
The open model is driving a new wave of on-device AI, extending innovation beyond the cloud and into everyday devices. As these models advance, their value will increasingly depend on access to local, real-time context that can translate meaningful insights into action.
Google’s latest features designed for this shift gemma 4 family Introducing a class of small, fast, omni-enabled models built for efficient local execution across a variety of devices.
google and NVIDIA collaborated to optimize Gemma 4 Available for NVIDIA GPUs, it delivers efficient performance across a variety of systems, from data center deployments to NVIDIA RTX-powered PCs and workstations, NVIDIA DGX Spark personal AI supercomputers, and NVIDIA Jetson Orin Nano edge AI modules.
Gemma 4: Compact model optimized for NVIDIA GPUs
Latest additions Open model of the Gemma 4 family— Across E2B, E4B, 26B, and 31B variants — Designed for efficient deployment from edge devices to high-performance GPUs.
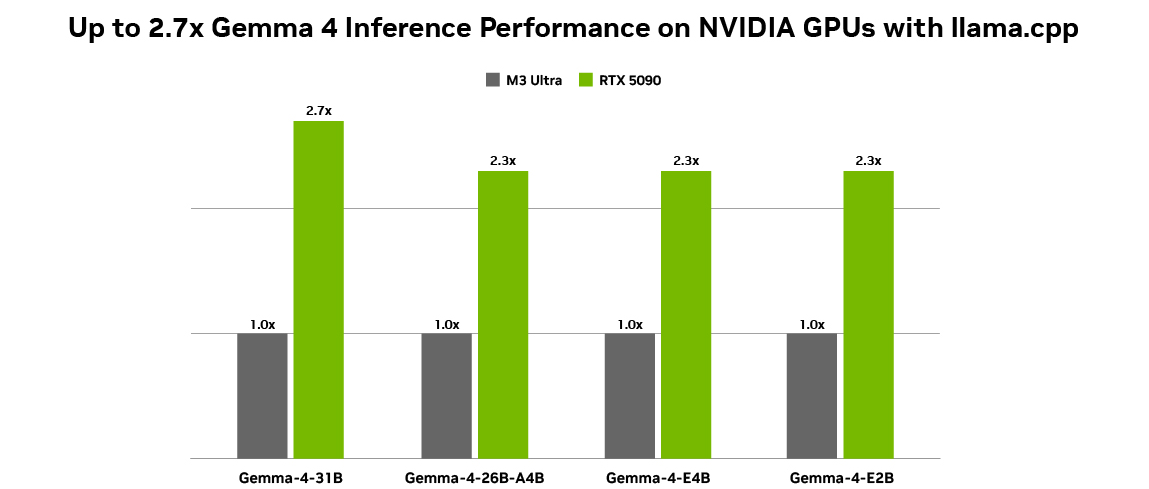
This new generation of compact models supports a variety of tasks, including:
- inference: Superior performance in complex problem-solving tasks.
- coding: Code generation and debugging for developer workflows.
- agent: Native support for using structured tools (function calls).
- Vision, video and audio functions: EEnables rich multimodal interactions for object recognition, automatic speech recognition, and document or video intelligence.
- Interleaved multimodal input: MYou can enter text and images in any order within a single prompt.
- Multilingual: It supports 35+ languages out of the box and is pre-trained in 140+ languages.
of E2B and E4B models Built for ultra-efficient, low-latency inference at the edge, it runs completely offline with near-zero latency across many devices, including Jetson Nano modules.
of 26B and 31B modelsDesigned for high-performance inference and developer-centric workflows, it’s ideal for agent AI. Optimized to provide cutting-edge, accessible inference, these models run efficiently on NVIDIA RTX GPUs and DGX Spark, powering development environments, coding assistants, and agent-driven workflows.
As local agent AI gains momentum, applications such as: open claw We enable always-on AI assistants on RTX PCs, workstations, and DGX Spark. The latest Gemma 4 models are compatible with OpenClaw, allowing users to build capable local agents that automate tasks by drawing context from personal files, applications, and workflows. learn how to run Free OpenClaw on RTX GPUs and DGX Spark or DGX Spark OpenClaw Playbook.
Introduction: Gemma 4 on RTX GPU and DGX Spark
NVIDIA collaborated with Ollama and llama.cpp to provide the best local deployment experience for each Gemma 4 model.
To use Gemma 4 locally, users can: download orama To run the Gemma 4 model or install llama.cpp Combine it with the Gemma 4 GGUF Hugging Face checkpoint. moreover, Unsloth provides day-one support with optimized and quantized models for efficient local fine-tuning and deployment via Unsloth Studio. start running and Fine adjustment Today I’m Gemma 4 from Unsloth Studio.
Running open models like the Gemma 4 family on NVIDIA GPUs delivers optimal performance as NVIDIA Tensor Cores accelerate AI inference workloads, increasing local execution throughput and reducing latency. Additionally, the CUDA software stack ensures broad compatibility across major frameworks and tools, allowing new models to run efficiently from day one.
This combination allows open models like Gemma 4 to scale across a wide range of systems, from Jetson Orin Nano at the edge to RTX PCs, workstations, and DGX Spark, without the need for extensive optimization.
check out of NVIDIA Technology Blog Learn more about how to get started with Gemma 4 on NVIDIA GPUs, and NVIDIA initiatives open model.
#ICYMI: Latest updates for RTX AI PC
✨ I’ll catch up RTX AI Garage We’ll be blogging about many Agent AI announcements from NVIDIA GTC, including a new open model for local agents. These models include NVIDIA Nemotron 3 Nano 4B and Nemotron 3 Super 120B with Qwen 3.5 and Mistral Small 4 optimizations.
NVIDIA recently introduced NVIDIA Nemo Crow, An open source stack that optimizes the OpenClaw experience on NVIDIA devices by increasing security and supporting local models.
🚀 Accomplish.ai We announced Accomplish FREE, a free version of our open source desktop AI agent with built-in models. NVIDIA GPUs are leveraged to run open weight models locally, while the hybrid router dynamically balances workloads between local RTX hardware and the cloud, enabling fast, private, zero-configuration execution without the need for application programming interface keys.
Plug into your NVIDIA AI PC. facebook, Instagram, TikTok and × — Subscribe to stay up to date RTX AI PC Newsletter.
Follow NVIDIA Workstation linkedin and ×.

