


Reinforcement learning (RL) faces challenges due to sample inefficiency, which hinders its adoption in the real world. Standard RL techniques are challenging, especially in environments where exploration is dangerous. However, offline RL leverages pre-collected data to optimize policies without online data collection. However, there are hurdles in changing the distribution between targeted policies and collected data, leading to under-sampling issues. This discrepancy can lead to overestimation bias and overly optimistic target policies. This highlights the need to address distribution changes for effective offline RL implementation.
Previous studies address this issue by explicitly or implicitly normalizing policies for the distribution of behaviors. Another approach involves learning a single-step global model from offline datasets to generate targeted policy trajectories with the aim of mitigating distributional changes. However, this method may introduce generalization problems into the world model itself, which may exacerbate value overestimation bias in RL policies.
Researchers from Oxford University attended Policy-based dissemination (PGD) We address the problem of compound errors in offline RL by modeling entire trajectories rather than single-step transitions. PGD trains a diffusion model on an offline dataset and generates synthetic trajectories based on behavioral policies. To align these trajectories with the target policy, we apply guidance from the target policy to shift the sampling distribution. This results in a target distribution with normalized behavior, reducing deviations from the behavior policy and limiting generalization error.

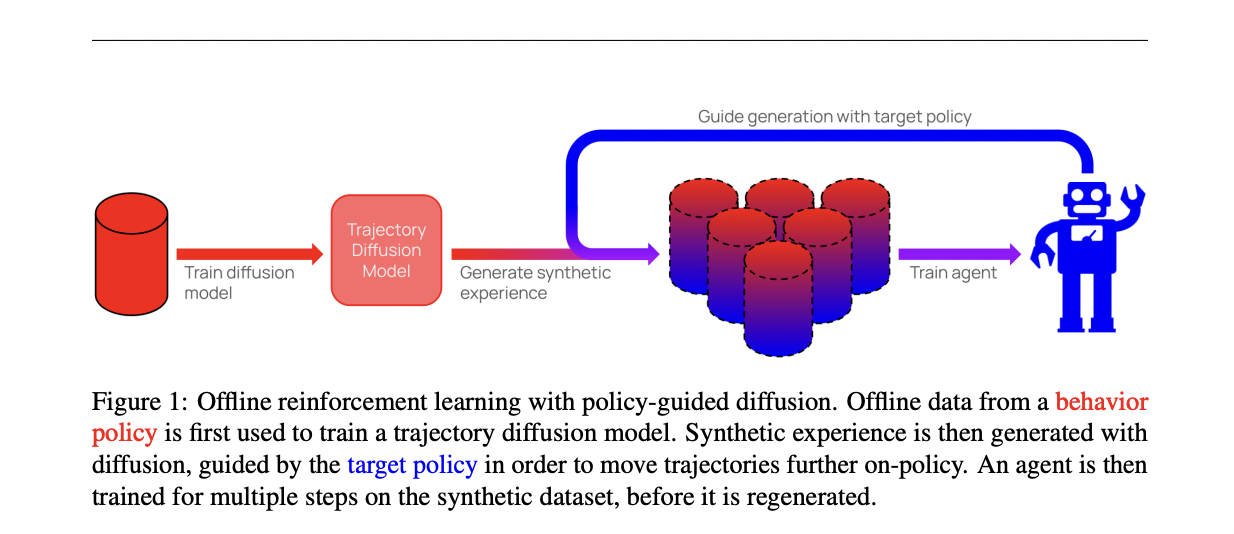
PGD utilizes trajectory-level diffusion models trained on offline datasets to approximate motion distributions. Inspired by classifier-guided diffusion, PGD incorporates guidance from the target policy during the denoising process to guide trajectory sampling towards the target distribution. This results in a target distribution with normalized behavior, which balances the probabilities of actions under both policies. PGD excludes behavioral policy guidance and focuses only on targeted policy guidance. To control the strength of the guidance, PGD introduces guidance coefficients that allow fine-tuning of the regularization level towards the motion distribution. PGD also applies cosine guidance schedule and stabilization techniques to increase guidance stability and reduce dynamic errors.
The conducted experiments demonstrated the following important findings:
- Effectiveness of PGD: Agents trained with comprehensive experience from PGD perform better than agents trained directly on unguided synthetic data or offline datasets.
- Tuning guidance coefficients: Tuning guidance coefficients in PGD allows you to sample likely trajectories of action across different target policies. As the guidance factor increases, the likelihood of trajectories under each target policy increases monotonically, indicating that out-of-distribution (OOD) target policies can sample high-probability trajectories.
- Low dynamics error: Despite sampling likely actions from the policy, PGD retains low dynamics error. Compared to the autoregressive global model (PETS), PGD achieves significantly lower error across all target policies, highlighting its robustness to different target policies.
- Training stability: Periodic generation of synthetic data is better than continuous generation due to training stability, especially when performing guidance in the early stages of training. Both approaches consistently outperform training on real unguided synthetic data, demonstrating the potential of his PGD as an extension of replay and model-based RL techniques.
In conclusion, the Oxford researchers introduced PGD to provide a controllable method for synthetic trajectory generation in offline RL. By directly modeling trajectories and leveraging policy guidance, PGD achieves competitive performance with lower dynamics error compared to autoregressive methods like PETS. This approach consistently improves the performance of downstream agents across different environments and behavioral policies. PGD addresses out-of-sample issues, paves the way for less conservative algorithms in offline RL, and provides potential for further enhancements.
Please check paper. All credit for this research goes to the researchers of this project.Don't forget to follow us twitter.Please join us telegram channel, Discord channeland linkedin groupsHmm.
If you like what we do, you'll love Newsletter..
Don't forget to join us 40,000+ ML subreddits
Want to get in front of an AI audience of 1.5 million people? work with us here


Asjad is an intern consultant at Marktechpost. He is pursuing a degree in mechanical engineering from the Indian Institute of Technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast and is constantly researching the applications of machine learning in healthcare.


