I have spent the last few years commercializing autonomous robots. First with Swiss scale-up ANYbotics, and now working on go-to-market (GTM) with several companies across physical AI. Spend enough time in the field and you’ll start to see patterns. People work towards the same goal in two very different ways.
Much of the industry is focusing on data-driven approaches following recent advances in machine learning. A smaller group focuses on getting the architecture right the first time, based on real-world deployments and applied research.
It’s not clear which approach is right or wrong, but both have strong teams and real capital. But they start from different assumptions, and those assumptions lead to very different companies, which have ramifications for commercialization.
A data-first approach to robotics
The data-first approach follows the scaling playbook that helped us figure out the language and vision of AI. Collect large amounts of data, train larger and larger models, and let the laws of scaling do the rest. This is the most popular approach in physical AI today, based on the success of large-scale language models, and those who pursue it tend to have a background in language and computer vision. It makes sense to take that bet to robotics.
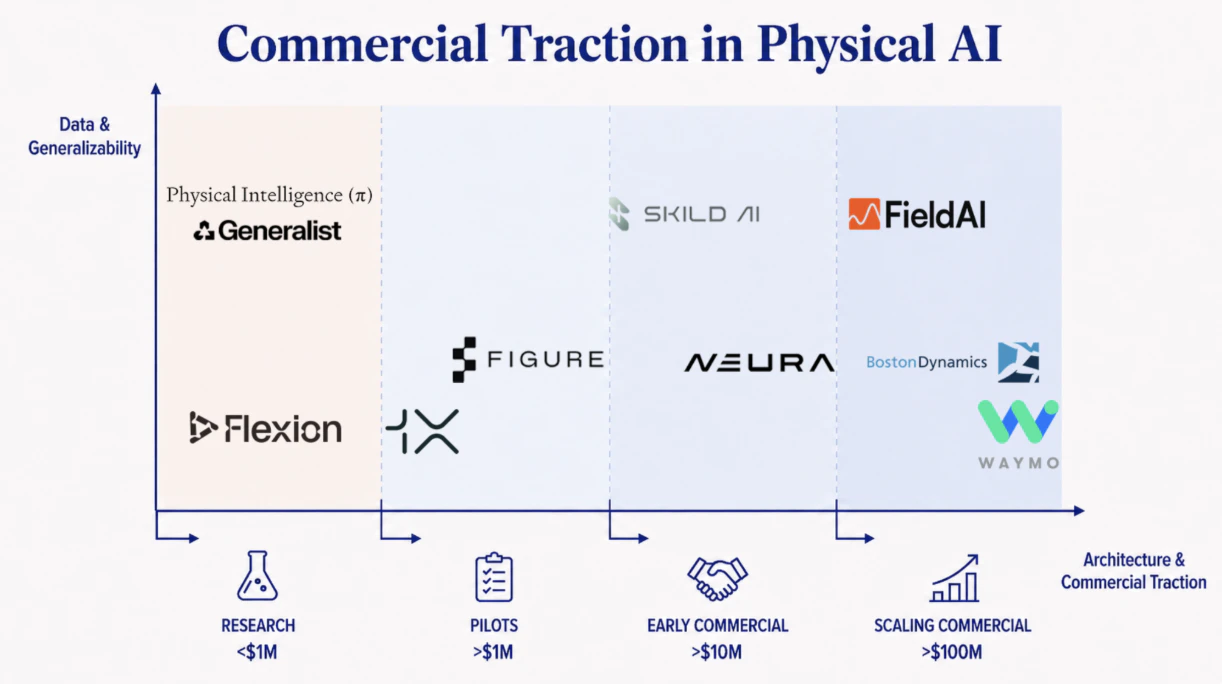
The bet is being played out between deep-pocketed teams on both sides of the Atlantic, including Physical Intelligence and Generalist in the US, Norwegian-founded 1X and Europe’s Zurich-based Flexion. Their data collection methods range from video world models and wearable collection devices to large-scale simulations and remote control.
Most of the effort here goes into local skills such as tabletop manipulation and mobility. The standard practice is to pre-train a model based on the limited data that exists and then fine-tune the model to the specific skills needed. Both steps rely on structured data, and these skills are included and easily measurable, making them a natural fit for benchmarks, demos, and academic papers.
The problem is that physical data doesn’t exist at the same scale as text or images, and the requirements for safety and reliability when it leaves the screen are greater. When you exert your power in the physical world, there is no backspace, so your work must be limited.
A model can only be trusted to work in an environment that is close to what it saw during training, an environment researchers call “in distribution.” As such, this approach begins in the controlled conditions of the laboratory, leaving real-world complexities on the back burner.
The bet here is that over time, as features expand and skills become more common, we build wrappers to catch edge cases as they emerge, and gradually expand what is considered “in distribution.”
We also look forward to future research advances that will hopefully enable real-world deployment. For now, end-to-end model illusions and black-box reasoning prevent it from working in complex and safety-critical settings.
Architecture-first approach
The architecture-first approach begins with a different set of assumptions, shaped by applied research in field robotics and real-world deployment. This method embraces the complexity of the real world from the beginning, and people build the architecture of the model to fit the world as it is, rather than controlling the world to fit the model.
There are fewer teams building this way, and more of them have backgrounds in field robotics than linguistics or visuals. Founded by veterans of NASA’s Jet Propulsion Laboratory, Google DeepMind, and DARPA’s robotics challenges, FieldAI combines Bayesian techniques and modern machine learning in field-based models, deployed at hundreds of locations across Europe, Asia, and North America.
Waymo is making a similar architectural bet in self-driving. While the company has studied pure end-to-end models like EMMA, the introduced Waymo Foundation model maintains a structured design with interpretable parts and Bayesian treatment of uncertainties, so its decisions can be checked and validated over millions of unmanned miles on public roads.
The central premise is that the physical world requires a fundamentally different approach than the digital world, and more data alone won’t get us there. Even though large language models are trained with trillions of tokens, hallucinations still occur. Unlike chatbots, hallucinating robots can actually cause physical harm.
Bringing AI into the physical world is a very difficult architectural problem that requires the deepest research and mathematical rigor. Systems are based in physics and must quantify their own uncertainty and act on that uncertainty, gathering more information when necessary and retreating when the risk is too high. Imagine a robot on a work site, where dust kicks up and you can’t see in front of you. A system that understands uncertainty, like a prudent person, slows down and waits for the air to clear before moving forward.
The result is a data-efficient and resilient system that understands how the world works and knows what it doesn’t know. You can adapt to dynamic, unstructured situations that you may not have experienced in your training. It also makes no assumptions about the site, so you can drop it into a new location and start working just like a new employee would on their first day, without any prior knowledge or supporting infrastructure.
This approach provides customers with a level of operational intelligence that allows robots to complete long tasks from start to finish, perform many actions in sequence, and see multiple robots working together. Personal skills remain important, but they are designed from day one with the constraints and imperfections of real-world operations in mind, rather than being adapted later.
Why this is commercially important for robotics companies
My intuition is that operational data becomes complex in a way that synthetic benchmarks and controlled demos cannot, and that the organizational know-how you build to get robots to perform in places they weren’t designed for is really hard to recreate from the lab.
Architecture-first systems that can handle uncertainty and adapt to the unexpected can be put to work quickly in real-world situations. As a result, teams that build this way tend to have more commercial traction.
It also meets customer needs for operational intelligence that adds value to existing workflows. And every deployment generates operational data. Operational data is one of the rarest and most valuable resources in physical AI.
It is ironic that an approach that requires minimal data to get started ends up collecting large amounts of high-quality data of the kind that encompasses a variety of situations and edge cases that only surface in the field. What looks like a head start in architecture is actually a head start in deployment and self-reinforcing data flywheels.
Physical AI is often described as a race. Who the final winner will be is still an open question, and I don’t pretend to know how it will be resolved. But I know which way the evidence at the scene points.