The best way to train a dog is to use a reward system. If your dog behaves well, give him a treat, and if he does something wrong, scold him. This same policy can also be applied to machine learning models. This type of machine learning method that uses a reward system to train a model is called reinforcement learning.
In this article, “What is Reinforcement Learning?” The Best Guide to Reinforcement Learning describes reinforcement learning and how to implement it in Python.
The need for reinforcement learning
The main drawback of machine learning is that it requires a huge amount of data to train the model. The more complex the model, the more data it may require. However, this data may not be available to us. It may not exist or it may simply be inaccessible. Additionally, the data collected may be unreliable. It may contain incorrect or missing values, or it may be outdated.
Also, learning from a small subset of actions does not expand the vast universe of valid solutions for a particular problem. This will result in slower technology growth. In addition to learning from humans, machines need to learn to perform actions themselves.
All these problems are overcome by reinforcement learning. Rather than using real data to solve a problem, reinforcement learning introduces a model into a controlled environment modeled after the problem statement to be solved.
Your AI/ML career is just around the corner!
AI engineer master's programExplore the program
What is reinforcement learning?
Reinforcement learning is a sub-branch of machine learning that trains a model to return an optimal solution to a problem by making a series of decisions independently.
Model your environment based on your problem statement. The model interacts with this environment and comes up with solutions on its own without human intervention. To push it in the right direction, we simply give positive rewards for actions that bring us closer to our goals, and negative rewards for actions that move us further away from our goals.
To better understand reinforcement learning, let's think about the dog we have to train. Here, the dog is the agent and the house is the environment.
 Figure 1: Agent and environment
Figure 1: Agent and environment
You can encourage your dog to perform different behaviors by offering incentives such as dog biscuits as a reward.
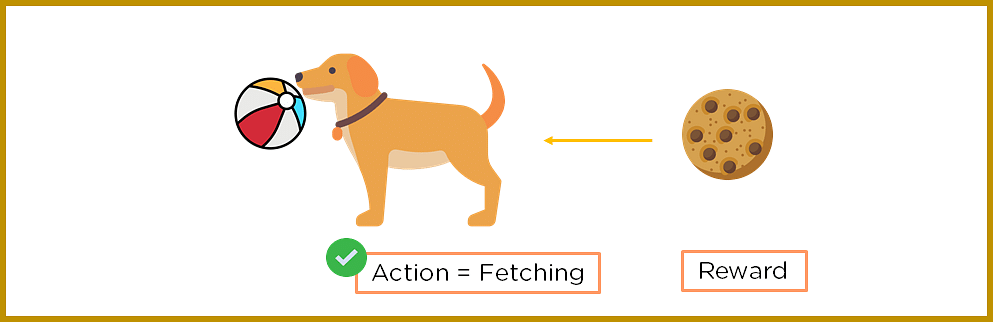
Figure 2: Perform actions and get rewards
Dogs follow a policy of maximizing reward, so they obey every command and may even learn new behaviors on their own, such as begging.

Figure 3: Learning new actions
Dogs also want to run around, play, and explore their surroundings. This quality of the model is called exploration. A dog's tendency to maximize reward is called exploitation. There is always a trade-off between exploration and exploitation, as the act of exploration can lead to diminished rewards.

Figure 4: Exploration and exploitation
Supervised learning, unsupervised learning, reinforcement learning
The table below shows the differences between the three main sub-branches of machine learning.
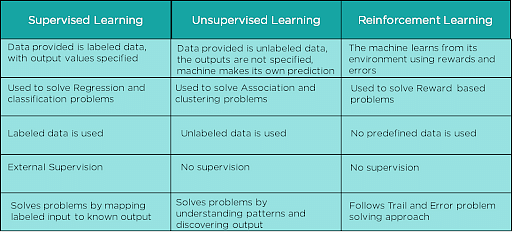
Table 1: Differences between supervised learning, unsupervised learning, and reinforcement learning
Important terms in reinforcement learning
- Agent: An agent is a model that is trained by reinforcement learning.
- Environment: The training situation that a model needs to optimize is called its environment.
- Action: Perform all steps that the model can perform.
- State: Current position/state returned by the model
- Rewards: Rewards/points are given for evaluating some actions to help the model move in the right direction.
- Policies: Policies determine how the agent behaves at any given time. It acts as a mapping between actions and current state.
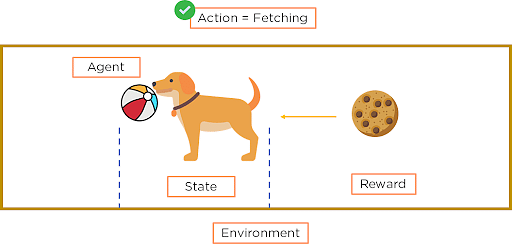
Figure 5: Important terms in reinforcement learning
Your AI/ML career is just around the corner!
AI engineer master's programExplore the program
What is a Markov decision-making process?
A Markov decision process is a reinforcement learning policy used to map current states to actions, where an agent continuously interacts with the environment to generate new solutions and receive rewards.
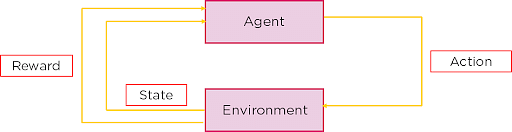
Figure 6: Markov decision-making process
First, let's understand Markov processes. Markov processes state that given the present, the future is independent of the past. This means that given the current state, we can easily predict the next state without needing the previous state.
This theory is used in Markov decision-making processes to obtain the next action in machine learning models. The Markov Decision Process (MDP) uses:
- Set of states (S)
- set of models
- Set of all possible actions (A)
- State- and action-dependent reward function R( S, A )
- Policies that provide solutions for the Democratic Party
The policy of a Markov decision process aims to maximize the reward at each state. Agents interact with the environment and perform actions while in one state to reach the next future state. We take actions based on the maximum reward returned.
In the diagram shown, we need to find the shortest path between nodes A and D. Each path has a reward associated with it and you must choose the path with the greatest reward. node. represents a node. Moving from node to node (A to B) is an action. The reward is the cost at each path, and the policy is each path chosen.
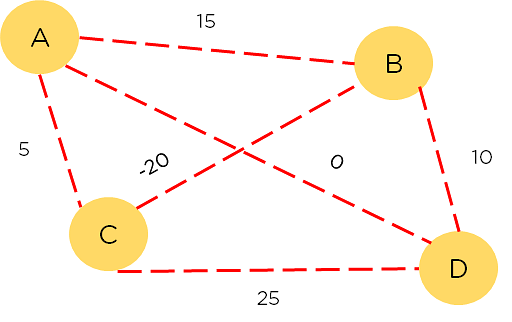
Figure 7: Nodes traversed
The process maximizes output based on the reward of each step and follows the path that yields the highest reward. This process maximizes reward, not exploration.
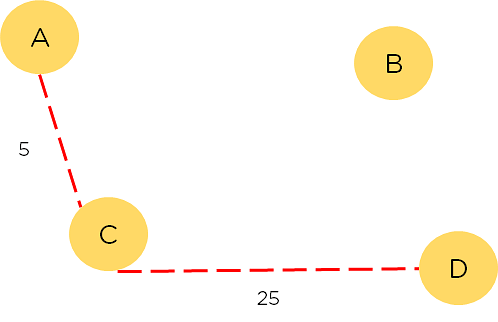
Figure 8: The path taken by MDP
Reinforcement learning in Python
Let's see how reinforcement learning can be used in real-world situations.
Let's create a tic-tac-toe game using reinforcement learning. As you know, reinforcement learning does not require data.

Figure 9: Tic-tac-toe
Let's start by importing the required modules.
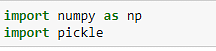
Figure 10: Importing a module
Define a tic-tac-toe board.
![]()
Figure 11: Row and column definition
Now let's define functions for the different possible states.
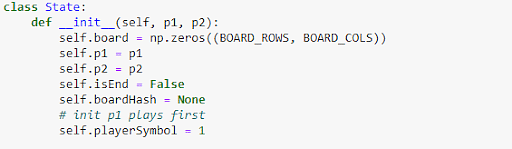
Figure 12: State definition
Actions performed on the board must be stored as a hash function

Figure 13: Save action
Let's define a function to find the winner of the game.

Figure 14: Find the winner
Apart from the winner, the game can also end in a draw.

Figure 15: Finding ties
Let's define a function to track available positions on the board. We also define a state update function and a reward function.

Figure 16: Search for vacant positions.Update status and define rewards
Once the game is finished, the board must be reset.
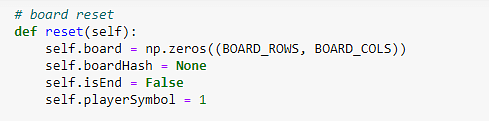
Figure 17: Resetting the board
Let's define the main play function between two opponents. We will use this to train our model.
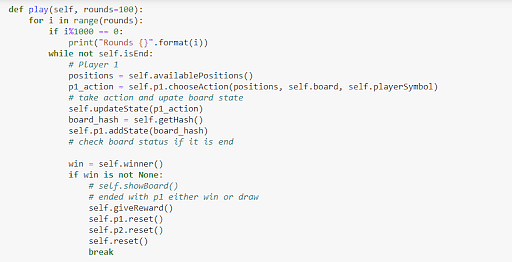
Figure 18: Training function

Figure 19: Training functions continued
Define functions to play the actual game.

Figure 20: Play function

Figure 21: Playback functions continued
The function below draws the board on the terminal.

Figure 22: Drawing the playboard
Let's define a player class that instantiates the player and define the policy. This will be used to train the model.

Figure 23: Player definition
Select the player function's actions and define the state.
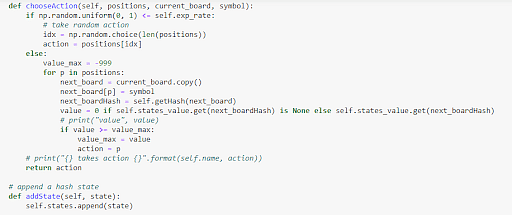
Figure 24: Selecting player actions and defining states
Also define the reward function and save the policy. 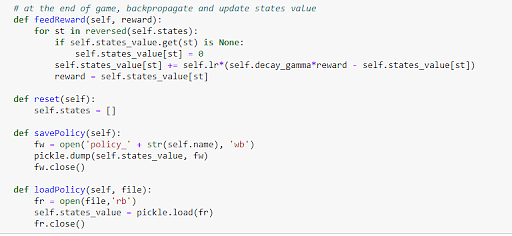
Figure 25: Definition of compensation and savings policy
Next, let's define a class that will be called when the player needs to perform an action.

Figure 26: Functions for human players to play
Let's define a machine player and train the model using the policy we created.

Figure 27: Training the model
Save your policy.

Figure 28: Save policy
Now, let's play tic-tac-toe! The image below shows a game that ended in a draw.



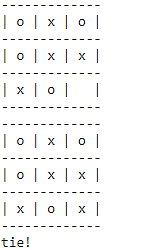
Figure 29: Playing Tic-Tac-Toe against the computer
The game has three possible outcomes: the machine wins, the humans win, or a draw. As you can see, no data was used to train the model, instead the model was trained using the policy we created. Games like online chess and self-driving cars have also been trained this way.
Your AI/ML career is just around the corner!
AI engineer master's programExplore the program
conclusion
In this article, “What is Reinforcement Learning?'' In The Best Guide to Reinforcement Learning, we first answered the questions, “Why do we need reinforcement learning?'' and “What is reinforcement learning?'' We also looked at the differences between machine learning sub-branches. Next, we looked at some common terms related to reinforcement learning. He then moved on to the Markov decision process, which is a reinforcement learning policy, and finally he implemented a trained tic-tac-toe game using reinforcement learning in Python.
I hope this article answers the questions that have been burning in the back of your mind. Do you have any doubts or questions? Please mention them in the comments section of this article. An expert will answer you as soon as possible.
Are you looking forward to becoming a machine learning engineer? Check out Caltech graduate programs in AI and ML on Simplilearn and get certified today.