
Not everyone has a data center that supports liquid cooling. And not all companies, especially those with data centers in metropolitan areas that need to have all their systems in one place, separate their AI systems from the production systems that build and infer GenAI models.
Additionally, many companies are doing classical machine learning as well as GenAI, and often don’t need rack-scale compute nodes to perform inference. Additionally, if you need rack-scale nodes for training, you can (and often do) rent them from major cloud builders and neoclouds.
The need to stay on-premises for production inference work and small-scale model training is especially acute for hedge funds, algorithmic trading firms, and other types of financial services companies that seek to make money by using machine learning and relatively small GenAI models to analyze what’s happening in the market and make split-second decisions that humans don’t have the processing speed or reflexes for. What is true for FSI companies is equally true for companies in manufacturing, distribution, life sciences, and other industries. They don’t have a data center where they can unload and cool a single rack that consumes 145 kilowatts. Despite the inefficiencies involved, AI systems should be distributed just like general-purpose infrastructure.
All of this comes down to the fact that there is still a need for air-cooled GPU systems. I talked about this in detail here and there last summer. And to that end, AMD has looked into the bin of Instinct MI350 series GPUs and created a half-capacity version of the MI350X with a retro PCI-Express form factor that can connect to standard server form factors. As you might have guessed, the new card is called MI350P and is available now.
When we first heard about the future PCI-Express variant of the MI350 series, we thought it would be recycled from a box of finished MI350X and MI355X parts running at a uniform 2.2 GHz and only half of the HBM3E memory stack running. If AMD were doing a bin sort, we would expect the compute cores and HBM memory capacity to be sold spread out, rather than just one configuration. However, the capacity of MI350P is exactly half that of MI350X. That’s because the MI350P is a chip package with half the components in a smaller socket. This is absolutely done on purpose to allow the device to be air cooled while still offering all the benefits of the CDNA 4 architecture that debuted with the MI350 series launch in June 2025. So this is half a package, not half a failure. It will look like this:

Key features common to the MI350 series lineup include the use of 12 high stacks of HBM3E memory and a CDNA 4 compute complex that supports OCP-FP8, MXFP6, and MXFP4 data formats, increasing the GPU’s effective throughput for both training and inference.
The specifications of MI350P are as follows.

What’s interesting about these specs (as opposed to what we see on MI300 series and MI350 series devices, which use the OAM form factor and also provide memory coherency between interconnected GPUs and CPUs) is that AMD is showing the actual number of flops and the theoretical peak number of flops at each precision. We don’t know what benchmark tests AMD is using, but the company has shown that these trimmed MI350P We’re honest about what you can expect from the card.
As you can see, no matter what these tests were, the MI350P was able to deliver 90 percent of the peak bandwidth of 4 TB/s. In terms of compute, for 16-bit and 8-bit arithmetic, this test offers between 58 percent and 66 percent of peak performance, with MXFP6 offering 58 percent as well, while MXFP4 only delivering 50 percent of peak.
What’s interesting about the MI350P presentation is that AMD is completely honest about how it positions MI350P for running classic machine learning and GenAI inference on Epyc GPUs and Radeon AI Pro cards, as well as air-cooled system boards based on the company’s flagship MI350X and MI355X GPUs, including recommended AI model size limits based on memory and compute.
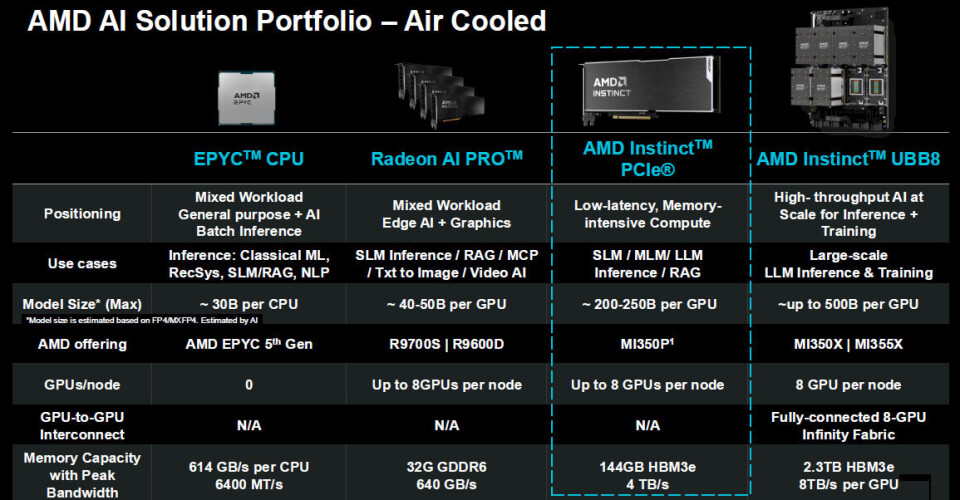
The sweet spot for MI350P is a model with around 200 billion to 250 billion parameters, a perfectly reasonable sized model commonly used by enterprises to power all kinds of data processing and transaction processing.
I like looking at the broader history of computing engines. To that end, here’s a monster table showing the entire Instinct GPU line since MI25 launched in the summer of 2017.
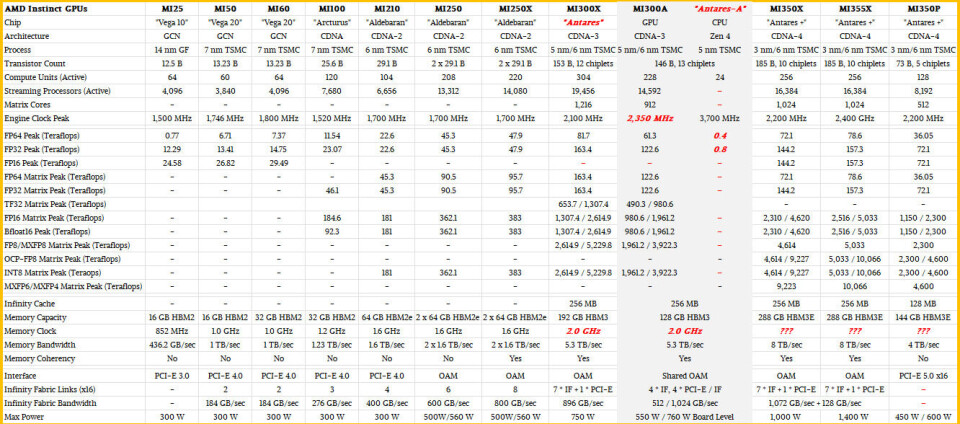
What’s interesting about the MI350P is that it can be tailored to environments and server enclosures that cannot accept large amounts of heat. The MI350P peak performance specifications in the table above assume the GPU is running at 2.2 GHz and the system can dissipate up to 600 watts of heat. However, there is a way to get the MI350P back up to 450 watts. This would result in a 25% power reduction, but probably only a 10% to 15% performance penalty. That means the clock speed will probably only drop to 1.9 GHz to 2 GHz. For memory bandwidth sensitive workloads, the actual performance degradation may be less than 10% since (as far as I know) memory is not slowed down and capacity is not limited.
Given the price per watt and the need for increased performance, it’s reasonable to expect that many of the customers MI350P is targeting will opt for the 450 watt downgrade. It also stands to reason that whatever the list price is for these devices, you want to pay about 10 percent less than the negotiated price.
The usual suspects of OEMs and ODMs are lined up to build MI350P-based systems, with perhaps one or two “Genoa” Epyc 9004 or one or two “Turin” Epyc 9005 CPUs acting as host processors for four or eight MI350Ps in a single node. Dell is pairing its PowerEdge XE7745 and PowerEdge R7725 rack servers with the MI350P, and Hewlett Packard Enterprise is adding them to its ProLiant DL385 and 385a Gen 11 servers and ProLiant DL345 Gen 12 server. Lenovo is adding them to their ThinkSystem SR675/I v3 machines, and Cisco Systems is adding them to their C845a M8, X-Series 580p, and UC245 M8 servers. Supermicro rounds out the OEMs with AS -5126GS-TNRT, AS -5126GS-TNRT2, AS -2026HS-TN, and AS -2116CS-TN machines. I strongly suspect that, like all current GPUs, these will become as rare as a hound’s tooth.
Pricing for the MI350P has not been announced, but it should be less than half the price of the MI350X. MI350P supports memory coherency across the GPU and to the CPU, but MI350P cannot even achieve two-way coherency across the GPU. The MI350P is completely and exclusively standalone, no matter how much you connect it to your machine.


