormer to infer file bytes. (2) They demonstrate that ByteFormer works well for encoding some image and audio files without requiring any architecture changes or hyperparameter optimizations. (3) They give an example of how he can use ByteFormer with privacy preserving input. (4) They examine the properties of his ByteFormer, which has been taught to classify audio and visual data directly from file bytes. (5) He also publishes the code on GitHub.
please check out paper. don’t forget to join 23,000+ ML SubReddit, Discord channeland email newsletterShare the latest AI research news, cool AI projects, and more. If you have any questions regarding the article above or missed something, feel free to email us. Asif@marktechpost.com
🚀 Check out 100’s of AI Tools at the AI Tools Club


Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his Bachelor of Science in Data Science and Artificial Intelligence from the Indian Institute of Technology (IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is in image processing and he is passionate about building solutions around it. He loves connecting with people and collaborating on interesting projects.


