
Diffusion models, now considered state-of-the-art generative text-to-image models, have emerged as “disruptive technologies” that demonstrate unprecedented skill in creating high-quality, diverse images from text prompts. The ability to provide intuitive control over user-created materials remains a challenge for the text-to-image model, but this advancement has enormous potential to transform the way digital content is created.
There are currently two techniques for tuning a diffusion model: (i) training the model from scratch or (ii) fine-tuning an existing diffusion model to the task at hand. Even in fine-tuning scenarios, this strategy often requires heavy computation and long development times as the model and training data volumes continue to grow. (ii) reuse already trained models and add controlled generation capabilities; Some techniques have traditionally focused on specific tasks and created specialized methodologies. This work aims to generate a new integrated framework, MultiDiffusion, which greatly improves the adaptability of pre-trained (reference) diffusion models to controlled image production.

The basic goal of MultiDiffusion is to design new generative processes consisting of several reference diffusion generative processes bound by a set of common properties or constraints. Different regions of the resulting image are subjected to a reference diffusion model that more specifically predicts each denoising sampling step. MultiDiffusion then performs a global denoising sampling step using the least squares optimal solution to adjust all these individual phases. For example, consider the challenge of creating images of arbitrary aspect ratio using a reference diffusion model trained on square images (see Figure 2 below).
🚀 Build high-quality training datasets, solve NLP machine learning challenges, and develop powerful ML applications with Kili Technology
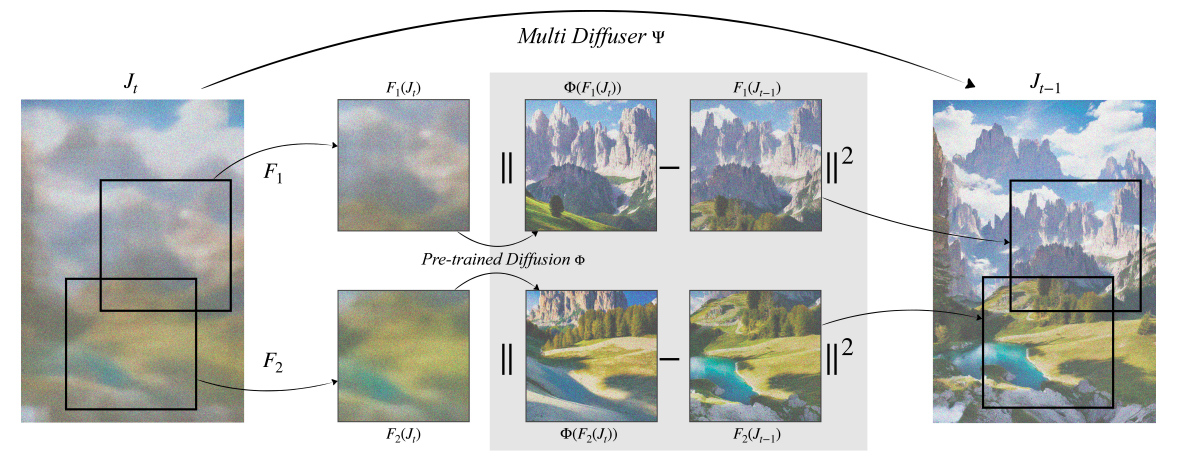
MultiDiffusion merges the denoising directions from all square crops provided by the reference model at each phase of the denoising process. It tries to track them all as best it can, but is hampered by neighboring crops that share common pixels. Note that each crop can be pulled in a different direction for denoising, but that framework results in a single denoising phase, producing a high quality, seamless image. We want each crop to represent a true sample of the reference model.
With MultiDiffusion, pre-trained reference text-to-image models can be applied to a variety of tasks, such as generating images at specific resolutions and aspect ratios, or generating images from unreadable region-based text prompts, as shown in Figure 1. Importantly, its architecture allows simultaneous resolution of both tasks by utilizing a shared development process. By comparing to relevant baselines, they found that their methodology was able to achieve state-of-the-art, controlled production quality, even when compared to approaches specifically trained for these jobs. Also, their approach works effectively without adding computational load. The full codebase will be released on our Github page soon. You can also see more demos on the project page.
Please check paper, githuband project page. All credit for this research goes to the researchers of this project.Also, don’t forget to participate 26,000+ ML SubReddit, Discord channeland email newsletterShare the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his Bachelor of Science in Data Science and Artificial Intelligence from the Indian Institute of Technology (IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and he is passionate about building solutions around it. He loves connecting with people and collaborating on interesting projects.
🔥 Gain a competitive edge with data: Actionable market intelligence for global brands, retailers, analysts and investors. (with sponsorship)


