
This post was written in Mohamed Hossam at Brightskies.
Research universities engaged in large scale AI and high performance computing (HPC) often face important infrastructure challenges that hinder innovation and slow research findings. Traditional on-premises HPC clusters come with long GPU procurement cycles, strict scaling restrictions and complex maintenance requirements. These obstacles limit the ability of researchers to quickly iterate AI workloads such as natural language processing (NLP), computer vision, and basic model (FM) training. Amazon Sagemaker HyperPod eases the heavy lifting involved in building AI models. It helps you quickly scale model development tasks such as training, fine-tuning, or inference across clusters of pre-configured HPC tools and hundreds or thousands of AI accelerators (such as NVIDIA GPUS H100, A100) that are integrated with autoscaling.
In this post, we show how research universities can implement Sagemaker HyperPod to accelerate AI research using dynamic SluRM partitioning, fine-tuned GPU resource management, budget-aware computational cost tracking, and multirosin node load balancing.
Solution overview
The Amazon Sagemaker HyperPod is designed to support large-scale machine learning operations for researchers and ML scientists. The service is fully managed by AWS and removes operational overhead while maintaining enterprise-grade security and performance.
The following architecture diagram shows how to access the Sagemaker HyperPod and submit a job: End users can securely access Sagemaker HyperPod clusters using AWS Site-to-site VPN, AWS Client VPN, or AWS Direct Connect. These connections end on a network load balancer that efficiently distributes SSH traffic to the login node. This is the main entry point for job submission and cluster interaction. At the core of the architecture is the Sege maker HyperPod Compute, controller nodes that coordinate cluster operations, and multiple compute nodes located in the grid configuration. This setup supports efficient distributed training workloads with high speed interconnections between nodes. All of these are included within a private subnet for added security.
The storage infrastructure is built around two main components: AmazonFSXfor Luster offers high-performance file system capabilities, while Amazon S3 provides dedicated storage for datasets and checkpoints. This dual storage approach provides both high speed data access for training workloads and ensuring valuable training artifacts.
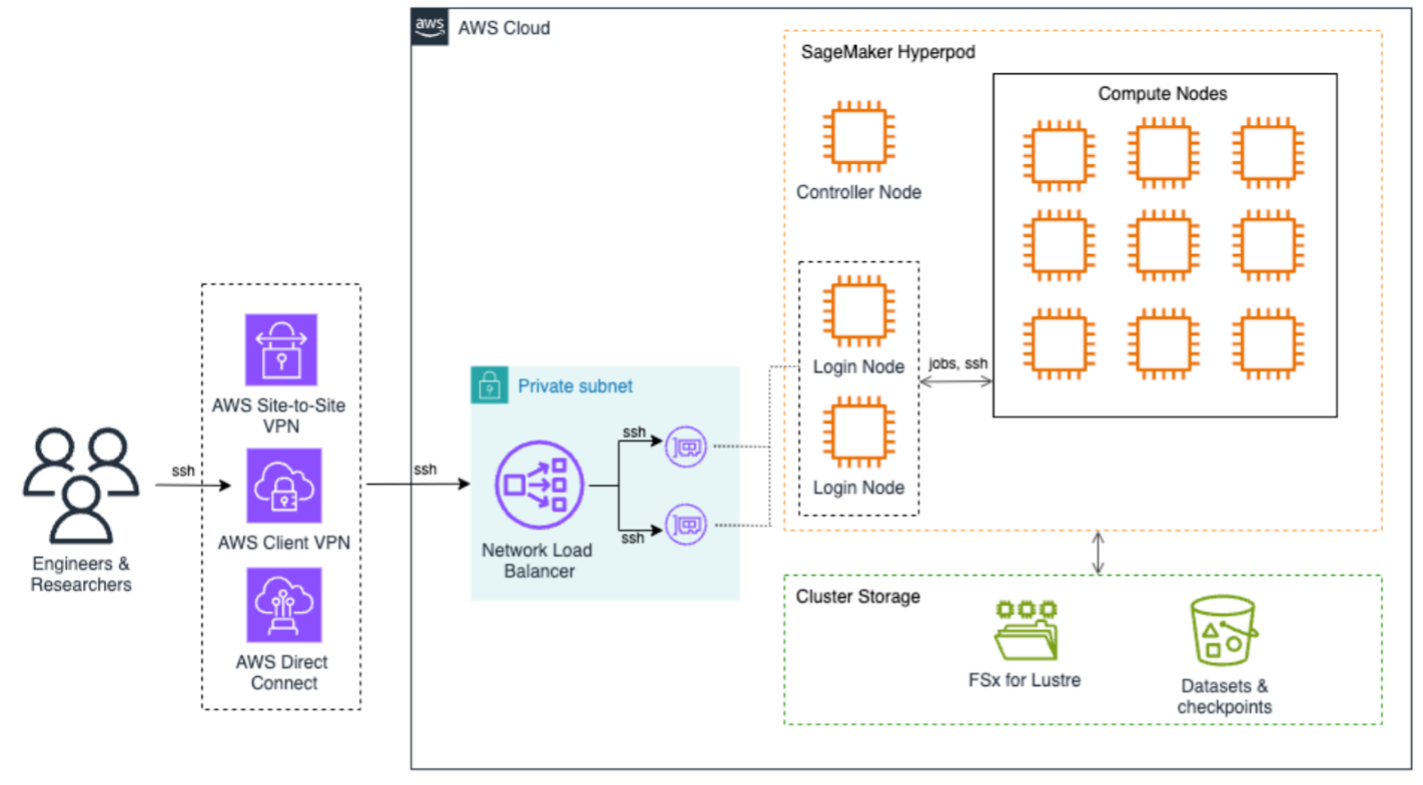
The implementation consisted of several stages. The following steps show you how to deploy and configure a solution.
Prerequisites
Before deploying Amazon Sagemaker HyperPod, make sure the following prerequisites are in place:
- AWS Configuration:
- AWS Command Line Interface (AWS CLI) with Appropriate Permissions
- Prepared cluster configuration file:
cluster-config.jsonandprovisioning-parameters.json
- Network setup:
- AWS Identity and Management (IAM) role with the following permissions:
Launch the CloudFormation stack
I launched the AWS CloudFormation stack to provision the necessary infrastructure components, including VPCs and subnets, FSX for Luster file systems, S3 buckets for lifecycle scripts and training data, and IAM roles with scope transparency for cluster operations. For information about CloudFormation templates and automation scripts, see the Amazon Sagemaker HyperPod Workshop.
Customize the SluRM cluster configuration
To tailor the computing resources to the research needs of the department, we created SluRM partitions that reflect the organizational structure, including NLP, computer vision, and deep learning teams. Defined using SluRM partition configuration slurm.conf Comes with a custom partition. SLURM Accounting is now enabled by configuring slurmdbd Link usage to department accounts and supervisors.
Generic Resource (GRES) configuration has been enabled to support fractional GPU sharing and efficient use. GPU stripping allows multiple users to access the GPU on the same node. The GRES setup followed the guidelines of the Amazon Sagemaker HyperPod Workshop.
Provide and validate clusters
I've verified cluster-config.json and provisioning-parameters.json Files using AWS CLI and Sagemaker HyperPod verification script:
Next, I created a cluster.
Implement cost tracking and budget enforcement
To monitor usage and control costs, each sage maker's hyperpod resources (e.g. Amazon EC2, FSX for Luster, etc.) have been tagged uniquely ClusterName tag. AWS Budgets and AWS Cost Explorer Reports were configured to track monthly expenses per cluster. Additionally, alerts were set up to notify researchers when they approached quota or budget thresholds.
This integration helped to promote efficient use and predictable research spending.
Enable load balancing for the login node
As the number of concurrent users increased, the university adopted a multirosin node architecture. Two login nodes have been deployed in the EC2 autoscaling group. The network load balancer consisted of target groups for routing SSH and system manager traffic. Finally, AWS Lambda enforces per-user session limits Run-As Tags with Session Manager, a feature of Systems Manager.
For more information about the full implementation, see Implementing Login Node Load Balancing in Sagemaker HyperPod to enhance the multi-user experience.
Configure federated access and user mappings
To facilitate secure and seamless access for researchers, Institution has integrated on-premises Active Directory (AD) using AWS Directory Services. This allows for uniform and management of user identity, as well as access permissions across your Sagemaker HyperPod account. The implementation consisted of the following important components:
- Federation User Integration – I used Session Manager to map ad users to POSIX usernames
run-asFine control over tags and compute node access - Secure session management – I configured the System Manager to allow users to access using my account instead of the default
ssm-user - ID-based tagging – Federation usernames have been automatically mapped to user directory, workload, and budget via resource tags
For complete step-by-step guidance, see Amazon Sagemaker HyperPod Workshop.
This approach streamlined user provisioning and access control while maintaining strong consistency between agency policies and compliance requirements.
Post-Deployment Optimization
To prevent unnecessary consumption of computing resources due to idle sessions, the university configured Slurm using a pluggable authentication module (PAM). This setup will automatically log out users after a slam job has been completed or cancelled, supporting rapid availability of the computing nodes for queued jobs.
The configuration improved throughput job scheduling by quickly releasing idle nodes and reducing administrative overhead in managing inactive sessions.
Additionally, QoS policies were configured to control resource consumption, limit work duration, and enforce fair GPU access across users and departments. for example:
- Maxtresperuser – Make sure that per user GPU or CPU usage stays within defined limits
- maxwalldurationperjob – Helps prevent excessively long jobs from monopolizing nodes
- Priority weight – Adjust priority scheduling based on research groups or projects
These extensions promoted an optimized, balanced HPC environment that was consistent with the academic research institute's shared infrastructure model.
cleaning
To delete resources and prevent ongoing charges, complete the following steps:
- Delete the Sagemaker HyperPod cluster.
- Removes the CloudFormation stack used for the Sagemaker HyperPod infrastructure.
This automatically removes related resources, such as VPCs and subnets, Luster File System FSX, S3 buckets, and IAM roles. If you create these resources outside of CloudFormation, you will need to manually delete them.
Conclusion
Sagemaker HyperPod offers research universities a powerful, fully managed HPC solution tailored to the unique requirements of AI workloads. Automating infrastructure provisioning, scaling and resource optimization allows agencies to accelerate innovation while maintaining budgetary control and operational efficiency. Through customized SluRM configurations, GPU sharing with GRE, federated access and robust login node balancing, the solution highlights the potential to transform Sagemaker HyperPod research computing so that researchers can focus on science rather than infrastructure.
For more information on making the most of your Sagemaker HyperPod, check out the Sagemaker HyperPod workshop. Check out our blog post about SageMakerHyperPod.
About the author
 Tasneem Fathima I am a senior solution architect at AWS. She supports UAE's higher education and research clients to adopt cloud technology, improve time to science, and innovate on AWS.
Tasneem Fathima I am a senior solution architect at AWS. She supports UAE's higher education and research clients to adopt cloud technology, improve time to science, and innovate on AWS.
 Mohamed Hotham Specializing in AWS' high-performance computing (HPC) and AI infrastructure at Brightskies' Senior HPC Cloud Solutions Architect. He supports universities and research institutes in the Gulf and Middle East as he leverages GPU clusters, accelerates AI adoption, and migrates HPC/AI/ML workloads to the AWS cloud. During his free time, Mohamed enjoys playing video games.
Mohamed Hotham Specializing in AWS' high-performance computing (HPC) and AI infrastructure at Brightskies' Senior HPC Cloud Solutions Architect. He supports universities and research institutes in the Gulf and Middle East as he leverages GPU clusters, accelerates AI adoption, and migrates HPC/AI/ML workloads to the AWS cloud. During his free time, Mohamed enjoys playing video games.


