In 2019, Google introduced the concept of federated learning (FL) through a cartoon. This is a great piece and did a great job of explaining how the product can be improved without sending user data to the cloud. Lately, I've been interested in understanding the technical aspects of this field in more detail. Training data has become a highly valued commodity because it is essential to building good models, but much of it goes unused because it is fragmented, unstructured, or locked in silos.
When I started exploring this field, I discovered the following: floral framework The easiest and most beginner-friendly way to get started in Florida. It's open source, the documentation is clear, and the community around it is very active and helpful. That's one of the reasons I developed a new interest in this field.
This article is the first in a series that explores federated learning in more depth: what it is, how to implement it, the unresolved issues it faces, and why it's important in privacy-sensitive settings. In the next article, we will discuss the actual implementation in more detail. flowerThe framework discusses privacy in federated learning and considers how these ideas extend to more advanced use cases.
When centralized machine learning isn't ideal
We know that AI models rely on large amounts of data, but much of the most useful data is sensitive, distributed, and difficult to access. Consider data in hospitals, phones, cars, sensors, and other edge systems. Privacy concerns, local rules, storage limitations, and network limitations make it very difficult or impossible to move this data to a central location. As a result, large amounts of valuable data remain unused. In the medical field, this problem is particularly pronounced. Hospitals generate tens of petabytes of data each year, and research shows that up to 97% of this data will remain unused .
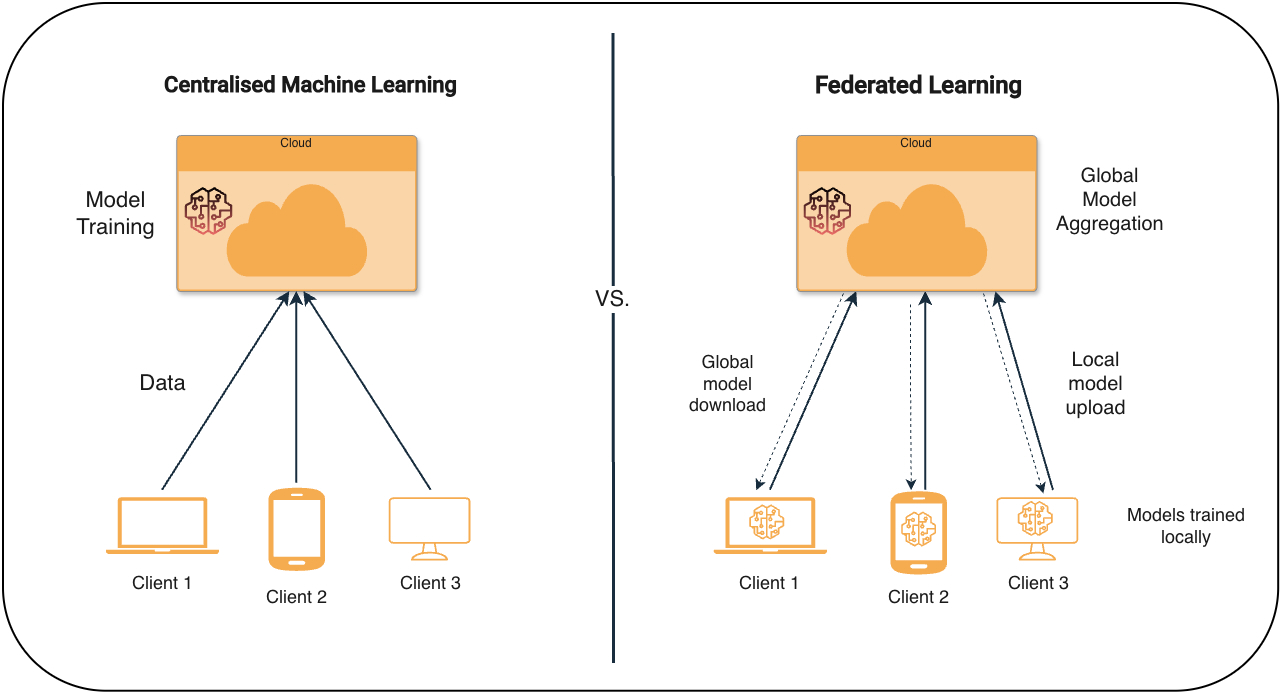
Traditional machine learning assumes that all training data can be collected in one place, typically a centralized server or data center. This works if the data can move freely, but not if the data is private or protected. In practice, centralized training also relies on stable connectivity, sufficient bandwidth, and low latency, which are difficult to guarantee in distributed or edge environments.

In such cases, you will generally be presented with two options. One option is to not use the data at all. This means valuable information remains locked in silos.
Another option is for each local entity to train the model on its own data, sharing only what the model has learned, and the raw data never leaving its original location. This second option forms the basis of federated learning, allowing models to learn from distributed data without moving it. A famous example is Google Gboard on Android. Here you can predict the next word and smart creationRuns across hundreds of millions of devices.
Federated Learning: Move model to data
Federated learning can be thought of as a collaborative machine learning setup that trains without collecting data in one central location. Before we explain how it works under the hood, let's look at some real-world examples that demonstrate why this approach is important in high-risk environments, from healthcare to security-sensitive environments.
health care
In the medical field, federated learning allows Curial AI a system trained in multiple NHS hospitals using routine vital signs and blood tests. Because patient data could not be shared between hospitals, training was done locally at each facility and only model updates were exchanged. The resulting global model generalized better than models trained at individual hospitals, especially when evaluated at unseen facilities.
medical image processing

Federated learning is also being explored in the medical imaging field. Researchers at UCL and Moorfields Eye Hospital are using it to fine-tune large-scale vision-based models with highly sensitive eye scans that cannot be centralised.
defense
Beyond healthcare, federated learning is also being applied in security-critical areas such as defense and aviation. Here the model is trained based on distributed physiological and operational data that must be maintained locally.
Different types of federated learning
Broadly speaking, Federated Learning can be grouped into several general types based on: who is the customerand how the data is divided .
• Cross-device vs. cross-silo federated learning
Cross-device federated learning It involves the use of a large number of clients, potentially in the millions, such as personal devices and phones, each with a small amount of local data and an unreliable connection. However, at a given time, only a small number of devices participate in a given round. Google Gboard is a classic example of this setup.
cross silo federated learning, on the other hand, The number of clients involved is much smaller, typically organizations such as hospitals or banks. Each client holds large datasets and has stable computing and connectivity. Most real-world enterprise and healthcare use cases look like federated learning between silos.
• Horizontal federated learning and vertical federated learning

horizontal federated learning Describes how data is divided between clients. In this case, all clients share the same feature space, but each holds different samples. For example, multiple hospitals may record the same medical variables for different patients. This is the most common form of federated learning.
Vertical federated learning Used when clients share the same set of entities but have different functionality. For example, a hospital and an insurance company may both have data on the same individual for different attributes. In this case, the feature spaces are different, so training requires safe tuning, but this setup is less common than horizontal federated learning.
These categories are not mutually exclusive. Real systems are often described using both axes. Cross-silo, horizontally federated learningsetting.
How Federated Learning works
As shown in the diagram below, federated learning follows a simple iterative process coordinated by a central server and performed by multiple clients that keep their data locally.

Federated Learning training progresses through repetition federated learning rounds. In each round, the server selects a small random subset of clients, sends their current model weights, and waits for updates. Each client trains the model locally using: stochastic gradient descent typically done for multiple local epochs on their own batch, and returns only updated weights. Broadly speaking, follow these five steps.
- Initialization
Global models are created on the server and act as coordinators. The model may be randomly initialized or start from a pre-trained state.
2. Distribution of models
In each round, the server selects a set of clients to participate in training (based on random sampling or a predefined strategy) and sends the weights of the current global model. These clients include phones, IoT devices, or individual hospitals.
3. On-site training
Each selected client trains the model locally using its own data. Data never leaves the client and all calculations are done on the device or within an organization such as a hospital or bank.
4. Model update communication
After local training, the client only sends updated model parameters (such as weights or gradients) back to the server, but the raw data is always shared.
5. totalling
The server aggregates client updates and generates a new global model. meanwhile Federated Averaging (Fed Avg) is a common approach to aggregation, Other strategies are also used. The updated model is then sent back to the client and the process is repeated until convergence.
Federated learning is an iterative process, and each pass through this loop is called a round. Training a federated model typically requires many rounds, even hundreds, depending on factors such as model size, data distribution, and the problem being solved.
The mathematical intuition behind federated averaging
The workflow described above can also be written more formally. The image below shows the original Federated Averaging (Fed Avg) Algorithm from Google's seminal paper. This algorithm later became the main reference point and demonstrated that federated learning actually works. In fact, this formulation has become the reference point for most federated learning systems today.

Original Federated Averaging algorithm. Demonstrates weighted aggregation of server and client training loops and local models.
The core of Federated Averaging is the aggregation step. In this step, the server updates the global model by taking a weighted average of the locally trained client models. This can be written as:

This equation provides clarity on how each client contributes to the global model. Clients with more local data have more influence, while clients with fewer samples contribute proportionally less. In fact, this simple idea is why Fed Avg has become the default baseline for federated learning.
Simple NumPy implementation
Let's look at a minimal example with 5 clients selected. For simplicity, assume that each client has already finished local training and returned updated model weights and the number of samples used. Using these values, the server calculates a weighted sum that produces a new global model for the next round. This directly mirrors the Fed Avg equation without introducing any training or client-side details.
import numpy as np
# Client models after local training (w_{t+1}^k)
client_weights = [
np.array([1.0, 0.8, 0.5]), # client 1
np.array([1.2, 0.9, 0.6]), # client 2
np.array([0.9, 0.7, 0.4]), # client 3
np.array([1.1, 0.85, 0.55]), # client 4
np.array([1.3, 1.0, 0.65]) # client 5
]
# Number of samples at each client (n_k)
client_sizes = [50, 150, 100, 300, 4000]
# m_t = total number of samples across selected clients S_t
m_t = sum(client_sizes) # 50+150+100+300+400
# Initialize global model w_{t+1}
w_t_plus_1 = np.zeros_like(client_weights[0])
# FedAvg aggregation:
# w_{t+1} = sum_{k in S_t} (n_k / m_t) * w_{t+1}^k
# (50/1000) * w_1 + (150/1000) * w_2 + ...
for w_k, n_k in zip(client_weights, client_sizes):
w_t_plus_1 += (n_k / m_t) * w_k
print("Aggregated global model w_{t+1}:", w_t_plus_1)
-------------------------------------------------------------
Aggregated global model w_{t+1}: [1.27173913 0.97826087 0.63478261]
How to calculate aggregation
To put things into perspective, you can expand the aggregation step for just two clients and see how the numbers line up.

Challenges of federated learning environments
Federated learning comes with its own set of challenges. One of the big problems in implementing this is that the data between clients is often non-IID (non-independent and identically distributed). This means that different clients may see very different data distributions, which can result in slower training and less stable global models. For example, hospitals within a federation can serve different populations that can follow different patterns.
Federated systems can involve anything from a few organizations to millions of devices, and as the system grows, joining, dropouts, and aggregation become more difficult to manage.
Federated learning keeps the raw data local, but it's not a complete solution. privacy By itself. If unprotected, even model updates can reveal private information, so additional privacy measures are often required. Finally, communicationThis may cause a bottleneck. This is because networks may be slow or unreliable, and sending updates frequently can be costly.
Conclusion and future developments
In this article, we understood how federated learning works at a high level and also walked through a simple Numpy implementation. However, instead of writing the core logic manually, there are frameworks like Flower that provide a simple and flexible way to build federated learning systems. In the next part, we'll leverage Fflower to do the heavy lifting so you can focus on the model and data instead of how federated learning works. Let's also take a look Federated LLMmodel size, communication cost, and privacy constraints become more important.
Note: All images are created by the authors unless otherwise noted.