
A major development in generative AI is AI-powered video generation. Before the advent of AI, creating dynamic video content required extensive resources, technical expertise, and significant manual labor. Although AI models can now generate videos from simple inputs, organizations still face challenges such as unpredictable results. In this post, we introduce Video Retrieval-Augmented Generation (V-RAG), an approach to improve video content creation. By combining search augmented generation with advanced video AI models, V-RAG provides an efficient and reliable solution for generating AI videos.
video generation
AI video generation represents a revolutionary frontier in digital content creation, enabling the automated production of dynamic visual narratives without the need for traditional filming or animation processes. By using deep learning architectures, these systems can synthesize realistic and stylized video sequences. Unlike traditional video production, which requires cameras, actors, and extensive post-production, AI generation creates content entirely through a computational process that analyzes patterns from large training datasets to render a consistent visual story. This technology allows individuals and organizations to create visual content with minimal technical expertise, reducing the time, resources, and specialized skills traditionally required. As these models continue to evolve, they promise to fundamentally reshape how visual stories are conceived, produced, and shared across industries from entertainment and marketing to education and communications.
Text to video generation
Text-to-video generation creates dynamic video content from narrative or thematic text prompts. This technology interprets text descriptions and transforms them into a coherent visual sequence that follows a specified narrative. While text prompts can effectively guide the overall theme and storyline, they may not be sufficient to accurately capture very specific visual details. Text-to-Video serves as the basis for AI video creation, allowing users to generate content based solely on descriptive language.
Customize video generation
Text prompts alone have limitations when it comes to video generation. Control is inherently limited when relying solely on textual explanations, as the model may ignore important parts of the prompt or interpret it differently than intended. Certain visual concepts have proven difficult to explain with words alone, and are further limited by the model’s token limitations, which limit how detailed the instructions can be. This is where further customization becomes very important. Robust customization tools allow users to specify style, mood, complex visual aesthetics, and many other parameters beyond what can be effectively conveyed in text. These controls help overcome the limitations of text prompts by providing a direct mechanism to influence the output. Without these features, creators would expect the model to correctly interpret their intentions, rather than actively directing the creative process. Customization bridges the gap between fuzzy generation and precise visual control, making AI video tools truly useful for professional applications.
Fine-tuning the model
Fine-tuning adapts a pre-trained video generation model to a specific domain, style, or use case. This process allows organizations to create specialized video generators that excel at tasks such as creating product demonstrations with consistent branding, generating medical education content, or creating videos in a unique artistic style. Fine-tuning typically involves further training an existing model on a carefully curated dataset representing the target domain, allowing the model to learn the unique visual patterns, movements, and style elements needed for specialized applications. However, fine-tuning video generation models presents significant challenges. The basic hurdles start with data acquisition, as high-quality video data suitable for training is expensive and difficult to obtain. Organizations require a variety of well-labeled footage in specific formats that cover specific use cases while meeting technical quality standards. The computational demands are substantial and represent a major barrier to entry. Performing a single fine-tuning requires multiple high-end GPUs to operate continuously, and retraining to incorporate new features doubles the cost with each iteration. Even with perfect data and unlimited computational resources, success is still uncertain due to the interconnected nature of video elements such as consistency, physical precision, illumination consistency, and object persistence. Improvements in one area often lead to unexpected deterioration in other areas, creating complex optimization challenges that are difficult to solve with simple solutions.
image to video
Image-to-video generation complements text-based approaches by providing additional visual control. By using the input image as a reference, users can ensure that certain details such as object color, style, and other attributes are accurately represented in the generated video. For example, if a user wants to feature a red wallet in a video, providing an image of the wallet itself ensures visual fidelity that cannot be achieved with a textual description alone. This technique allows for dynamic movement and integration within the broader narrative context while maintaining coherence and improving rapid compliance through conditioning. Image-to-video generation requires no fine-tuning.
V-RAG: An effective approach to customizing video generation
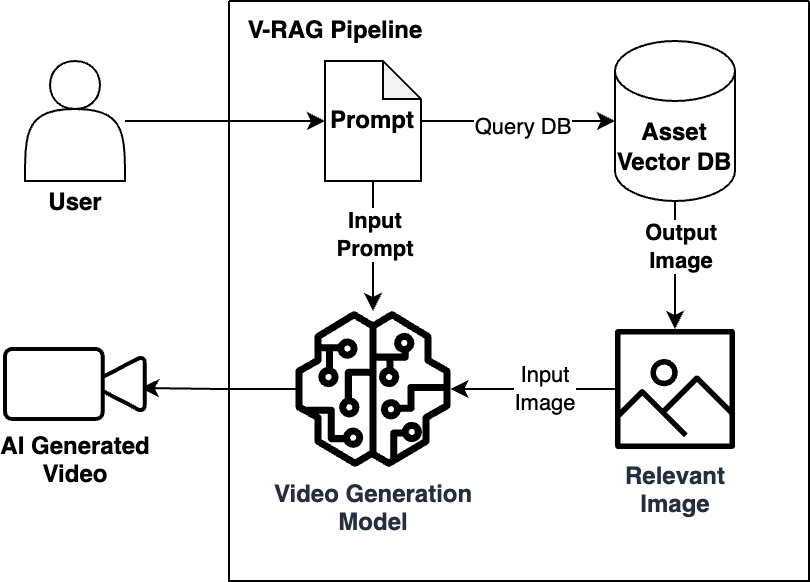
Video Retrieval-Augmented Generation (V-RAG) is built on image-to-video technology and extends video customization capabilities. While traditional image-to-video conversion converts a single reference image into motion, V-RAG extends this functionality by retrieving and incorporating related images from a database to feed video generation. This approach provides several features without requiring model training or retraining. Organizations can quickly start producing customized content by ingesting image collections into vector databases, running queries, and feeding the output into existing video generation models.
V-RAG’s efficiency comes from requiring only still images, which are generally more easily available than video training data. These images can be added to the vector database on the fly, making them instantly available for next-generation tasks without computational delays. All videos generated through this process maintain clear traceability to the source images, creating an auditable trail that enhances verification and debugging capabilities. The system bases the video output on a specific reference image designed to reduce the risk of hallucinations and manage computational costs. Organizations can maintain separate visual knowledge bases for different departments and use cases, streamlining compliance by thoroughly inspecting all source materials before entering the system.
V-RAG logic diagram
The evolving essence of V-RAG
V-RAG is not a fixed technology, but rather represents an evolving framework that is continuously expanded as AI capabilities advance. Although current implementations primarily utilize image databases, the basic search expansion approach is modality agnostic. As multimodal AI models mature, V-RAG systems will naturally incorporate audio samples, video snippets, and 3D models as reference points during generation. Future iterations may support synthesis of complete audiovisual experiences, generation of videos with fully synchronized audio, realistic environmental sounds, and custom musical scores based on captured audio patterns. This flexibility positions V-RAG as a foundational paradigm rather than a specific implementation, allowing it to adapt as broader AI advances while retaining its key benefits of traceability, efficiency, and reduced hallucinations. The ultimate vision extends beyond audiovisual content to the possibility of incorporating interactive elements, creating a comprehensive multimodal production system capable of producing engaging output while being based on reliable reference materials.
Key benefits of V-RAG
Generating video using images acquired through V-RAG offers significant benefits, including improved accuracy, relevance, and contextual understanding. This approach bases the generated content on a specific knowledge base to help guide video creation. This is especially useful for educational, documentary, and explanatory video formats, as it reduces hallucinations and ensures that the video matches the information from the image source. The main benefits of using V-RAG from images are:
- Factual accuracy – Ensure that the video content generated is based on real information, reducing the chance of inaccurate or misleading visuals.
- Contextual relevance – Get more relevant images for a specific topic or query for a more consistent and focused video narrative.
- Dynamic content generation – Enables flexible video creation by dynamically selecting and assembling images based on user input and changing requirements.
- Reduced development time – Use your existing knowledge base to reduce the time required to collect and curate visual assets for video creation.
- Personalized content – Tailor your videos to individual user needs and generate relevant and engaging content.
- Scalability – It is designed to be extensible by bringing additional images into the vector database.
Real-world application of V-RAG
The practical applications of V-RAG are vast and diverse. In the education field, V-RAG can automatically create educational videos by retrieving relevant images from the subject’s knowledge base. For personalized content, V-RAG can tailor video content to individual users by retrieving images based on a user’s specific interests. For marketing, V-RAG can create targeted video ads by capturing images tailored to specific demographics or product characteristics.
conclusion
As AI technology continues to evolve, V-RAG’s flexible framework allows you to incorporate new modalities and features, from advanced audio integration to interactive elements. The AWS implementation shows that organizations can start using this technology through their existing cloud services and make AI video generation accessible to a wider range of users. In the future, V-RAG’s impact on video content creation is likely to expand far beyond its current applications in education and marketing. As this technology matures, it has the potential to make video production more accessible while supporting quality, accuracy, and customization. This approach offers a promising path for AI-powered video generation, allowing organizations to create engaging visual content.
References
understand
We would like to thank Vishwa Gupta, Shuai Cao, and seif for their contributions.
About the author


