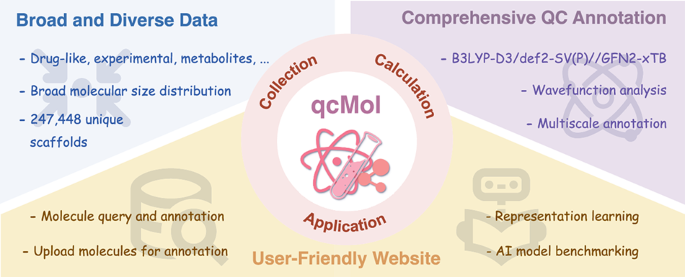
Informative molecular representations are a prerequisite for accurate prediction of molecular properties by machine learning, but effective learning requires large-scale data rich in detailed physicochemical information. Here we introduce qcMol, a dataset consisting of 1.2 million molecules with DFT-level quantum chemical annotations to facilitate learning molecular representations. The chemicals in this dataset include drug-like compounds, metabolites, and molecules with matching experimental data, covering 247,448 different scaffolds and a wide range of molecular sizes. Each compound in qcMol is annotated with multiple quantum descriptors obtained through reliable quantum chemical calculations and follow-up wave functions after analysis at the level of B3LYP-D3/def2-SV(P)//GFN2-xTB. These features are organized into multiple formats, allowing for flexible integration into diverse molecular representation learning frameworks. qcMol serves not only as a pre-training resource but also as a benchmark test set for machine learning models, useful for practical in silico drug discovery.



