
While Anna is intended to support clinical decision-making by veterinary practitioners, this manuscript focuses on the technical framework required for its successful deployment and integration. Specifically, it is directed at stakeholders responsible for implementing ML infrastructure within veterinary institutions and practice networks—such as administrators, medical informaticians, and IT professionals. Furthermore, this manuscript does not reassess the clinical value of previously described classifiers. Rather, it addresses the technical barrier to their use—namely, the lack of infrastructure to deliver ML predictions directly to the EHR without manual input or technical expertise. We intentionally avoid generalizing about clinical impact, as this depends on factors such as classifier choice, practice type, and patient population. Anna’s modular design allows institutions to integrate the models most relevant to their context. Our focus is on enabling that integration—not prescribing how it will enhance clinical workflows.
General architecture and software requirements
Anna is a stand-alone platform that can host multiple ML classifiers and interfaces with EHRs to provide classifier predictions for patient data in real time. Upon request from an EHR system, Anna fetches relevant laboratory test results from the EHRs, runs available classifiers, and returns classifier prediction results to the EHR system for display to the user (Fig. 1).

Anna architecture and workflow. The prediction pipeline is initiated when a user accesses a specific test result in the electronic health record (EHR) and includes the following steps: 1) Classifier results request. The EHR sends a request to the Anna, including the patient ID and test date; 2) Data fetch. Anna retrieves relevant diagnostic test results from the EHR; 3) Data pre-processing. Anna merges results from different diagnostic tests according to user-defined temporal criteria and forwards the compiled data to the classifier servers; 4) Classifier servers generate prediction results and return the results to the Anna server; 5) The Anna server passes the classifier results back to the EHR system for display to the end-user; 6) Anna stores classifier results, along with associated timestamps, in a MySQL database. To avoid potential variability in the established performance of classifiers, we match the software of each classifier server to the software versions that the model was developed under
Anna is a Python based server built with the Flask web framework and hosted using Apache HTTP Server services. It is a REST server that is not accessible via web browser and doesn’t have a graphical user interface (GUI). Anna is contained in a virtual machine running on Windows Server 2019 and communicates with the EHR system via REST API, an application programming interface that is used to access a resource within another service or application with HTTP requests. The software packages used in Anna are open-source and Anna’s source code and instructions are publicly available (https://github.com/ucdavis/ANNA-AnimalHealthAnalytics).
Machine learning classifiers are hosted in dedicated environments on separate Apache servers and communicate with the Anna core server through unique URL paths. This architecture allows preserving the software versions under which a ML classifier was developed while keeping the Anna core server up to date with respect to securities standards and bug fixes.
To demonstrate Anna’s versatility, we integrated three previously published ML classifiers, each with distinct computational environment requirements: 1) “Addison’s”, a MATLAB-based ML classifier with a Python wrapper script, that employs adaptive boosting with decision trees for the prediction of hypoadrenocorticism in dogs [3], 2) “Lepto”, a Python-based support vector machine (SVM) ML classifier for the prediction of leptospirosis in dogs [4], and 3) “Shunt”, a Python-based extreme gradient boosting (XGBoost) ML classifier for the prediction of portosystemic shunt (PSS) in dogs [5]. All classifiers use at least two of the following data types: signalment, complete blood count, serum chemistry panel, urinalysis, leptospirosis testing request.
Several software libraries are essential for hosting these third-party classifiers on Anna. In general, Anna uses the Python data science package “pandas” [7] to handle data conversions from the EHR during data preprocessing. The Addison’s classifier requires the MATLAB runtime [8], a standalone set of instructions that can execute compiled MATLAB applications or components, to establish connections between Python and MATLAB, and execute MATLAB scripts in Python environments. The advantage of using the MATLAB runtime is that it doesn’t require an active MATLAB license, and it is readily available for download. The leptospirosis classifier utilizes Python data science packages such as “scikit-learn” [9], and “numpy” [10] for further data preprocessing, calculations, and retrieving machine learning prediction results. The shunt classifier requires the “XGBoost” [11] Python package for loading the pre-trained model and generating predictions.
ML classifier prediction workflow
The classifier prediction pipeline consists of six stages: 1) classifier result request, 2) data fetch, 3) data preprocessing, 4) classifier prediction, 5) result and error reporting, and 6) results storage.
Request for classifier result
The generation of ML classifier results is initiated by a REST API request from the EHR system to Anna, containing the patient identification number and query date encapsulated in JSON format. Each classifier is associated with a unique URL. Triggers for initiating a request are flexible and may include a user activating a specific control or merely viewing a particular test result. In the current implementation, the trigger is viewing any laboratory test results that is required for a classifier where the patient species is “Canine” and the user is authorized to have access to the ML analysis.
Data fetch
To retain a lean architecture and minimize the chances of data loss, Anna only stores classifier results but no original patient data. Consequently, patient data is fetched from the EHR for each request. In the current implementation, each data fetch queries several EHR database tables (e.g. hematology, chemistry, microbiology, etc.) in parallel. The use of parallelism for data fetching significantly accelerates the execution of multiple queries as it is an I/O bound process. The EHR supports a REST-based process to request laboratory data and receive results in XML format when provided with a patient ID, date range, and laboratory section of interest. Access to this interface is restricted to specific IP addresses and requires an authorization code in order to respond to the request. Given that classifiers commonly depend on more than one type of laboratory test (e.g. CBC, serum chemistry panel and urinalysis) that may become available over several days, it is pertinent to capture test results that are reported in close temporal proximity. Anna fetches laboratory results within a user-defined time range from the query date. This time range is specific for each classifier and test type (Fig. 2).

Considerations for time range selection when retrieving data from the EHR. To capture test results reported on days other than the query date, users can specify query time ranges for each database (DB) and classifier. The query date serves as the reference, and results are retrieved for the designated period before and after this date. For example: If the test date is “2024-06-27” (YYYY-MM-DD), the following date ranges will be fetched: Hematology DB: 2024-06-26 to 2024-06-28, Chemistry DB: 2024-06-25 to 2024-05-29, and Microbiology 2024-06-22 to 2024-07-02
Data preprocessing
The preprocessing step cleans data fetched from the EHRs system, merges individual tables into a master data frame and produces a classifier-specific data frame that is then passed to the ML classifier (Fig. 3).

Data preprocessing workflow. The preprocessing merges tables fetched from several databases into a single data frame and performs filtering, data cleaning and conversion functions. If there is insufficient data, the classifier is not run and a result code of “−1” is returned to the EHR. If there is sufficient data, the master data frame is passed to the classifier server. Details of the ‘table merging’ step (highlighted in yellow) are described in Fig. 4
First, Anna filters records based on the report status. Typically, a finalized test result is preferred to ensure the accuracy and reliability of results that are passed to a ML classifier. However, in some instances, the test request, rather than the result, is of significance. For instance, the Lepto classifier is applied only when a diagnostic test for leptospirosis, such as Leptospira spp. PCR or microscopic agglutination test has been requested, as it was validated on suspected leptospirosis cases. Consequently, records containing either a finalized Lepto result or simply a test request are retained. Next, Anna merges the data, that were fetched and stored as separate tables, into a single master data frame. The merging logic is explained in Fig. 4.

Merging of test results. If the data retrieved from a single database contains multiple test types (e.g. chemistry panel and urinalysis fetched from the Chemistry DB), then each test type is separated into its own table. Tables are then merged in an ‘all-vs-all’ fashion, i.e. if more than one result is available for a given test, then all possible test combinations are generated. For example, for a dataset with two complete blood counts (CBCs) and two chemistry panels (Chemistry), four unique combinations are created, and classifier results are generated for each combination. Alternatively, records can be filtered before table merging to limit the number of combinations generated based on a user-defined rule (e.g. only retain the first test per test type)
Subsequently, any special characters and string text, such as those found in comments, are eliminated from the numerical fields followed by the conversion of units (i.e. mg to μg) and data types (e.g. categorical to numerical data). Lastly, Anna selects and reorders the variables required by a given classifier and passes a classifier-specific data frame to the classifier module by serializing the data to JSON and sending it with POST requests.
ML classifier prediction and results storage
Classifier results are generated using a dedicated server for each classifier (Fig. 1). This setup allows for a distinct computing environment for each classifier while ensuring security by restricting incoming requests solely to the Anna core server. For every line of the data frame, i.e. each unique set of test combinations, the classifier server generates the following information: 1) the prediction result (0/1 for binary classifiers, multi-level labels for multi-class classifier, 2) the IDs of tests that were used to generate the result, and 3) a timestamp reflecting when the ML classifier was first run on this particular data (Fig. 5). This information is returned to the EHR database via JSON formatted string and stored in a MySQL database for legal purposes. Since classifier results might influence clinical decision making, they are considered part of the medical record and need to be archived. In the current implementation, changes to the EHR system are not possible, which requires storage within Anna.
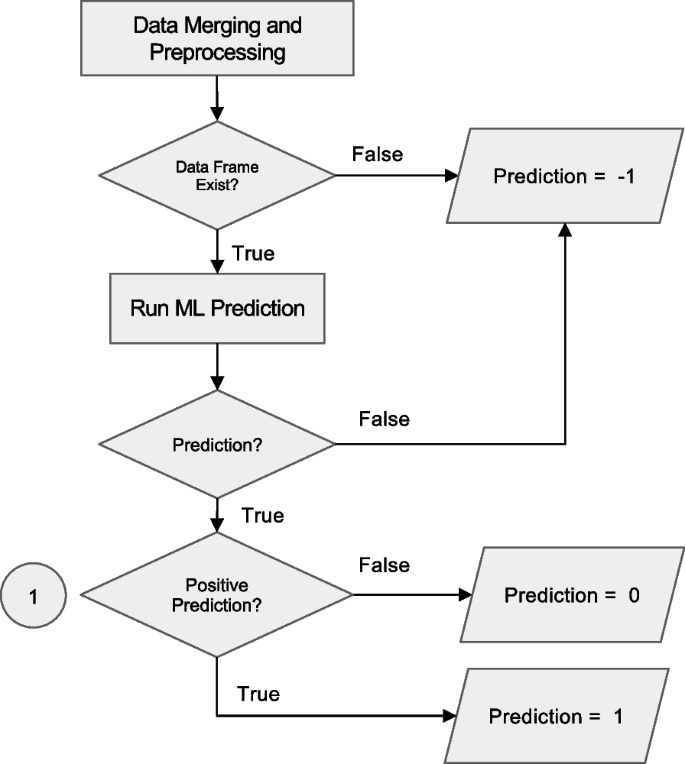
Workflow for prediction handling and result routing in the Anna platform. After data merging and preprocessing, the system checks for the existence of a valid data frame. If data is insufficient, a code of −1 is assigned and logged. If valid, a machine learning (ML) prediction is attempted. Programmatic errors during execution result in a code of −2, which is also logged. Successful predictions are evaluated for positivity: negative results are coded as 0 and positive as 1. All valid predictions (0 or 1) are written to the SQL database for downstream integration and access
Insufficient data and error reporting
Anna automatically attempts to run all available ML classifiers for every request. If there is insufficient data to run a given classifier, either because a required laboratory test was not performed or a required value is missing, Anna reports a “−1” result in the prediction field of the JSON string sent to the EHR system. If the classifier is triggered but exits unsuccessfully, a result of ‘−2’ is reported. In addition, Anna will store the error code and supporting information such as the start and end of a session, including intermediate steps with timestamps in log files locally. To identify each session, a random 6-digit ID is assigned so that Anna developers can quickly locate problems in the log files.
Results visualization
The visualization of the JSON results string supplied by Anna needs to be implemented within the EHR system as Anna is purely a backend application. At UC Davis, we chose to present classifier results within a dedicated section titled Clinical Decision Support Algorithms, located at the bottom of each test result report that contributes input data to the model (Fig. 6). For instance, if a prediction is generated using CBC and chemistry panel data, the corresponding results will appear at the bottom of both the CBC and chemistry panel reports. While this reflects our implementation at Davis, other institutions may choose alternative formats that align with their clinical reporting practices. Since Anna automatically triggers all available classifiers for which the required input data is available, results from more than one classifier might be displayed. If none of the available classifiers renders a prediction, the EHR will display a message “There are no machine learning classifier results available for these data.”. A hyperlink to supplementary information about the specific ML classifier such as previously published performance metrics and interpretation guidelines is also provided to help the user understand the classifier’s purpose and functionality (Fig. 6).

The Anna workflow from an end-user perspective. (1) Selecting a “Small Animal Panel 2” test in the “Diagnostic Procedures” section of the medical record (red arrow) opens the results page and automatically triggers Anna. The system identifies additional test results available within the predefined time window (see Fig. 2) and determines that the combined data are sufficient to generate predictions for the Addison’s disease and leptospirosis classifiers, but not for the liver shunt classifier. (2, 3) Prediction results for the available classifiers are displayed in the “Clinical Decision Support Algorithms” section at the bottom of the page. Test IDs contributing to each classifier’s output are presented as hyperlinks, allowing users to directly access the corresponding laboratory results. The timestamp indicates when each prediction was first generated, enabling users to assess whether the prediction result was available in time to inform clinical decision-making. In this example, both classifiers were implemented in 2024, indicating that the predictions would not have been available to the clinician managing the case in 2019. This time-stamping mechanism was introduced in part for legal reasons, to clearly distinguish retrospective predictions from those that were accessible during real-time clinical decision-making and to prevent misinterpretation of system capabilities at the time of care
Classifier validation
In general, implementing ML classifiers in an environment outside the one in which they were originally developed requires careful re-validation to ensure their applicability to the new clinical setting. Differences in data distribution, laboratory instrumentation, or patient populations can lead to domain shifts that may impact model performance. In our case, all three integrated classifiers were originally developed at UC Davis, meaning that the environments for development/validation and real-world deployment were effectively identical, apart from the temporal offset between both. As such, our primary focus during the initial integration was to ensure computational fidelity: specifically, that the classifiers embedded within Anna produced identical outputs to those generated by the developers’ original implementation under the same conditions. To verify this, we requested a set of representative test cases from the model developers and compared Anna’s prediction outputs against the expected results. This confirmed that embedding a classifier into Anna did not alter its behavior. To ensure reliable classifier performance over time, we are implementing a prospective validation framework that compares Anna’s stored classifier predictions with finalized clinical diagnoses, once confirmatory diagnostics (e.g., imaging, specialist interpretation, or follow-up tests) are complete. This real-world evaluation will enable us to detect performance degradation over time due to domain shifts and support the continuous monitoring and re-calibration of embedded classifiers. Institutions intending to deploy Anna with locally developed or externally sourced models are advised to conduct similar validation steps, both prior to deployment and as part of ongoing clinical quality assurance.
Anna security measures
Because Anna facilitates the exchange of sensitive clinical data between EHRs and ML classifiers, robust security measures are essential to ensure data integrity and prevent unauthorized access. To protect the Anna core server, incoming network traffic is controlled by two measures. First, Anna is accessible only within a specific network domain by routing through a virtual private network (VPN). Second, Anna authenticates the IP address of every incoming connection by cross-referencing the HTTP headers forwarded by the VPN service against an approved list of IP addresses. If an incoming IP does not match this list, the connection is terminated with a 403 Forbidden status, indicating the request is understood but not authorized.
Furthermore, Anna developers can remotely control when EHR can communicate to each ML classifier’s computation server through the Anna core server. Anna will refuse to respond to EHR requests with a 503 Service Unavailable status when the URL path is manually set to disabled.
To ensure secure communications between the Anna core server and the ML classifier servers, the DNS for each classifier server is set to 127.0.0.1, known as “localhost” or “loopback address.” This keeps connections confined within the virtual machine. The Anna core server then makes local connections to each classifier server when receiving requests from the EHR system. Each classifier server is assigned a unique port number for distinction (Fig. 7).
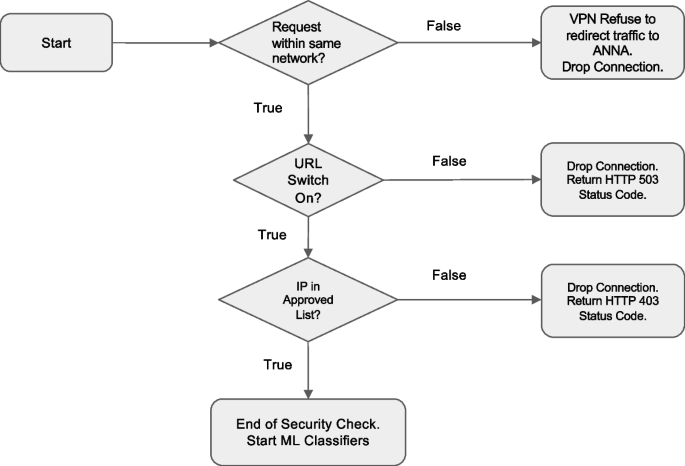
Decision logic of the measures of protecting Anna from unintended access
Integration of new classifiers
One of Anna’s defining strengths is its ability to integrate new machine learning classifiers, regardless of the programming language in which they were developed. Because each classifier operates on a dedicated server, integrating new models does not interfere with existing ones. To maintain a consistent approach and format, we have developed a standard operating procedure (SOP) for integrating new classifiers. This SOP is available in the “resources” folder of our GitHub repository. It defines the structure of the source code and output data and outlines the procedures for incorporating, validating and deploying new classifiers into a production environment. The main steps of integrating a new classifier are as follows: 1) Obtain the required code, model files, validation data, and supporting information from the developer; 2) Define the decision logic and data preprocessing rules necessary for model execution; 3) Integrate the model into Anna and validate its output against the developers’ results; 4) Document any issues encountered during integration process and additional notes for record keeping; and 5) Release the updated version to the public and provide end-users with clear explanations of the newly added classifiers.
Continuous performance monitoring
To monitor potential performance degradation over time, we have implemented a prospective validation strategy. At regular intervals (e.g., every six months), finalized clinical diagnoses are retrieved from the electronic health record (EHR) for all classifier predictions made during the corresponding period. These finalized diagnoses are treated as the ground truth. Concordance between the classifier’s predictions and the final diagnoses is assessed using the large language model GPT-4o. Discordant cases are flagged for review by a subject matter expert. If the discrepancy is due to a misinterpretation by the language model, the output is corrected. Subsequently, performance metrics are computed. To ensure the reliability of the language model, a subset of its predictions is also reviewed manually. Because the review process identifies both true positive and true negative cases, the classifier can be periodically updated using these expert-validated cases.


