
Researchers at MIT, Microsoft and Google have introduced the “Periodic Table of Machine Learning,” which is supposed to unify many different machine learning technologies using a single framework. Their framework, called Information Control Learning (i-con)it shows that various algorithms can all be displayed in a more general context, such as classification, regression, large-scale language modeling, clustering, dimension reduction, spectral graph theory, and more.
i-con reconstructs many common techniques as variations of shared mathematical ideas: learn the relationships between data points. Just as how regular tables in chemical tables were organized and predicted new elements, researchers' tables not only clarify existing machine learning methods, but also predict new ones. In fact, one such prediction has led to a state-of-the-art algorithm that can already classify images without human sign data.

Understanding I-con: Clustering Gala
At the heart of their framework are simple ideas. Most algorithms can be rewritten in that they learn the relationships between different data points. i-con shows that although different algorithms hold different types of relationships, the core mathematics behind these approaches are all exactly the same.
To intuitively understand the mathematics behind i-con, imagine you attend an epic ballroom party. You know a few people, but most of your guests are strangers. Suddenly, we hear the host slap a glass of champagne and everyone signalling to find a dinner table. You're quickly scanning the room and looking for friends to sit with. Depending on the guest's social or introvert, you may be able to grasp a group of friends simply by looking at guests at each table.
This scene provides an easy way to understand what “clustering” looks like in i-con. Here, each guest represents a data point, and a friend is a data point nearby. Each table is a “cluster” where guests are happiest when sitting with friends, forming a tight, compact group that reflects the structure of the data. It is not always possible to have all your friends sit together, and better seating arrangements can keep more friends together. In this view, clustering appears to approximate complex networks with connections and connections that people can form, sitting together at the same table.
Integrate machine learning methods using i-con
In a broader sense, many machine learning algorithms are like this party scene, with slight variations in how guests (data points) find friends and place themselves in tables (clusters). At a real party there are many different ways people can connect. Some bonds are strong, others are weak. Sometimes connections are formed over common interests, sometimes by shared homelands. Many different machine learning algorithms can be formed by changing the way data points connect with their neighbors.
A recent paper from the team, published at the 2025 International Conference on Learning Representation, shows that over 20 common machine learning algorithms can be reproduced by changing the concept of algorithms about which data points are adjacent. More specifically, I-CON aims to approximate the connections present in the underlying data in simplified representations, such as attempting to approximate complex social networks with concrete seating arrangements in the party example. The key is that “connection” is a flexible idea in I-Con. It means visual similarity, shared class labels, cluster membership, and many other types of relationships. Moreover, relationships do not have to be absolute. You can have a degree of confidence, just like in a room.
| algorithm | Input data connection | Output data connection |
|---|---|---|
| Gala example | friendship | Share tables |
| Clustering (k-means) | Physical proximity | Cluster Sharing |
| Dimensional reduction (SNE, T-SNE, PCA) | High-dimensional physical proximity | Low-dimensional physical proximity |
| Self-teacher's expression learning | Did the two data points arise from the same process? | Physical proximity |
| Graph clustering (spectral clustering) | Are the two nodes connected at the edge? | Cluster Sharing |
| Classification (Cross Entropy) | Are data points associated with a particular class? | Physical proximity |
| Large scale language modeling | Does this token complete this text? | Physical proximity |

This simple yet basic idea integrates a wide range of techniques. Dimensional reduction tools such as SNE, T-SNE, and PCA define neighborhoods based on the physical proximity of the data points. Supervised classification method group data by label. The clustering algorithm focuses on shared group membership. What once seemed like a clear algorithm that was invented alone is sometimes displayed as variations within a single coherent framework, hundreds of years apart. More formally, each method uses a distance called a Kullback Liebler Divergence to minimize how much the approximate connection deviates from the actual “connection” of data.
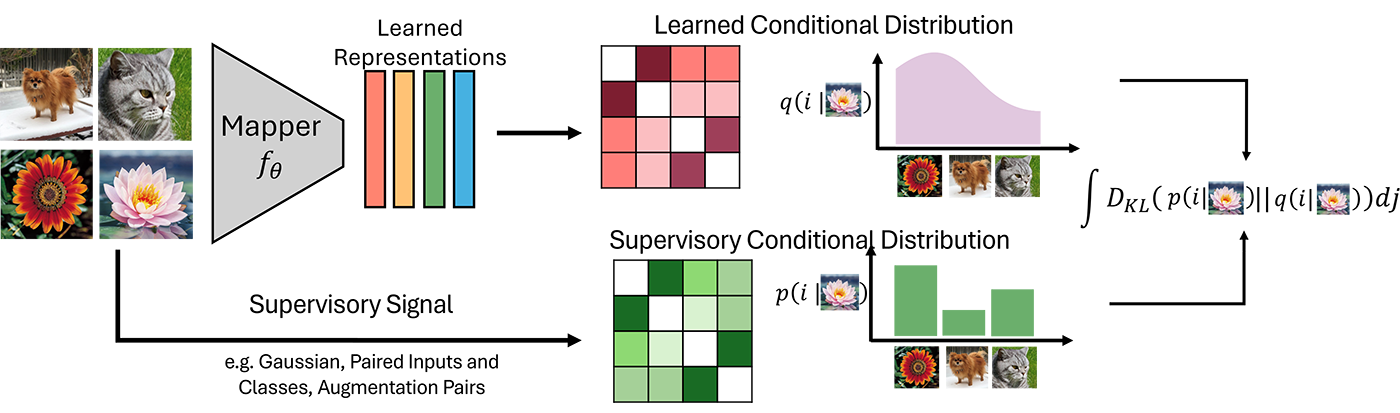
Organize the algorithm in the periodic table
Just like with chemistry, organizing known elements opens the door to discovering new elements. As the team studied the I-con framework, several patterns began to emerge. In particular, the team noticed that the algorithms they studied showed different “connection” types over and over again. The team then decided to enumerate all the main ways that point points can connect with the actual dataset, and all the ways that algorithms can estimate these connections. Each machine learning method they studied fits nicely into a square. Most surprisingly, after filling in the way they knew, this table was still waiting for many “gaps” to fill up. These gaps pointed to technology that did not exist yet, but were able to be plausible.
Filling the gaps in the periodic table
One such method the team introduced introduced recent advances in delegated representation learning with clustering to create cutting-edge algorithms for image recognition without using single human labels. We have built a new way of combining connections between data points used in delegated contrast learning and approximate connections used in team clustering clustering images. In particular, the way they found missing certain squares in the table allows images from the ImagENET-1K dataset to be classified by 8% over the previous approach.
To understand conflicts intuitively, you can go back to the example clustering gala. In this context, secrets add a little friendship between all the guests. This small amount of friendship not only improves the overall atmosphere of the party, but also makes it a little easier to create a comfortable seating arrangement. Although this technique was originally developed to improve “expression learning”, it turns out that it can be easily applied to all I-con frameworks, including clustering.
A framework for discovery
What makes I-Con powerful is not just explaining existing algorithms, but also providing researchers with a toolkit to design new ones. Experiments become easier when different methods are expressed in the same concept language. Redefine your neighborhood, adjust for uncertainty, and combine strategies. Each variation corresponds to a new entry in the periodic table.
“It's not just a minority,” says MIT Master's degree and first author Shaden Alshammari. “We see machine learning as a system with structures that are spaces that can be explored, rather than simply guessing our path.”
From this perspective, I reconstruct machine learning as a kind of design science. It not only organizes what we already know, but also reveals what we lack and how we build it.
I'm looking forward to it
As artificial intelligence continues to expand its reach, frameworks like I CON offer ways to bring order to chaos. They help researchers see structures hidden beneath the surface, providing tools to innovate not only with intuition but with purpose.
It reminds us that for people outside of the AI world, even in areas as complex as machine learning, simple patterns may still be waiting to be found. Just like the way the periodic table once brought consistency in chemistry, I-CON offers a hopeful step to understanding the deeper structure of learning, not by unraveling intelligence, but by revealing its centrality.
And there's still plenty of room left at the table.


