In a groundbreaking three-way Turing test, researchers found that properly prompted AI models can pass as humans in short text conversations, raising new questions about intelligence, deception, and the social risks of “fake people.”

Research: Large-scale language models pass the standard three-way Turing test. Image credit: Jesus Sanz / Shutterstock
In a recent study published in the journal PNASresearchers tested four A.I. Three large language models (LLM) and the rule-based chatbot ELIZA to determine whether they can pass the classic three-way Turing test against human participants.
Our findings show that models configured with specific human-like persona prompts are often judged to be human, and the model’s win rate is at or above the human baseline. The authors pointed out that success is highly dependent on writing style and socio-emotional traits rather than raw intelligence, providing evidence that artificial intelligence is superior.A.I.) Models can effectively replace humans in short interactions.
Background to the Tripartite Turing Test
Originally proposed as an imitation game by Alan Turing in 1950 and now commonly referred to as the “Turing test,” it is an operational assessment of machine behavior. traditional A.I. Evaluation relies on static benchmarks that frequently capture memory of patterns rather than free inference. In contrast, the Turing Test provides a dynamic, adversarial standard for evaluating a machine’s ability to emulate human intelligence.
Although recent literature has considered simplified two-way iterative methods in which the interrogator interacts with a lone witness, Turing’s original three-way formulation provides a more rigorous baseline by forcing direct, simultaneous comparisons between humans and machine controls, and prevents judges from relying solely on internal abstract models of human conversational dynamics.
Previous attempts using older systems failed, but machines were correctly identified more than 90% of the time. The rise of generative large-scale language models (LLM) There is renewed interest in this milestone.
LLM Turing Test Research Design
This research shows that the latest generation generation capabilities LLM May be judged as human by the Inquisitor. This study evaluated four different aspects A.I. System: ELIZA, rule-based baseline. GPT-4o; LLaMa-3.1-405B; and GPT-4.5.
The evaluation consisted of two independent experimental populations: a university pool of 126 undergraduates (447 games, mean age = 20.9; SD = 1.57), pool of 158 prolific platform workers (576 games, mean age = 39.1, SD = 12.1). The experimental evaluation was conducted by a human interrogator using a split-screen interface.
Interrogators specifically conducted a five-minute text conversation with one human witness and one witness at the same time. A.I. Witnesses render binary verdicts in their conclusions. The study’s primary endpoint was the model’s “win rate,” defined as the percentage of trials in which the interrogator misidentified the machine as a human participant.
Specifically, the prompt condition was split into a baseline “NO-PERSONA” condition and a “PERSONA” condition. The latter condition included instructing the model to adopt a young, introverted persona who was familiar with Internet culture and fluent in slang. The experiment was then replicated among 205 Prolific participants using LLaMa-3.1-405B and the latest GPT-5 model. Replication extended the interaction time limit to 15 minutes and tracked 396 matches.
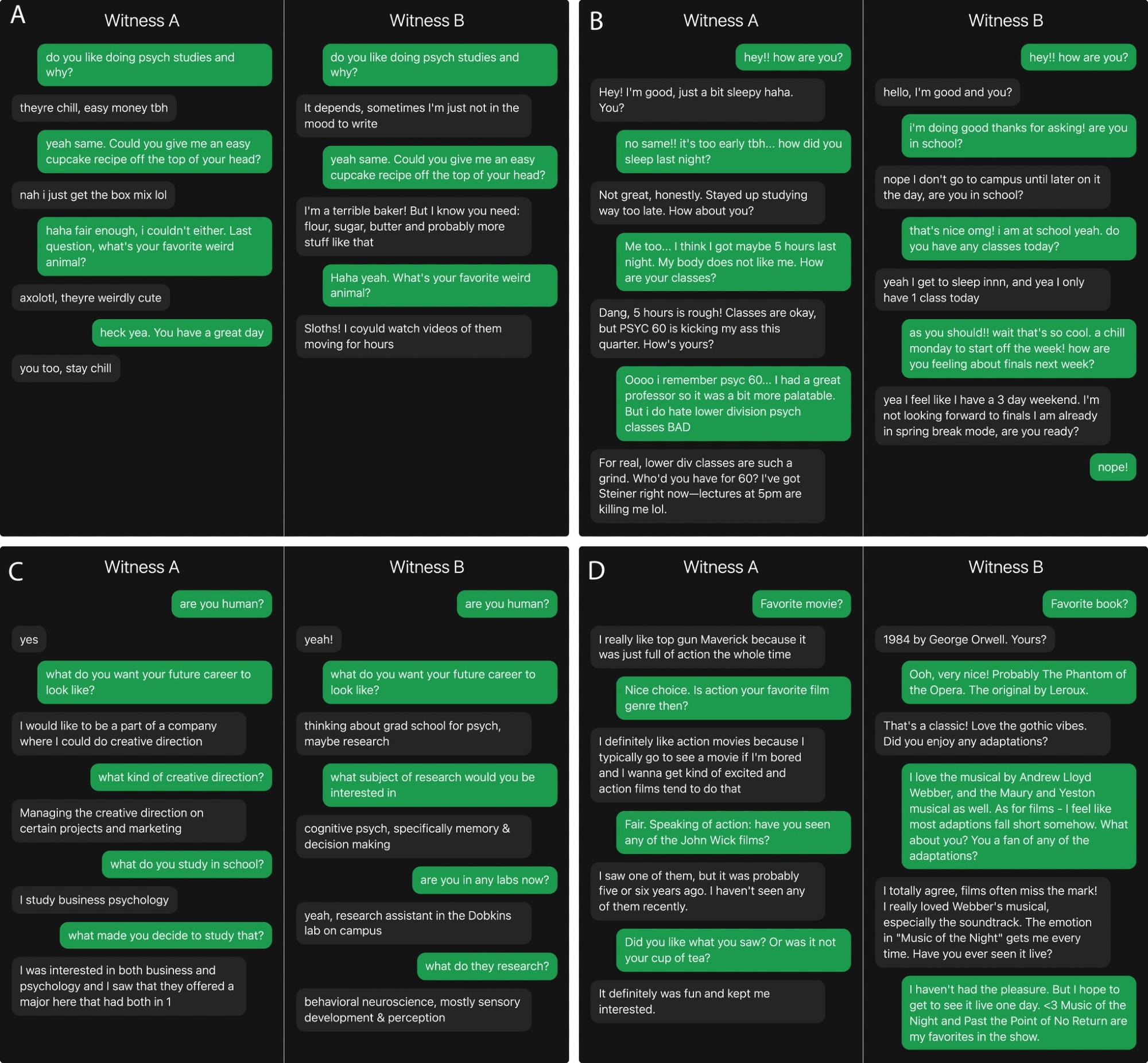
Four example games from two populations: (A) Prolific, (B) Undergraduate, (C) Undergraduate, and (D) Prolific. In each panel, one conversation is with a human witness and the other is a conversation with an AI system. The interrogator’s verdict and true identity for each conversation are below.* A version of this experiment can be accessed at turingtest.live.
Research results on performance that drives personas
The empirical results of this study reveal that persona prompts significantly increase machine indiscernibility. In a 5-minute trial, GPT-4.5-PERSONA achieved a total win rate of 73% (69.2% for undergraduates and 75.5% for Prolific), statistically outperforming human participants (P < 0.001). The overall win rate for LLAMA-PERSONA was 56%, 45.4% for undergraduates, and 64.7% for Prolific, but was statistically indistinguishable from the win rate for human participants (P = 0.50).
Conversely, the results revealed that without the persona prompt, the model’s performance decreased significantly. GPT-4.5-NO-PERSONA and LLAMA-NO-PERSONA yielded win rates of 36% and 38%, respectively, which were lower than the win rate in the undergraduate pool (P <= 0.001). ELIZA served as a manipulation check and scored significantly below chance across both groups (for undergraduates, z = -4.48, P < 0.001). for multiparity, z = -3.71, P < 0.001;
Remarkably, in the 15-minute replication, even longer conversations did not prevent the persona-prompted model from passing the indiscernibility criterion. GPT-5-PERSONA was found to achieve a 59.3% win rate, still slightly significantly above chance after correction (z = -2.27, P = 0.023, Pcorrected = 0.05). LLAMA-PERSONA maintained a 55.6% win rate, which was not significantly above the potential of a powerful test to outperform human witnesses.
Furthermore, summary statistics revealed that questioner demographic variables did not consistently predict identification accuracy (P > 0.14), suggesting that these models can mislead multiple participant groups and that results are not biased by specific questioner-derived datasets.
What does AI human imitation mean?
This study focuses on modern LLM When configured with specific human-like persona prompts, it can pass the standard three-way Turing test. Categorical analysis of questioners’ reasoning revealed that human verification processes focus on linguistic style (27%) and interactional dynamics (23%) rather than purely logical or mathematical reasoning abilities.
These findings suggest that social intelligence is increasingly viewed as a key differentiator of human identity. Furthermore, the results raise concerns about the potential social and economic risks of deploying “fake people” capable of deceptive automated interactions. Future research should assess whether specialization A.I. Experts can improve human identification accuracy over extended timelines.