

# introduction
A model that says it’s 90% confident should be correct 90% of the time. When that relationship breaks down, the following things happen: proofreading mistake problem. Model scores no longer provide useful information about reliability.
for large language model (LLM), incorrect calibration is rampant. A 2024 NAACL study found that confidence scores diverged from actual accuracy rates across fact-based QA, code generation, and reasoning tasks.
Another study on biomedical models found that the average calibration score for all models tested ranged from only 23.9% to 46.6%. The gap is consistent.
standard solution for classic machine learning Re-calibration after the fact. Fit a simple function to the retained validation set to map raw confidence scores to better calibrated probabilities.
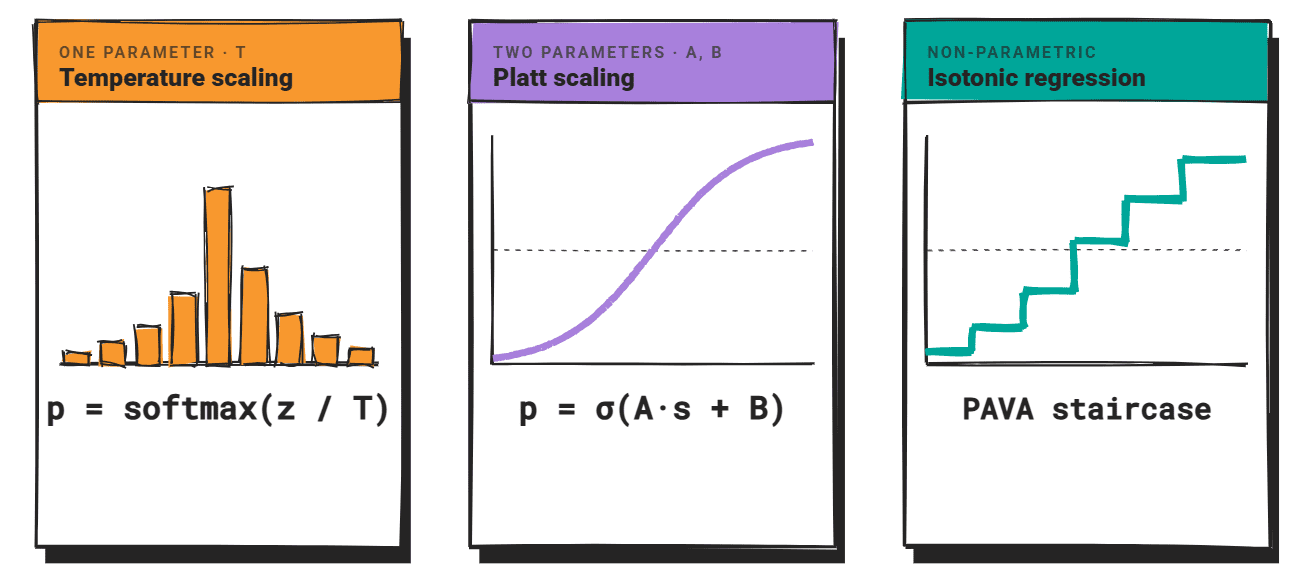
three Methods predominate: temperature scaling, plat scalingand Isotonic regression. All three are designed for discriminative classifiers and should be used with caution when applied to LLM.
# measurement calibration
The dominant indicators are: Expected calibration error (ECE). Group predictions into confidence bins, compute the gap between average confidence and observed accuracy in each bin, and compute the average across bins weighted by size. ECE = 0 is perfect calibration.
Reliability diagrams plot reliability against accuracy. Fully calibrated models are placed diagonally. The overconfident model is underneath. The curve shows high reliability, but the accuracy is not keeping up.
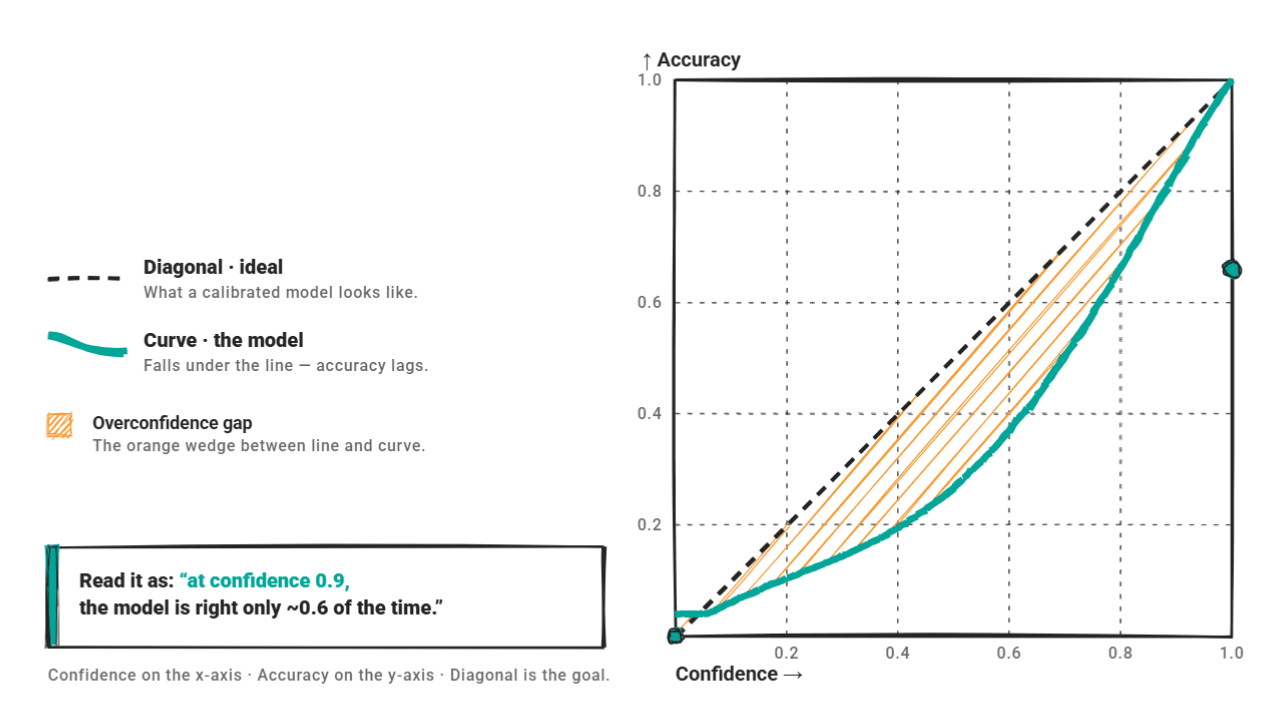
A 2025 evaluation of GPT-4o-mini as a text classifier found that 66.7% of its errors occurred at a confidence level of 80% or higher (a standard overconfidence pattern).
There is a growing belief that ECE alone is not enough. Research papers recommend combining ECE with Briar scores, overconfidence rates, and reliability diagrams. A single number obscures meaningful variation in where and how the model malfunctions.
# Why LLM complicates standard setup
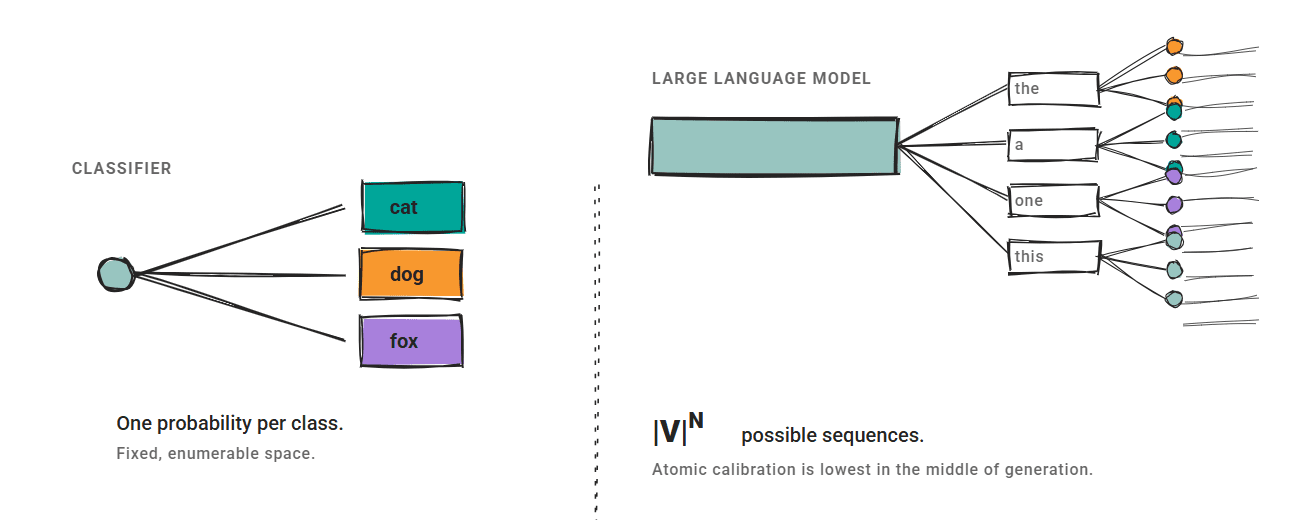
The three methods described here assume a fixed output space. The classifier produces one. probability It is adjusted for each class, and the calibration maps them to better estimates.
LLM Don’t work like this.
Four complex issues are important here.
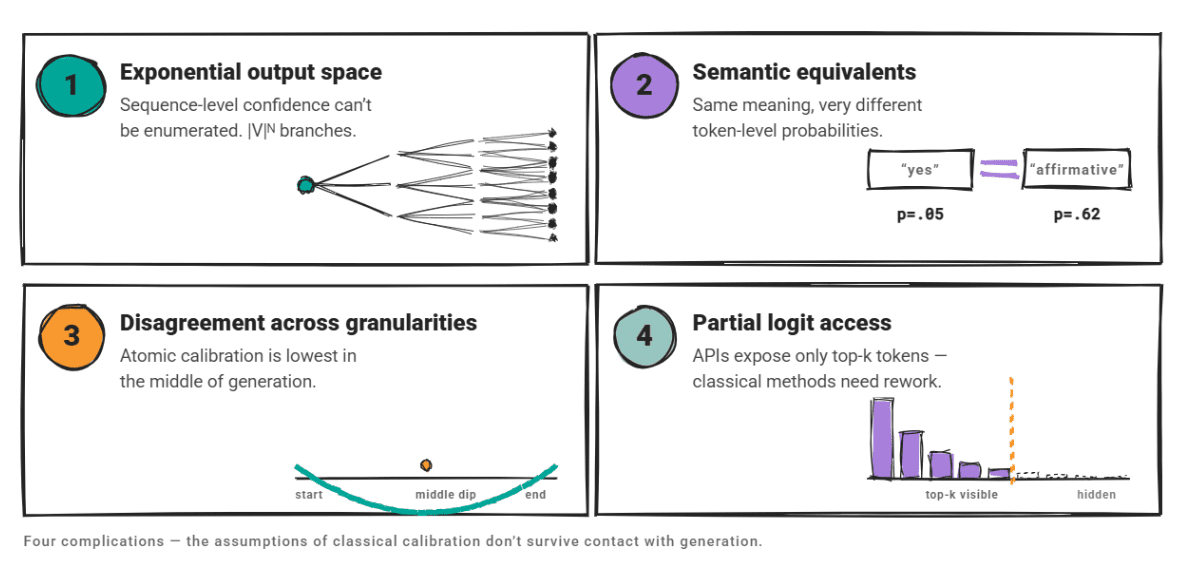
Since the output space is exponentially large, it is not possible to enumerate sequence-level confidence. Semantically equivalent outputs may have very different token-level probabilities. Reliability depends on granularity. In a research paper on atomic calibration, we showed that generative models have the lowest average confidence in the middle of generation, rather than at the beginning or end of generation.
And many LLMs only expose the probabilities of the top k tokens. APITherefore, traditional calibration approaches that rely on full logit access need to be modified.
# Applying temperature scaling
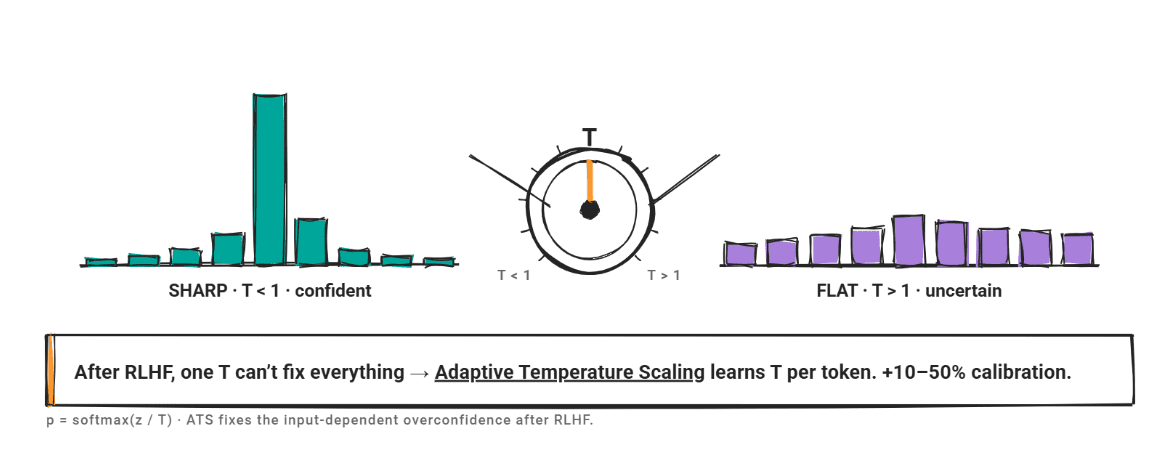
For temperature scaling, divide the logit vector by the scalar T before applying the softmax. When T > 1, the distribution becomes flat and less reliable. When T < 1, the distribution becomes sharper and more reliable.
T fits the retained validation set by minimizing the negative log-likelihood. This method adds one parameter, maintains the predicted ranking, and is computationally inexpensive.
The original formulation was targeted at DenseNet image classifiers. For LLM, the same logic applies since temperature controls the probability distribution over the vocabulary at each decoding step.
The problem is Reinforcement learning from human feedback (RLHF). Models after RLHF suffer from input-dependent overconfidence. This means that the degree of miscalibration varies depending on the input, and a single T cannot account for that variation.
Average ECE scores for models such as GPT-3 on verbalized confidence tasks have been documented to be greater than 0.377, and a 2025 study confirms that RLHF-adjusted models consistently overestimate confidence overall.
Adaptive temperature scaling (ATS) directly addresses this. Rather than using a single fixed T, ATS predicts the temperature per token from token-level hidden features fitted to a supervised fine-tuning dataset. Researchers found that ATS improved calibration by 10-50% without compromising task performance. For RLHF-adjusted models, ATS is a stronger baseline than standard temperature scaling.
Standard temperature scaling continues to work on base models prior to RLHF. If the miscalibration is approximately uniform across the input, a single T is often sufficient to correct systematic overconfidence or underconfidence.
This problem is specific to RLHF and later models, where input-dependent overconfidence means that a single T cannot correct all inputs.
# Applying plat scaling
Platt scaling fits a logistic function to the uncalibrated scores: p = σ(A·s + B). Here, A and B are learned from a retained validation set containing binary accuracy labels.
The sigmoid shape provides parametric mapping with two free parameters.
Although Platt scaling was originally developed for SVMs, it generalizes to any system that produces scalar confidence scores.
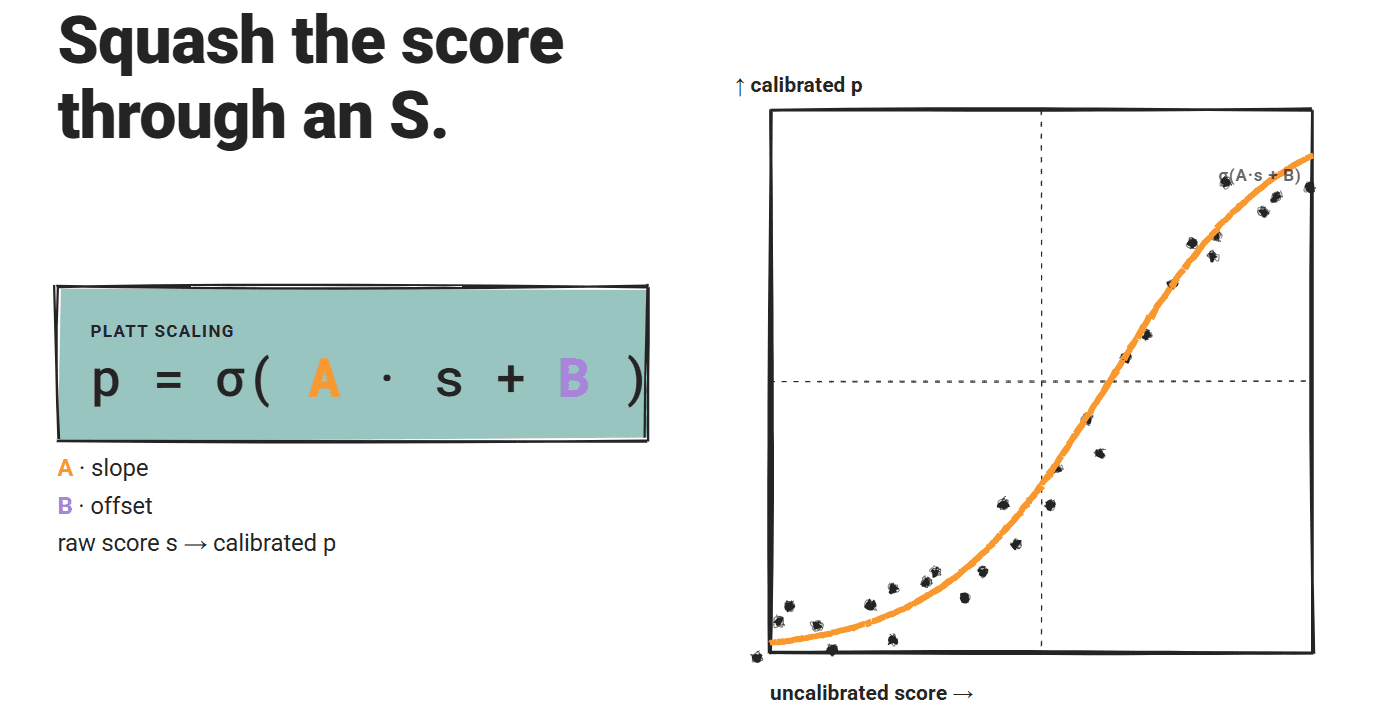
The two-parameter fit is also more data efficient compared to isotonic regression and can produce usable estimates from a smaller calibration set. This becomes important in deployment contexts where labeled accuracy data is limited.
In the LLM context, Platt scaling works on sequence-level or token-level confidence scores.
A paper on the reliability of LLM-generated codes found that Platt scaling produced better calibrated output than unadjusted scores. Another study on LLM for text-to-SQL introduced Multivariate platform scaling (MPS), which extends single-variable Platt scaling to combine subclause frequency scores across multiple generated samples to consistently exceed a single-score baseline.
two Restrictions is documented. First, global sequence-level Platt scaling is too coarse for tasks whose accuracy depends on local editing decisions. A single sigmoid mapping cannot capture sample-dependent false calibration patterns.
Additionally, Platt scaling can reduce the good scoring performance of powerful models.
# Applying isotonic regression
Isotonic regression takes the nonparametric route.
It learns a piecewise constant and monotonically non-decreasing mapping from uncalibrated scores to calibrated probabilities. Pool Adjacent Violator Algorithm (Paba). Because the calibration function has no assumed shape, it is more flexible than Platt scaling when the relationship between reliability and accuracy is not sigmoidal.
Piecewise constant output accommodates any monotonic shape, such as linear, stepped, or concave. This adaptability is the main reason why isotonic regression tends to outperform Platt scaling in empirical comparisons.
The trade-off is that small calibration sets run the risk of overfitting. A mapping will generalize well only if there is enough data to constrain it.
Empirically, isotonic regression is superior to Platt scaling.
Rigorous comparisons across multiple datasets and architectures show that isotonic regression outperforms Platt scaling of ECE and Brier scores with statistical significance using a paired t-test with α = 0.003 and Bonferroni correction.
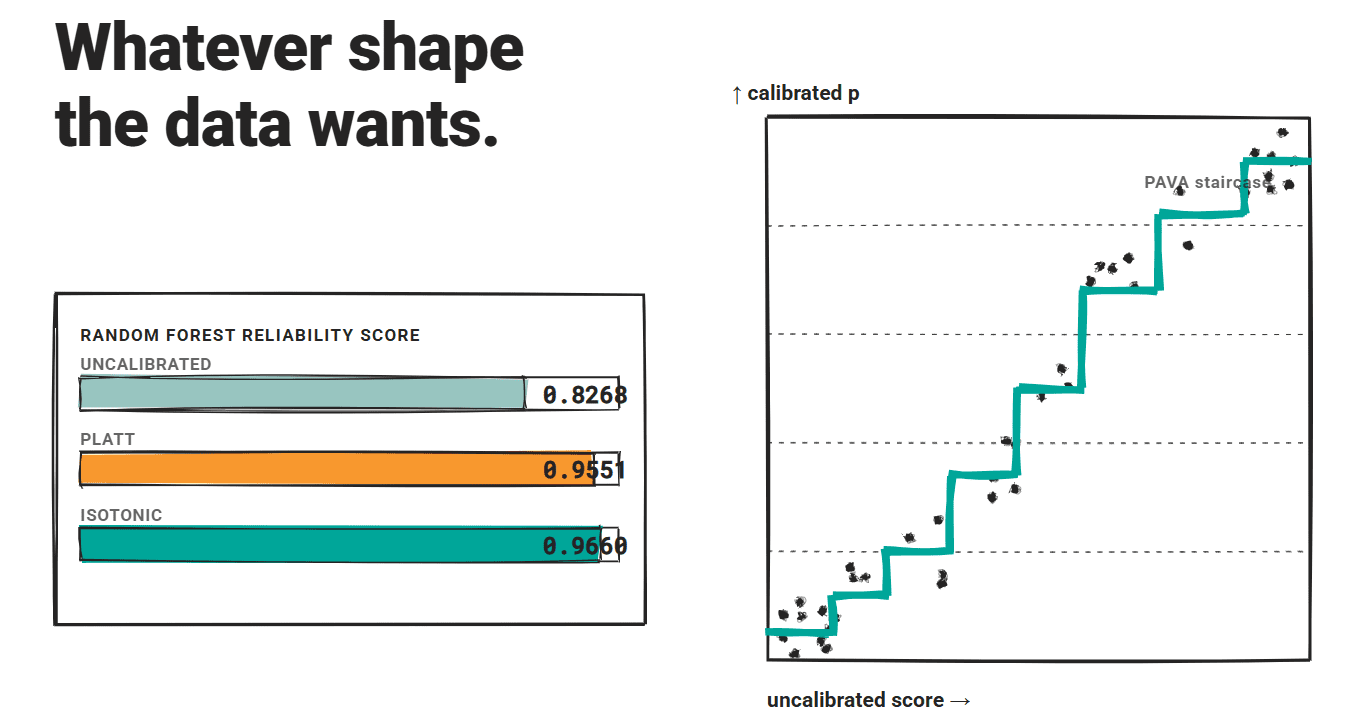
In that study, the random forest baseline improved from an uncalibrated reliability score of 0.8268 to 0.9551 using Platt scaling and 0.9660 using isotonic regression. Both methods could reduce the good scoring performance of strong models, but the isotonic edges were consistently preserved.
For LLM multiclass settings, standard isotonic regression can be further improved using regularization-aware extensions and is shown to consistently outperform both OvR isotonic regression and standard parametric methods in NLL and ECE.
Data requirements are binding constraints. While isotonic regression certainly has its advantages, it does not apply to deployment scenarios with small amounts of data.
# What literature leaves behind
three gap It’s worth flagging these methods before deploying them.
of RLHF Interactions have only been studied for temperature scaling. how plat scaling Isotonic regression performed on the post-RLHF model has not been systematically tested. ATS In this case, it exists because the standard temperature scaling required an explicit modification. It is an open question whether similar extensions are required for the other two methods.
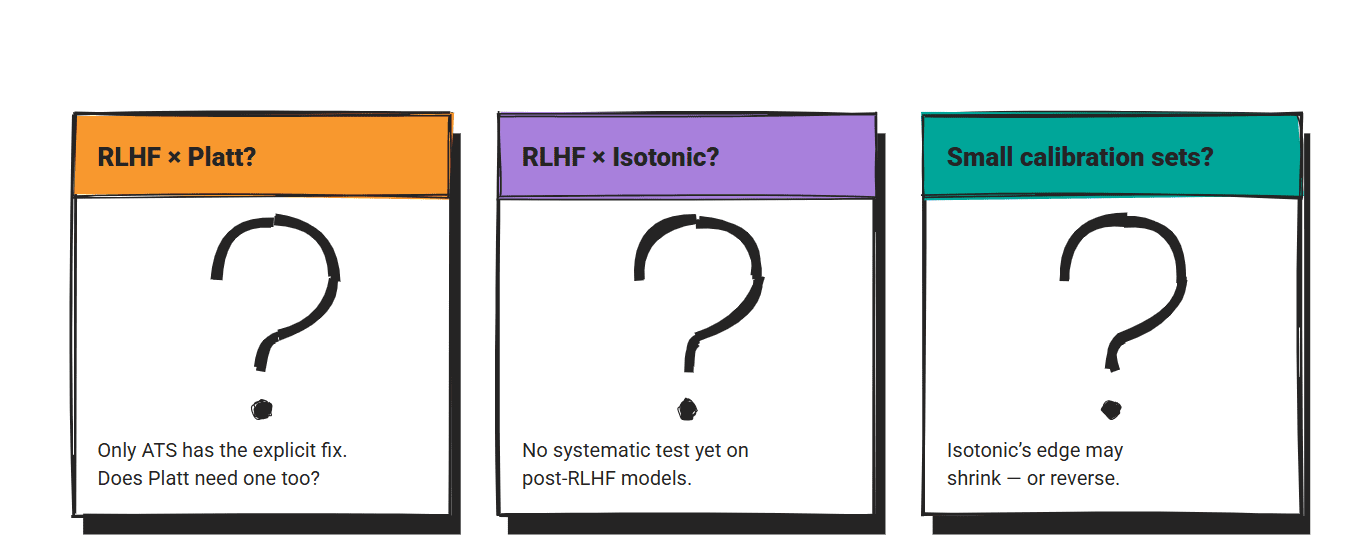
most direct comparison All three methods are drawn from the general machine learning calibration literature. LLM-specific benchmarks that directly test all three are rare. The ICSE 2025 Code Calibration Paper is one of the few and its scope is limited to code generation.
The size of the calibration set is a practical deployment constraint. The isotonic regression results from the paper assume a dataset large enough to constrain the mapping. In a production environment with limited labeled samples, the gap between isotonic regression and Platt scaling may be narrowed or reversed.
# conclusion
temperature scaling For most teams, this is the correct starting point. For basic models without RLHF, a single T is often sufficient.
for RLHF-Switch to adjusted model, ATS: per-token temperature handles input-dependent overconfidence that global scalar misses.
plat scaling It is a practical choice if your calibration set is small or if you need to insert the calibration into a larger pipeline. It is data efficient and easy to implement. The limit is range. It fails to capture miscalibrations that vary between samples and tends to degrade the performance of powerful models.
Isotonic regression It has the strongest empirical track record of the three. Use when the calibration set is large enough to constrain the mapping without overfitting, and combine with the normalization-aware extension in a multiclass setting.
What decisions are made before all this? ”confidence“” means task. Token probabilities, sequence probabilities, verbalized confidence, and sample-to-sample consistency can yield different values for the same output. Calibration techniques applied to the wrong signals do not improve reliability. Getting that definition right is a prerequisite for any of the above techniques to work.
Nate Rossidi I am a data scientist and work in product strategy. He is also an adjunct professor teaching analytics and the founder of StrataScratch, a platform that helps data scientists prepare for interviews by providing real interview questions from top companies. Nate writes about the latest trends in the career market, offers interview advice, shares data science projects, and covers all things SQL.

