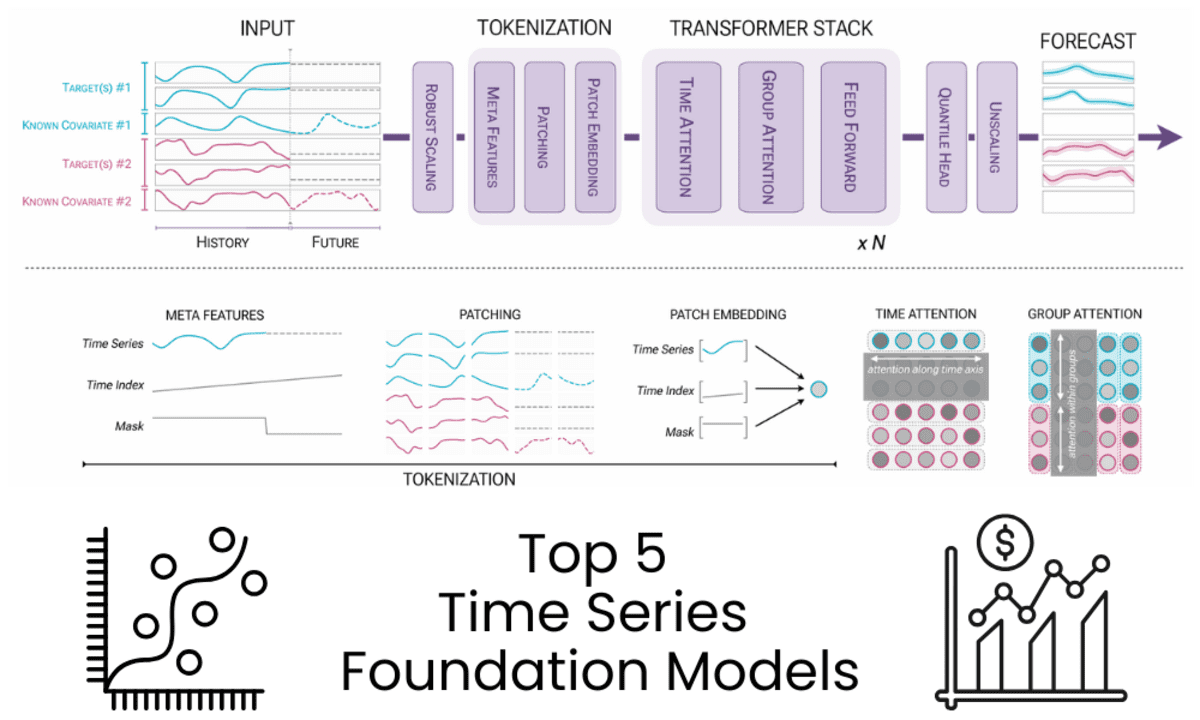
Image by author | Chronos-2 diagram: From univariate predictions to universal predictions
# introduction
The underlying model didn’t start with ChatGPT. Long before large-scale language models became popular, pre-trained models were already driving advances in computer vision and natural language processing, such as image segmentation, classification, and text understanding.
The same approach is currently being used to reconstruct time series forecasts. Rather than building and tuning separate models for each dataset, a time series foundational model is pretrained on a large and diverse collection of time series data. These can provide strong zero-shot prediction performance across domains, frequencies, and ranges, often matching deep learning models that require hours of training using only historical data as input.
If you’re still relying primarily on classic statistical methods or single-dataset deep learning models, you may be missing out on major changes in the way predictive systems are built.
In this tutorial, we review five time series foundation models selected based on performance, popularity as measured by Hugging Face downloads, and ease of use in the real world.
# 1. Kronos-2
Kronos-2 is a 120 million parameter encoder-specific time series infrastructure model built for zero-shot prediction. It supports predictions based on univariate, multivariate, and covariate information in a single architecture, providing accurate multi-step probabilistic predictions without task-specific training.
Main features:
- Encoder-only architecture inspired by T5
- Zero shot prediction using quantile output
- Native support for past and known future covariates
- Long context lengths up to 8,192 and prediction periods up to 1,024
- High-throughput efficient CPU and GPU inference
Usage example:
- Large-scale forecasting across many related time series
- Forecasts based on covariates such as demand, energy, and prices
- Rapid prototyping and production deployment without model training
Best use case:
- Production forecasting system
- Research and benchmarking
- Complex multivariate predictions using covariates
# 2. T-Rex
Tyrex is a 35 million parameter pre-trained time series forecasting model based on xLSTM, designed for zero-shot forecasting over both long and short term. It can generate accurate predictions without requiring training on task-specific data and provides both point and probability predictions out of the box.
Main features:
- Pre-trained xLSTM-based architecture
- Zero-shot prediction without the need for dataset-specific training
- Point prediction and quantile-based uncertainty estimation
- Excellent performance in both long-term and short-term benchmarks
- Optional CUDA acceleration for high-performance GPU inference
Usage example:
- Zero-shot predictions for new or unconfirmed time series datasets
- Long-term and short-term forecasts in finance, energy, and operations
- Rapid benchmarking and deployment without requiring model training
# 3. Times FM
Times FM is a pre-trained time series foundational model developed by Google Research for zero-shot prediction. Open Checkpoint timesfm-2.0-500m is a decoder-only model designed for univariate prediction, supporting long historical context and flexible prediction horizons without task-specific training.
Main features:
- Decoder-only basic model with 500M parameter checkpoints
- Zero-shot univariate time series forecasting
- Context length up to 2,048 time points to support beyond training limits
- Flexible forecast horizon with optional frequency indicators
- Optimized for fast point prediction at scale
Usage example:
- Univariate predictions at scale across diverse datasets
- Long-term forecasting of operational and infrastructure data
- Rapid experimentation and benchmarking without model training
# 4. IBM Granite TTM R2
Granite-TimeSeries-TTM-R2 is a family of compact, pre-trained time series foundational models developed by IBM Research based on the TinyTimeMixers (TTM) framework. Designed for multivariate prediction, these models deliver strong zero-shot and few-shot performance despite a small model size of 1 million parameters, making them suitable for both research and resource-constrained environments.
Main features:
- Small pre-trained model starting with 1M parameters
- Powerful zero-shot and few-shot multivariate prediction performance
- Focused models tailored to your specific situation and forecast period
- Fast inference and fine-tuning on a single GPU or CPU
- Support for exogenous variables and static categorical features
Usage example:
- Multivariate prediction in low-resource or edge environments
- Zero-shot baseline with optional lightweight fine-tuning
- Rapid deployment for operational forecasting with limited data
# 5.TOTO open base 1
Toto-Open-Base-1.0 is a decoder-specific time series foundation model designed for multivariate forecasting in observability and monitoring settings. Optimized for high-dimensional, sparse, and non-stationary data, it provides strong zero-shot performance on large-scale benchmarks such as GIFT-Eval and BOOM.
Main features:
- Decoder-specific transformer for flexible context and predicted length
- Zero shot prediction without fine-tuning
- Efficient processing of high-dimensional multivariate data
- Probabilistic prediction using Student-T mixture models
- Pre-trained on over 2 trillion time series data points
Usage example:
- Predicting observability and monitoring metrics
- High-dimensional systems and infrastructure telemetry
- Zero-shot prediction of large non-stationary time series
summary
The table below compares the core characteristics of the time series-based models discussed, focusing on model size, architecture, and predictive capabilities.
| model | parameters | architecture | Prediction type | Main strengths |
|---|---|---|---|---|
| Kronos-2 | 120M | Encoder only | Univariate, multivariate, probability | Strong zero-shot accuracy, long context and range, and high inference throughput |
| Tyrex | 35M | xLSTM base | univariate, stochastic | Lightweight model with excellent short- and long-distance performance |
| Times FM | 500M | decoder only | Univariate, point prediction | Handles long contexts and flexible fields of view at scale |
| Granite Time Series TTM-R2 | 1M ~ small | Focused pre-trained model | Multivariate, point prediction | Extremely compact, fast inference, powerful zero-shot and few-shot results |
| TOTO open base 1 | 151M | decoder only | multivariate, stochastic | Optimized for high-dimensional non-stationary observability data |
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs about machine learning and data science technology. Abid holds a master’s degree in technology management and a bachelor’s degree in communications engineering. His vision is to build AI products using graph neural networks for students suffering from mental illness.