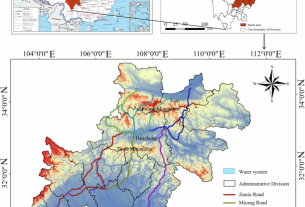
Study area and data collection
River Ganga, also known as the Ganges, is a transboundary river that flows through India and Bangladesh. It begins in the Himalayas, travels about 2525 kilometers, and empties into the Bay of Bengal. Apart from its cultural and spiritual significance, the Ganga River enables inland navigation and supports key sectors like as agriculture, fishing, tourism, and hydropower generation, all of which contribute to the local economy. Unfortunately, the water in the Ganga river is severely polluted, and the primary sources of which can be attributed to the unregulated release of untreated wastewater, industrial waste, and the inflow of agricultural runoff25,26.
River Ganga has a length of around 1450 kilometers in Uttar Pradesh. The data used in this study was collected from the Uttar Pradesh Pollution Control Board, Government of India. This dataset comprises of real-time measurements of DO levels obtained through the Real-time Water Quality Monitoring System installed at multiple locations along the River Ganga, its principal tributaries, and drains. The water quality data utilised in this study is for ten stations of River Ganga and its tributaries in Uttar Pradesh and spans from 1 April 2017 to 30 September 2021. In the original dataset, the sampling frequency ranged from one sample per hour for the years 2017 and 2018 to one sample every 15 min from the year 2019 to 2021. The specific locations analyzed in this study are distinctly marked and shown in Fig. 1. More details about the data considered in the study are provided in Supplementary Information and Supplementary Table S1.
CEEMDAN
CEEMDAN19 uses an adaptive noise level, which adjusts the noise level of each ensemble realization based on the local signal characteristics, to enhance decomposition performance and efficiency. For the CEEMDAN decomposition process, first, we add white noise to the original time series signal X
(1)
where \(s_0\) is the noise coefficient for controlling the signal-to-noise ratio and \(\omega ^i
(2)
The initial residual is computed by subtracting the first IMF from the original signal as follows:
$$\begin{aligned} r_1
(3)
The rest of the IMFs and residual can be calculated as follows:
$$\begin{aligned} \overline{IMF_k
(4)
$$\begin{aligned} r_k
(5)
where, \(E_k(.)\) extracts the \(k^{th}\) IMF that EMD has decomposed. The calculation of the final residual involves subtracting the sum of all the K IMFs from the original signal, resulting in the following expression
AdaBoost
AdaBoost is a machine learning algorithm developed by by Freund et al.27. It employs a combination of weak classifiers to construct a strong classifier with enhanced performance. Although it was originally designed for classification problems, it can also be adapted for regression tasks28. In AdaBoost regression, weak learners are replaced with regression models that can predict continuous values. The algorithm iteratively fits regression models to the data and assigns weights to the samples based on their error. More weight is given to poorly predicted samples in subsequent iterations. The final prediction is a weighted combination of all the regression models’ predictions, with the weights determined by their performance on the training data. AdaBoost uses the following steps for the computation:
Let the data points used for training be \((x_1,y_1)\) … \((x_N,y_N)\).
-
Step 1 Initialize the number of iterations as T. Let for the initial iteration, \(t = 1\) and average loss \(\overline{L_t} = 0\). Initialize the sample weights distribution as \(D_t(i) = \frac{1}{N}\) for \(i = 1…N\)
-
Step 2 Using the sample weights, train the regression model. Let \(f(x_i)\) be the predicted value for the \(i^{th}\) sample.
-
Step 3 For each training sample compute the loss as : \(l_t(i) = \vert f(x_i) – y_i \vert\)
-
Step 4 The loss function for each individual training instance can be calculated as:
$$\begin{aligned} L_t(i) =l_t(i)/M_t \end{aligned}$$
(7)
where, \(M_t = max_{i=1}^{N}l_t(i)\)
-
Step 5 Compute the average loss: \(\overline{L_t} = \sum _{i=1}^{N} L_t(i)D_t(i)\)
-
Step 6 Set \(\beta _t = \overline{L_t}/(1-\overline{L_t})\)
-
Step 7 Now, update the weight distribution of all the samples as follows :
$$\begin{aligned} D_{t+1}(i) = \frac{D_{t}(i)\beta _t^{1-L_t(i)}}{Z_t} \end{aligned}$$
(8)
Here, \(Z_t\) is the normalization factor.
-
Step 8 Now update \(t = t+1\) and repeat steps 2 to 8 while t \(\le\) T and average loss function \(\overline{L_t} \le 0.5\)
-
Step 9 Finally, the output can be given as follows:
$$\begin{aligned} f_{fin}(x) = inf \left[ y \epsilon Y: {\sum _{t: f_t(x)<=y}log \left(\frac{1}{\beta _t} \right) \ge \sum _{t} \frac{1}{2} log \left(\frac{1}{\beta _t} \right)}\right] \end{aligned}$$
(9)
LSTM
LSTM29 are a special type of recurrent neural network with the capacity to learn long-term dependencies by employing cell states to store information about various time periods. A individual LSTM unit’s cell state describes the data that has been thought to be relevant up to that date. By using input, output, and forget gates, LSTMs control the information flow to the cell states. The input gate assesses the importance of incoming data and decides how much of it should be retained in the memory cell. The forget gate regulates which past information should be ignored, while the output gate guarantees that only relevant information is produced at each time step. The input at the current time step, denoted as \(x_t\), and the previous hidden state, denoted as \(h_{t-1}\), are used to calculate the values for the input gate, output gate, and forget gate. These gate values are then utilized to update the cell state \(c_t\) of the LSTM. The output gate is applied to the hyperbolic tangent of the cell state \(c_t\) to produce the final hidden state \(h_{t}\). The equations describing the working of LSTM are as follows:
$$\begin{aligned} f_{t}= & {} \sigma (U_{f}x_{t} + W_{f}h_{t-1} + b_{f}) \end{aligned}$$
(10)
$$\begin{aligned} i_{t}= & {} \sigma (U_{i}x_{t} + W_{i}h_{t-1} + b_i) \end{aligned}$$
(11)
$$\begin{aligned} o_{t}= & {} \sigma (U_{o}x_{t} + W_{o}h_{t-1} + b_o) \end{aligned}$$
(12)
$$\begin{aligned} c_t= & {} (f_t \times c_{t-1})+ i_t \times tanh(U_{c}x_{t} + W_{c}h_{t-1} + b_c) \end{aligned}$$
(13)
$$\begin{aligned} h_t= & {} o_t \times tanh(c_t) \end{aligned}$$
(14)
where, \(\sigma\) represents the sigmoid function, tanh denotes the hyperbolic tangent function and \(\times\) indicates the element-wise multiplication. \(W_f, W_i, W_o, W_c\) are the input weight matrices and \(U_f, U_i, U_o, U_c\) are the recurrent weight matrices for the forget, input, output and memory cell gate respectively. The bias vectors to the respective gates are represented by \(b_f, b_i, b_o\) and \(b_c\). The hidden state and input at timestamp t are denoted by \(h_t\) and \(x_t\) respectively.
BiLSTM
The BiLSTM layers are comprised of a pair of LSTM layers with one of them handling the input sequence in a forward direction and the other one processing it in reverse direction. BiLSTM can capture dependencies and patterns that a unidirectional LSTM would miss by analysing the input sequence in both directions resulting in a more complete contextual understanding. The equations describing the working of BiLSTM can be expressed mathematically as below:
$$\begin{aligned} h_{ft}= & {} \phi (W_{fx}x_{t} + W_{fh}h_{f(t-1)} + b_{fb}) \end{aligned}$$
(15)
$$\begin{aligned} h_{bt}= & {} \phi (W_{bx}x_{t} + W_{bh}h_{b(t-1)} + b_{b}) \end{aligned}$$
(16)
$$\begin{aligned} \hat{y_t}= & {} \sigma (W_{fy}h_{ft} + W_{by}h_{bt} + b_{y}) \end{aligned}$$
(17)
here, \(W_{fx}\) and \(W_{bx}\) are the weight matrices from the input to the recurrent units, and \(W_{fh}\) and \(W_{bh}\) are the weight matrices from the recurrent units to themselves for the forward and backward layers respectively. The biases for the forward and backward layers are given by \(b_{fb}\) and \(b_{b}\). \(\phi\) is the activation function at the hidden layers. \(W_{fy}\) and \(W_{by}\) are the weight matrices, and \(b_{y}\) denotes the bias for the output layer.
Proposed approach
The steps for developing the model based on CEEMDAN decomposition combined with AdaBoost and deep learning are given below and the flowchart of the proposed model is shown in Fig. 2.
-
1.
The first step is to use linear interpolation to fill in the missing values. The data for all the years are combined. To ensure consistent sampling frequency across the dataset, the data was extracted at a constant sample rate of one observation per hour for all years from the combined dataset.
-
2.
The CEEMDAN approach is used to decompose the DO time series data into several IMFs and residual with each generated IMF possessing unique and distinctive inherent properties.
-
3.
The data is partitioned into training and testing sets with a ratio of 75:25. 10\(\%\) of the training data is taken for validation.
-
4.
The data is normalized using min-max normalization, which scales the values to the [0,1] range as follows:
$$\begin{aligned} x_{n} = \frac{ x – x_{min}}{x_{max}-x_{min}} \end{aligned}$$
(18)
where, \(x_{n}\) corresponds to normalized value of x. \(x_{min}\) and \(x_{max}\) denotes the minimum and maximum value of the variable.
-
5.
For each IMF, Autocorrelation Function (ACF) and Partial Autocorrelation Function (PACF) are utilized to choose significant lagged data for constructing the forecasting models. Sliding window based multiple input multiple output approach is used to generate a collection of input-output pairs from time series data, with an input window providing historical information while the output window representing the target values.
-
6.
The zero-crossing rate is calculated to check the fluctuation frequency of the data in each IMF and then categorize them into high, medium and low frequency components. If zero-crossing rate of IMF \(\ge\) 0.01 then the IMF is categorized as having high/medium frequency otherwise it has low frequency30. In order to forecast high and medium frequency IMFs, the AdaBoost-BiLSTM model is utilized due to its ability to predict complex non-linear patterns. BiLSTM can handle complex sequential data and detect long-term relationships between inputs and outputs, and AdaBoost can improve prediction accuracy by combining several BiLSTMs. LSTM models are employed for the low-frequency IMFs and residual that display reasonably simple and smooth patterns. In the end, the final prediction is obtained by summing the predicted outcomes of all the IMFs and residual.
Implementation details
The implemented model is developed using Python version 3.7. The CEEMDAN method is used with the help of EMD-signal 1.2.2 package. While implementing CEEMDAN method, the parameter settings include 100 trials and a scale of 0.05 for added noise. The number of lags needed as input to the forecasting algorithms is determined based on ACF and PACF. Supplementary Table S2 presents the identified significant time lags for the decomposed components of the time series data across ten stations. Each dataset may produce different number of IMFs on decomposition. Here, ’NA’ as the table entry represents the absence of IMF for the particular station. Optimal hyperparameters are selected while building the models (details in Supplementary Information). The Supplementary Table S3 lists the search space explored for identifying the optimal hyperparameters. The zero-crossing rate of the IMFs for all the station datasets considered are given in Supplementary Table S4. The deep learning models were implemented using TensorFlow 2.0.0 and Keras 2.3.1 packages. The number of hidden layers range from 3 to 5 and the number of neurons in the hidden layers is varied in the range of 8 to 64. To improve the gradient descent technique, the Adam optimizer was utilized. The ReLU activation function is used in all the hidden layers of the models. The model is trained using the learning rate of 0.001. The batch size used for training is set to 64, and a variable number of epochs ranging from 10 to 100 are employed for each IMF. Early stopping is used to prevent overfitting of the model during training.
Performance evaluation metrics
The criteria to assess the model’s performance are Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), Root Mean Square Error (RMSE) and Coefficient of Determination \((\) \(R^2\) \()\) (details in Supplementary Information), mathematically, expressed as follows:
$$\begin{aligned} RMSE= & {} {\sqrt{\frac{\sum _{t=1}^{n} (\hat{y}_t-y_t )^2 }{n}}} \end{aligned}$$
(19)
$$\begin{aligned} MAE= & {} \frac{1}{n} \sum _{t=1}^{n} |\hat{y}_t-y_t| \end{aligned}$$
(20)
$$\begin{aligned} MAPE= & {} \frac{1}{n} \sum _{t=1}^{n} \frac{|y_t – \hat{y}_t|}{|y_t|} \times 100 \end{aligned}$$
(21)
$$\begin{aligned} R^2= & {} 1- \frac{\sum _{t=1}^{n} (y_t – \hat{y}_t)^2)}{\sum _{t=1}^{n} ( \overline{y} – {y}_t)^2)} \end{aligned}$$
(22)
where, n is the total count of the samples, \(\overline{y}\) is the mean value, \(y_t\) is the true value and \(\hat{y}_t\) is the predicted value at time t.