

What is prorlv2?
prorlv2 It is the latest version of NVIDIA's Long-Term Reinforcement Learning (PRORL), designed specifically to push the boundaries of inference with large language models (LLMS). By scaling the reinforcement learning (RL) steps From 2,000 to 3,000PRORLV2 systematically tests how to unlock new solution spaces, creativity, and high-level inference that were previously inaccessible, even for small models such as the 1.5B parameter Nemotron-Research-Raining-QWEN-1.5B-V2.
PRORLV2's major innovations
PRORLV2 incorporates several innovations to overcome common RL limitations in LLM training.
- Enhancement++ – Baseline: A robust RL algorithm that handles the instability typical of RL in LLMS and allows for long-term optimization in thousands of steps.
- KL Divergence Remulization & Reference Policy Reset: By preventing RL's objectives from being too early, it regularly redisplays reference models at current best checkpoints, allowing for stable progress and continuous investigation.
- Isolated clipping and dynamic sampling (DAPO): Enhances unlikely tokens and promotes discovery of diverse solutions by focusing learning signals on mid-difficulty prompts.
- Scheduled length penalty: Applied periodically, helps to maintain diversity and prevent entropy collapse as training increases.
- Scaling Training Procedures: PRORLV2 directly tests the RL training horizon from 2,000 to 3,000 steps and allows RL to expand its inference capabilities.
How prorlv2 expands LLM inference
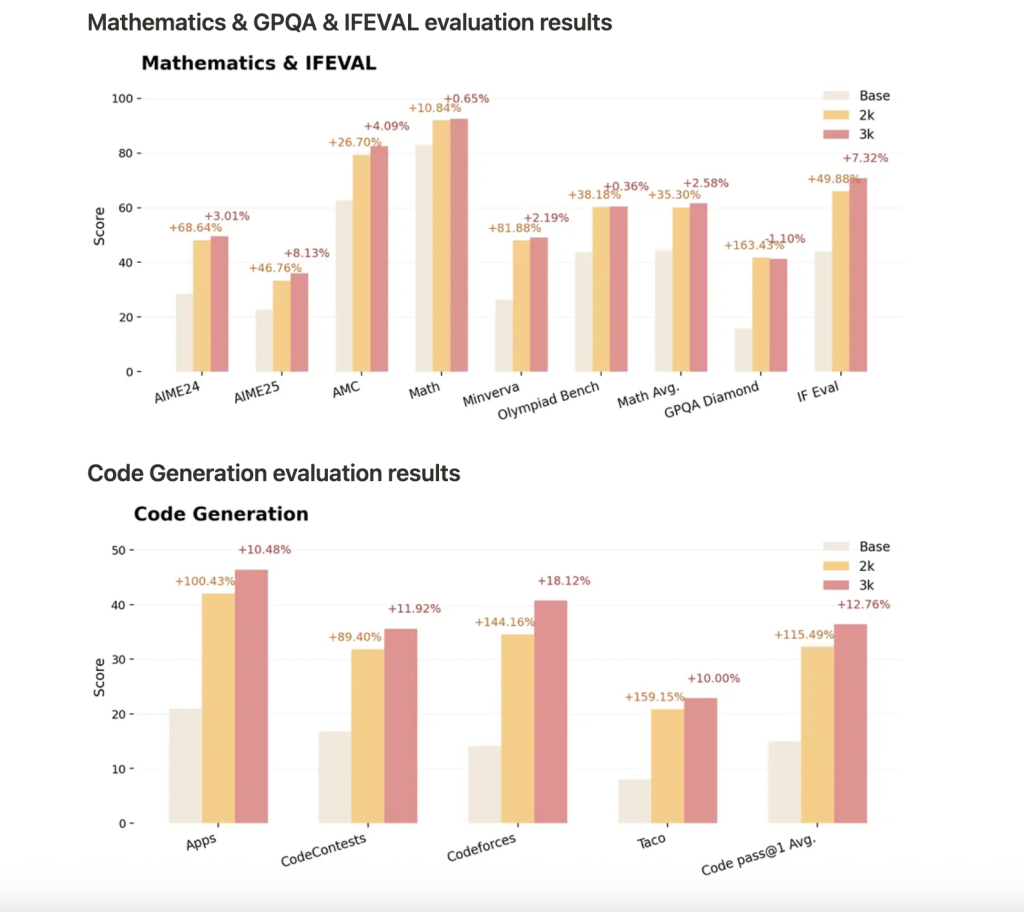
Nemotron-Research-Reasoning-Qwen-1.5B-V2 is trained in Prorolv2 with 3,000 RL steps and sets a new standard for the open weight 1.5B model for inference tasks that include mathematics, code, science and logic puzzles.
- Performance outperforms previous versions such as deepseek-R1-1.5b and competitors.
- Continuous benefits with more RL steps:Longer training leads to continuous improvement, especially in tasks with poor performance in the base model, demonstrating true expansion of inference boundaries.
- Generalization: PRORLV2 not only boosts the accuracy of the pass @1, but also allows for new inference and solution strategies for tasks that are not seen during training.
- benchmark: Profits include an average path @1 improvement of 14.7% in mathematics, 13.9% in coding, 54.8% in logic puzzles, 25.1% in STEM inference, 18.1% instructed tasks, and further improvements in V2 will be further improved with invisible benchmarks.
Why is it important?
The main discovery of prolv2 is Continuous RL training ensures that careful research and regularization expands what LLMS can learn and generalize. Rather than hitting early plateaus or over-fitting RL, smaller models can be comparable to much larger models in reasoning. We demonstrate that the scaling of the RL itself is as important as the model or dataset size.
Using Nemotron-Research-Reasoning-Qwen-1.5B-V2
The latest checkpoints can be used for face-hugging tests. Model Loading:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("nvidia/Nemotron-Research-Reasoning-Qwen-1.5B")
model = AutoModelForCausalLM.from_pretrained("nvidia/Nemotron-Research-Reasoning-Qwen-1.5B")
Conclusion
PRORLV2 redefines the limits of inference in linguistic models by showing that RL scaling laws are just as important as size and data. Advanced normalization and smart training schedules allow deep, creative and generalizable inferences even in compact architectures. There's a future How far RL can be pushed How big The model can be retrieved.
Please check Unofficial blog and Model hugging his face here. Please feel free to check GitHub pages for tutorials, code and notebooks. Also, please feel free to follow us Twitter And don't forget to join us 100k+ ml subreddit And subscribe Our Newsletter.
Nikhil is an intern consultant at MarktechPost. He pursues an integrated dual degree in materials at Haragpur, Indian Institute of Technology. Nikhil is an AI/ML enthusiast and constantly researches applications in fields such as biomaterials and biomedicine. With a strong background in material science, he creates opportunities to explore and contribute to new advancements.


