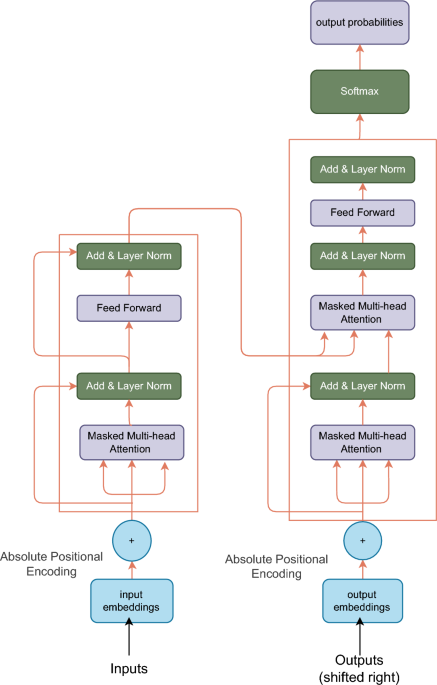
The F-Transformer consists of three layers, i.e., data layer, artificial intelligence layer, and application layer, as shown in Fig. 2. This framework is designed to work cohesively towards the goal of sequence generation with minimum perplexity, understanding long range text dependencies effectively, having less trainable parameter model (light weight) and ensuring privacy through FL.
Novel aspects of the F-Transformer framework
The F-Transformer introduces several unique design choices that distinguish it from existing federated transformer implementations as follows:
-
Firstly, our architectural configuration with 4 attention heads, 4 layers, and 64 embedding dimensions is specifically optimized for FL environments rather than scaled down from larger models. This configuration emerged from systematic exploration of the trade-off between model capacity and communication efficiency in distributed settings.
-
Secondly, we implement a progressive training strategy where local models train for 100 epochs on incrementally arriving data before aggregation, while the global model undergoes 20 aggregation rounds. This specific training schedule balances local adaptation and global generalization differently from standard FL protocols that use fewer local epochs with more frequent aggregation.
-
Thirdly, our privacy mechanism differs from conventional differential privacy implementations by incorporating privacy objectives directly into the loss formulation rather than adding noise to gradients or model updates. The privacy regularization term \(L_{\text {privacy}}(\Theta )\) in Equation 9 operates at the optimization level, influencing model parameter updates throughout training rather than serving as a post-processing privacy filter.
-
Finally, the integration of multiple optimizers (adaptive moment estimation (Adam) and nesterov-accelerated adaptive moment estimation (Nadam)) with our federated setup demonstrates unique convergence properties. Our experiments show that Adam optimizer achieves superior performance in the F-Transformer context compared to standard choices like stochastic gradient descent (SGD), which differs from typical centralized transformer training recommendations. This optimizer selection is specifically tailored to the challenges of distributed gradient aggregation in our framework.
Our compact architecture achieves only 0.87 million trainable parameters through efficient distribution across model components, as detailed in Table 2. The parameter allocation prioritizes essential components while maintaining model expressiveness for sequence generation tasks.
Data layer
The very first and foundation layer of our proposed approach is data layer. It comprises the raw input data, which consists of textual information. This input can range from individual sentences to paragraphs or even entire documents. In accordance with FL principles, the data remains decentralized and is stored locally by the clients. In this section, we discuss the dataset description and data preprocessing steps, which are crucial for the subsequent training phase.
Dataset description
The F-Transformer used the WikiText dataset35, a language modeling dataset with long-term dependencies, to train transformer models. This dataset has been instrumental in helping researchers develop more efficient and sophisticated models. It comprises a extensive collection of Wikipedia texts and articles. A key characteristic of WikiText is its inclusion of long-range dependencies, which refer to relationships between words that are semantically related but appear far apart in a sentence. Although these dependencies are challenging to capture, they contribute to the development of more complex and effective language models. The WikiText dataset has become a standard benchmark for evaluating language model performance especially for efficient sequence generation like tasks.
WikiText-2 consists of 2,088,628 tokens in the training set, with validation and test sets containing 217,646 and 245,569 tokens, respectively. The dataset has a vocabulary size of 33,278 words, providing a rich lexical foundation for our models. The corpus is carefully curated from Wikipedia’s good and featured articles, ensuring high-quality, factually accurate, and well-reviewed text. This selection spans various domains, including literature, history, and science, allowing our model to learn diverse language patterns. To maintain consistency, the text underwent preprocessing using the Moses tokenizer, which handled complex aspects of the original Wikipedia text such as punctuation splitting, number handling, and macro processing. This meticulous preparation of the dataset contributes significantly to the robustness and generalizability of our F-Transformer approach in sequence generation tasks.
Data preprocessing
The initial phase of data preprocessing involves the identification of unique characters within the corpus for input of our Tokenizer36. This tokenization process transforms the raw textual data into a structured sequence of tokens. Following tokenization, we implement a comprehensive text normalization process. This process encompasses several key steps: standardization of textual elements, conversion of all characters to lowercase to ensure uniformity, systematic removal of punctuation to reduce noise, and expansion of contractions to their full forms to improve consistency and quality of our data. Post-normalization, we employ a sophisticated encoding mechanism wherein each token is mapped to a unique numerical identifier. This mapping is based on a carefully curated, pre-defined vocabulary, which serves as a bridge between human-readable text and machine-interpretable numerical data. Train-test-validation token split was already provided by the author of the WikiText-2 dataset.
Artificial intelligence layer
In the second layer of our proposed approach, we discuss the actual implementation that led us to achieving our goal of a privacy-preserving, lightweight, and long-context understanding system. The F-Transformer consists of two main components at its core: Transformers and FL. These components are integrated to perform a specific set of tasks aimed at achieving the system’s objectives.
Transformers
Transformers are DL architectures that are successful in the field of NLP. They were introduced by Vaswani et al. in 20173. Using the self-attention mechanism, transformers easily handle long-range dependencies and derive better probabilities for the predictions of the next term in the sequence. The main components of a transformer are the Encoder, Decoder, self-attention mechanism, and feed-forward neural network. The F-Transformer retains the standard transformer architectural structure shown in Fig. 1, but employs optimized hyperparameters for federated deployment. Our modifications are parametric rather than structural: we use 4 attention heads compared to 8–16 in standard models, 4 transformer layers instead of 6–12, and 64 embedding dimensions rather than 512–768. These parameter choices achieve the compact 0.87 million parameter count while maintaining the core architectural components that enable effective sequence modeling. The specific configuration is detailed in Table 3. The encoder and decoder are the primary transformer components used to capture and extract features from the text corpus. The encoder does the work of compressing the data into smaller dimensions, and on the other hand, the decoder decompresses the data, deriving useful context from the encoded sequences. However, despite their success, transformers have limitations, such as high computational and memory costs, especially during training, which require substantial hardware resources. Additionally, they struggle with scaling for extremely long sequences and understanding hierarchical structures in language, which may impact performance on certain tasks such as sequence generation with long contextual understanding.
Self-attention mechanism
The self-attention mechanism in transformers calculates attention weights by comparing each token \(x_i \in \mathbb {R}^d\) to all others in the input sequence \(X = {x_1, x_2,…, x_n}\). It derives query Q, key K, and value V representations from the input embeddings, computes attention scores through dot products, and obtains attention weights using the softmax function. Let’s discuss each step in detail. Q, K, and V derivation happens from the input embeddings through linear transformations: \(Q = XW_Q\), \(K = XW_K\), and \(V = XW_V\), where \(W_Q, W_K, W_V \in \mathbb {R}^{d \times d_k}\) are learnable parameter matrices. The mechanism computes attention scores \(S \in \mathbb {R}^{n \times n}\) through scaled dot products as shown in Eq. 15.
$$\begin{aligned} S = \frac{QK^T}{\sqrt{d_k}} \end{aligned}$$
(15)
where \(d_k\) is the dimension of the key vectors. The attention weights \(A \in \mathbb {R}^{n \times n}\) are then obtained using the softmax function as depicted in Eq. 16. Then these weights are applied to the values, and the resulting weighted values are summed to produce the output \(Z \in \mathbb {R}^{n \times d_k}\) as shown in Eq. 17
$$\begin{aligned} A = \text {softmax}(S) = \frac{\exp (S)}{\sum _{j=1}^n \exp (S_{ij})} \end{aligned}$$
(16)
$$\begin{aligned} Z = AV \end{aligned}$$
(17)
This mechanism allows transformers to capture dependencies across the entire sequence, assigning higher weights \(a_{ij}\) to more relevant tokens \(x_j\) when computing the representation for token \(x_i\). The self-attention function can be succinctly expressed as:
$$\begin{aligned} \text {Attention}(Q, K, V) = \text {softmax}\left( \frac{QK^T}{\sqrt{d_k}}\right) V \end{aligned}$$
(18)
Figure 3 explains the concept of connecting long-term dependencies by the use of the attention mechanism.

Positional encoding
Positional encoding is a crucial component in transformer architectures which maps each position p (where, \(p \in {1, 2,…, n}\)) in a sequence of length n to a vector representation \(PE(p) \in \mathbb {R}^d\), where d is the model’s dimension. This scheme enables the model to incorporate sequence order information, which is inherently lost in the self-attention mechanism. Let \(X \in \mathbb {R}^{n \times d}\) be the input embedding matrix. The positional encoding \(PE \in \mathbb {R}^{n \times d}\) is element-wise added to X to yield the position-aware input representation \(\tilde{X}\):
$$\begin{aligned} \tilde{X} = X + PE \end{aligned}$$
(19)
It involves adding fixed sinusoidal functions of different frequencies and phases to the word embeddings. These sinusoidal functions encode the relative positions of the words in the sequence. Therefore, the output of the positional encoding layer is a matrix, where each row of the matrix represents an encoded object of the sequence summed with its positional information. Eq. 20 represents the calculations done in positionally encoding the sequences.
$$\begin{aligned} PE_{(pos, 2i)} = \sin \left( \frac{{pos}}{{10000^{(2i/d)}}}\right) \end{aligned}$$
(20)
where the notations are defined as follows:
-
pos: The position of the element in the sequence.
-
i: The dimension index in the positional encoding.
-
d: The dimension of the model or hidden representation.
Multi-head attention
MHA extends the single-head self-attention mechanism by allowing the model to jointly attend to information from different representation subspaces and information with long-range dependency. Let \(X \in \mathbb {R}^{n \times d}\) be the input sequence of n tokens with dimension d. The MHA operation with h heads is defined as:
$$\begin{aligned} \text {MultiHead}(X) = [\text {head}_1; \ldots ; \text {head}_h]W^O \end{aligned}$$
(21)
where \([\cdot ; \cdot ]\) denotes concatenation along the feature dimension, and \(W^O \in \mathbb {R}^{hd_v \times d}\) is a learnable projection matrix. Each head \(\text {head}_i\) operates on a different subspace of the input:
$$\begin{aligned} \text {head}_i = \text {Attention}(XW_i^Q, XW_i^K, XW_i^V) \end{aligned}$$
(22)
with \(W_i^Q, W_i^K \in \mathbb {R}^{d \times d_k}\) and \(W_i^V \in \mathbb {R}^{d \times d_v}\) being head-specific projection matrices. The attention function for each head can be seen in Eq. 18

FL with transformers in NLP.
Federated learning
FL adaptation to the transformer model provides our framework with the necessary elements to address optimization and generalization challenges. Let \(\mathcal {M}\) denote the global model and \(\mathcal {C} = {c_1, c_2,…, c_K}\) represent the set of K clients (here, K=5). Each client \(c_i\) has a local dataset \(\mathcal {D}_i\). The objective of FL is to minimize the global loss function is shown in Eq. 23.
$$\begin{aligned} \mathcal {L}(\mathcal {M}) = \sum _{i=1}^K \frac{|\mathcal {D}_i|}{\sum _{j=1}^K |\mathcal {D}_j|} \mathcal {L}_i(\mathcal {M}) \end{aligned}$$
(23)
where, \(\mathcal {L}_i(\mathcal {M})\) is the local loss function for client \(c_i\). This approach preserves data privacy while enabling collaborative learning, minimizing communication costs, give us light weighted high performance model which can understand long-contextual information.
FL offers significant advantages compared to other traditional methods of centralized learning. FL combats centralised learning systems’ privacy and security concerns by keeping their data on local machines. The model updates (first layer weights) are shared in the system, ensuring the data remains secure. Model privacy and intellectual property can be protected using methods like model pruning, model watermarking, and model encryption. Further, FL avoids transmitting raw data. This encrypted data reduces data breaches as described by37.
Client selection and data partitioning
For the WikiText dataset, we employ a strategic client selection process. Let N be the total number of data samples, and \(K=10\) be the number of clients. We partition the data such that each client \(c_i\) has a dataset \(\mathcal {D}_i\) with:
$$\begin{aligned} |\mathcal {D}_i| = \frac{N}{K} + \delta _i \end{aligned}$$
(24)
where \(\delta _i\) represents the incremental data added to client i over iterations. The incremental learning aspect is captured by defining a time-dependent dataset size:
$$\begin{aligned} |\mathcal {D}_i^t| = |\mathcal {D}_i^{t-1}| + \Delta _i^t \end{aligned}$$
(25)
where t is the current iteration and \(\Delta _i^t\) is the increment in data for client i at iteration t. It is important to clarify that our incremental strategy refers to dataset expansion rather than continual learning with data replacement. In each training round, client \(c_i\) trains its local model on the complete accumulated dataset \(\mathcal {D}_i^t\), not solely on the newly arrived data \(\Delta _i^t\). This accumulation-based approach naturally prevents catastrophic forgetting, as the model continuously trains on all historical data alongside new samples. The local training objective for client i at iteration t is:
$$\begin{aligned} \mathcal {L}_i^t(\Theta ) = \frac{1}{|\mathcal {D}_i^t|} \sum _{(x,y) \in \mathcal {D}_i^t} \mathcal {L}(x, y; \Theta ) \end{aligned}$$
(26)
This formulation ensures that knowledge from earlier data remains preserved as new data arrives, since gradient updates consider the entire accumulated dataset. Our approach is suitable for scenarios where clients have sufficient storage to maintain their data history, which is common in applications like document processing, code repositories, or institutional text corpora. For memory-constrained environments where data must be discarded after processing, additional techniques such as selective experience replay, knowledge distillation, or regularization-based methods like Elastic Weight Consolidation would be necessary to mitigate catastrophic forgetting.
Model training and aggregation
The FL process follows an iterative approach as described in Algorithm 1 . Let \(\mathcal {M}^t\) denote the global model at iteration t, and \(\mathcal {M}_i^t\) represent the local model for client \(c_i\) at iteration t. The training process can be described as follows:
1. Initialization:
$$\begin{aligned} \mathcal {M}_i^0 = \mathcal {M}^0, \forall i \in \{1,…,K\} \end{aligned}$$
(27)
2. Local Update: For each client \(c_i\), update the local model:
$$\begin{aligned} \mathcal {M}_i^t = \mathcal {M}_i^{t-1} – \eta \nabla \mathcal {L}_i(\mathcal {M}_i^{t-1}) \end{aligned}$$
(28)
where \(\eta\) is the learning rate and \(\nabla \mathcal {L}_i\) is the gradient of the local loss function.
3. Aggregation: Update the global model using FedAvg:
Let, \(\theta ^t\) denote the parameters of the global model \(\mathcal {M}^t\) at iteration t, and \(\theta _i^t\) denote the parameters of the local model \(\mathcal {M}_i^t\) for client i at iteration t. The FedAvg algorithm can be described as follows:
$$\begin{aligned} \theta ^{t+1} = \theta ^t + \eta \sum _{i=1}^K \frac{n_i}{n} (\theta _i^t – \theta ^t) \end{aligned}$$
(29)
where:
-
\(\eta\) is the server learning rate
-
\(n_i = |\mathcal {D}_i^t|\) is the number of samples in the dataset of client i at iteration t
-
\(n = \sum _{i=1}^K n_i\) is the total number of samples across all clients
-
K is the number of clients participating in the current round
For transformer models, \(\theta\) represents the set of all trainable parameters:
$$\begin{aligned} \theta = \{\textbf{W}_Q, \textbf{W}_K, \textbf{W}_V, \textbf{W}_O, \textbf{W}_{FFN}, \textbf{b}_{FFN}\} \end{aligned}$$
(30)
The local update for each client i is performed using various optimization algorithms including NAdam, SGD, root mean square propagation (RMSProp), adaptive gradient algorithm (AdaGrad), Adam. Where, NAdam and Adam have out performed all the other optimization algorithms for both client model and global model.
4. Model Distribution:
$$\begin{aligned} \mathcal {M}_i^t = \mathcal {M}^t, \forall i \in \{1,…,K\} \end{aligned}$$
(31)
This process is repeated until convergence, defined as:
$$\begin{aligned} \Vert \mathcal {M}^t – \mathcal {M}^{t-1}\Vert _2 < \epsilon \end{aligned}$$
(32)
where \(\epsilon\) is a predefined threshold. The local loss function \(\mathcal {L}_i\) for each client incorporates both the standard cross-entropy loss for next token prediction and a regularization term to prevent overfitting:
$$\begin{aligned} \mathcal {L}_i(\mathcal {M}_i^t) = -\frac{1}{|\mathcal {D}_i^t|} \sum _{(x,y) \in \mathcal {D}_i^t} \log p(y|x; \mathcal {M}_i^t) + \lambda \Vert \mathcal {M}_i^t\Vert _2^2 \end{aligned}$$
(33)
where (x, y) are input-output pairs in the dataset, \(p(y|x; \mathcal {M}_i^t)\) is the probability of the correct output given the input and the model, and \(\lambda\) is the regularization coefficient.
Handling non-IID data distributions
A critical challenge in FL is the non-IID nature of client data, where different clients may have substantially different data distributions. While our WikiText-2 experimental setup employs relatively homogeneous data through sequential partitioning, the F-Transformer architecture incorporates several mechanisms that facilitate handling of heterogeneous data distributions in real-world deployments. The FedAvg aggregation strategy with dataset-size weighting naturally accounts for client heterogeneity. As shown in Equation 29, the global model update weights each client’s contribution proportionally to \(\frac{n_i}{n}\), where \(n_i = |\mathcal {D}_i^t|\) is the local dataset size. This ensures that clients with more representative or larger datasets have appropriate influence on the global model, mitigating the impact of clients with sparse or atypical data distributions.
The compact model architecture provides additional benefits for non-IID scenarios. With only 0.87 million parameters, the model has limited capacity to overfit to any single client’s local distribution during the 100 local training epochs. This architectural constraint encourages learning of generalizable features that transfer across clients rather than memorizing client-specific patterns. In contrast, larger transformer models with hundreds of millions of parameters are more susceptible to catastrophic overfitting on non-IID local datasets. The regularization term in our local loss function (Equation 33) further prevents overfitting to local data distributions. The L2 regularization with coefficient \(\lambda\) penalizes extreme parameter values that might result from aggressive fitting to non-representative local data. This regularization is particularly important when clients have limited or skewed data samples.
For scenarios with severe non-IID distributions, additional techniques can be integrated into our framework. These include client clustering based on data distribution similarity, personalized local model components that adapt to client-specific patterns while sharing global knowledge, or dynamic learning rate adjustment based on the divergence between local and global model parameters. The modular design of our framework allows such extensions without fundamental architectural changes. It is important to acknowledge that our current experimental evaluation on WikiText-2 does not fully exercise these non-IID handling capabilities. The sequential data partitioning creates relatively balanced distributions across clients. Future work should include comprehensive evaluation on genuinely heterogeneous datasets representing varied linguistic styles, regional dialects, domain-specific vocabularies, or imbalanced data quantities across clients to empirically validate the framework’s robustness under non-IID conditions.
Application layer
The final attribute of the F-Transformer is the application layer. It serves as a crucial interface between the AI-generated outputs and real-world applications. This framework section provides the optimized output generated by the AI layer, which must be sent to multiple institutions across various domains. The base language model, typically a variant of the transformer architecture such as BERT, GPT, or T5, is employed in NLP tasks such as text and sequence generation where multiple devices in an area, such as personal computers, mobile phones, or IoT devices, can train a sequence generator model locally in a synergetic fashion. The centralized model thus aggregates the updates and forms a robust and generalized system for the task. This process forms a robust and generalized system for the task, leveraging the collective knowledge of distributed devices while maintaining data privacy. Furthermore, the framework incorporates adaptive mechanisms to generate optimized outputs tailored to the varied requirements of multiple institutions. These adaptations may include:
-
Dynamic model pruning to optimize for different computational constraints.
-
Multi-task learning to simultaneously address multiple related NLP tasks.
-
Meta-learning techniques to quickly adapt to new domains or languages with minimal fine-tuning.
Consider language translation as a task that multiple institutions demand; the federated integrated transformer can be particularly beneficial in this context. Federated transformers can help build an improved translation model that incorporates data from many diverse language pairs, leveraging techniques such as multilingual pretraining and zero-shot translation. This approach provides more accurate and culturally nuanced translations compared to a centralized framework, especially for low-resource languages. The application of FL with transformers in NLP extends far beyond translation. Some advanced applications include:
-
Personalized language models: Adapting to individual users’ writing styles and preferences while preserving privacy.
-
Cross-silo FL for document categorization in sensitive industries like healthcare or finance.
-
Federated question answering systems that can access distributed knowledge bases without centralizing sensitive information.
-
Privacy-preserving named entity recognition for applications in legal or medical domains.
-
Multilingual sentiment analysis that respects regional language variations and cultural contexts.
Moreover, the F-Transformer framework can be extended to incorporate recent advancements in NLP, such as:
-
Few-shot learning38 capabilities to quickly adapt to new tasks with limited labeled data.
-
Integration of external knowledge graphs39 to enhance reasoning capabilities.
-
Adversarial training40 techniques to improve model robustness against potential attacks.
-
Differential privacy mechanisms41 to provide formal privacy guarantees in federated settings.
The FL technique, combined with SOTA transformer architectures, makes developing effective and private NLP applications possible, allowing collaborative model training while protecting data privacy. This approach not only addresses current challenges in data silos and privacy concerns but paves the way for more inclusive and diverse AI systems that can benefit from global knowledge while respecting local contexts and regulations.


