
author:
(1) Lukas Korel, Faculty of Information Technologies, Czech Technical University, Prague, Czech Republic
(2) Petr Pruc, Faculty of Information Technology, Czech Technical University, Prague, Czech Republic
(3) Jiri Tumpac, Faculty of Mathematics and Physics, Charles University in Prague, Czech Republic
(4) Martin Holena, Institute of Computer Science, Academy of Sciences of the Czech Republic, Prague, Czech Republic.
List of Links
Overview and Introduction
ANN-based scene classification
methodology
experiment
Conclusions and future work, Acknowledgements and References
5. Conclusions and future research
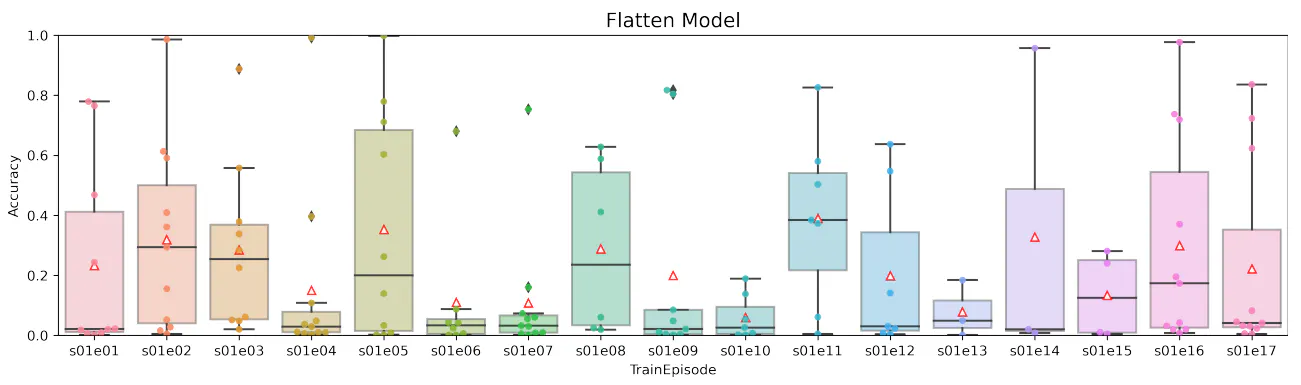
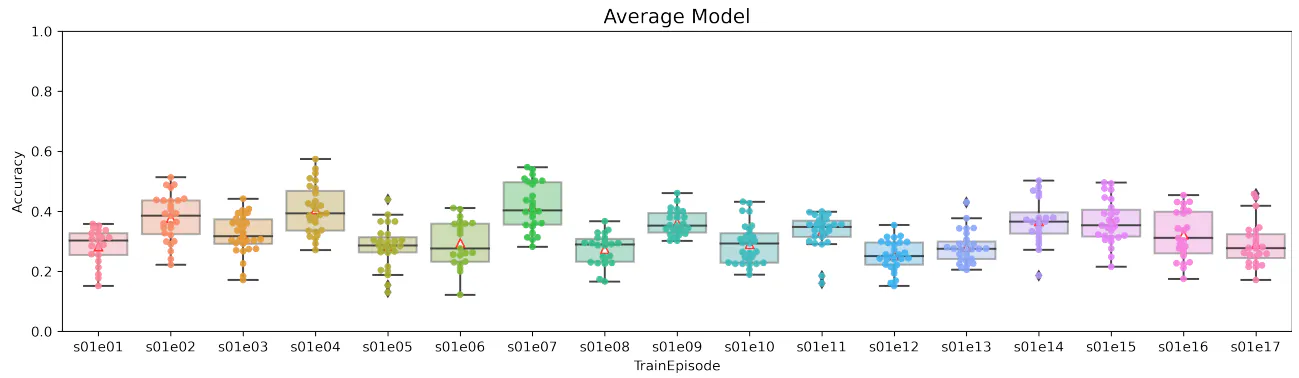
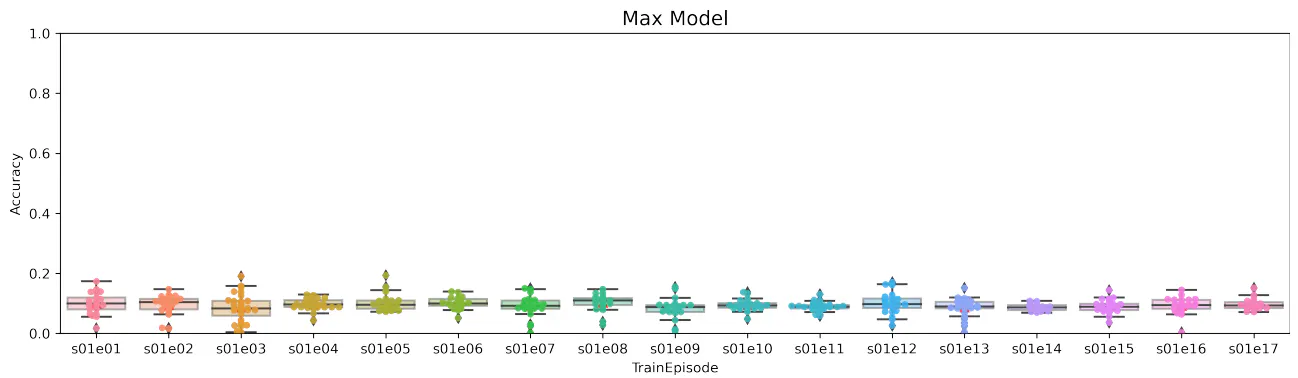
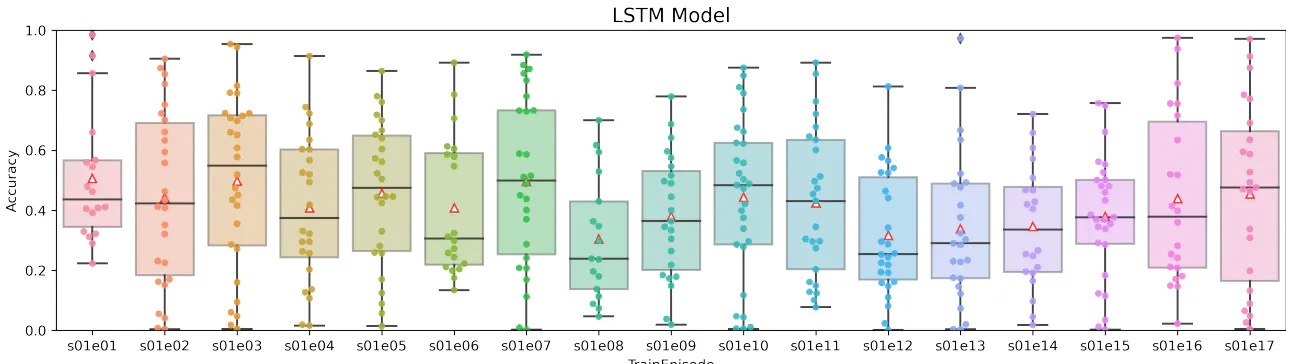
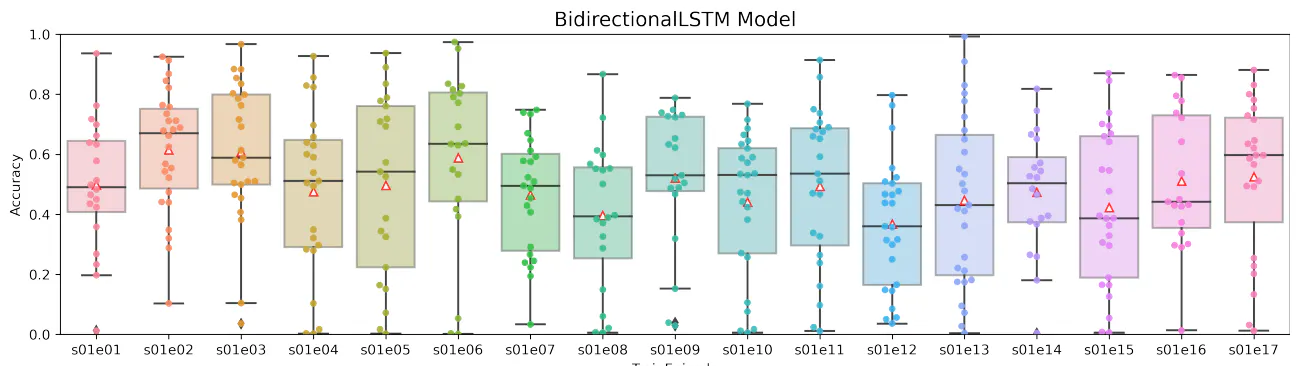
In this paper, we considered the possibility of using artificial neural networks to detect scene recognition positions from video sequences that contain small sets of repeated shots (such as television series). Our idea was to select several frames from each scene and use that frame sequence to classify the scene. We used a pre-trained VGG19 network without the last two layers. This result was used as input to the trainable part of our neural network architecture. We designed six neural network models with different layer types. We investigated different neural network layers for combining video frames, in particular average pooling, max pooling, product, flattening, LSTM, and bidirectional LSTM layers. The considered networks were tested and compared on a dataset taken from The Big Bang Theory television series. The model with max pooling layer was not successful and its accuracy was the lowest of all models. Models with flattening or product layers were very unstable and had very large standard deviations. The most stable of all models was the model with average pooling layer. One-way LSTM and bidirectional LSTM models had similar standard deviations of accuracy. The bidirectional LSTM model showed the highest accuracy of all the models considered, which we believe is because the internal memory cells hold information in both directions. These results indicate that models with internal memory can classify with higher accuracy than models without internal memory.
This method may have limitations due to the selected pre-trained ANN and the reduced dimensionality of some neural layers. In future research, it is desirable to improve the accuracy of scene location recognition. This task may also require changing model parameters or using other architectures. It may also require other pre-trained models or a combination of multiple pre-trained models. It is also desirable for the ANN to remember when it detects an unknown scene and properly recognize the scene in the same location next time.
Acknowledgements
The research reported in this paper has been supported by the Czech Science Foundation (GACR) under grant 18-18080S.
Computational resources were provided by the project “e-Infrastruktura CZ” (e-INFRA LM2018140) delivered within the Large-Scale Research, Development and Innovation Infrastructure Projects Programme.
Computational resources were provided by the ELIXIRCZ project (LM2018131), part of the international ELIXIR infrastructure.

![Table 3: Summary of prediction accuracy across 17 datasets [%]](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
![Table 3: Summary of prediction accuracy across 17 datasets [%]](https://hackernoon.imgix.net/images/fWZa4tUiBGemnqQfBGgCPf9594N2-lb83ylf.png?auto=format&fit=max&w=1920)







References
[1] Zhong, W., Kjellström, H.: Movie scene recognition with convolutional neural networks. https://www.diva-portal.org/smash/get/diva2 :859486/FULLTEXT01.pdf KTH ROYAL INSTITUTE OF TECHNOLOGY (2015) 5–36
[2] Simonyan, K., Zisserman, A.: Very deep convolutional networks for large scale image recognition. https://arxiv.org/pdf/1409.1556v6.pdf Visual Geometry Group, School of Engineering, University of Oxford (2015)
[3] Russakovsky O., Deng J., Hao S., Krause J., Satheesh S., Ma Sean, Huang Z., Karpathy A., Khosla A., Bernstein M., Berg A. C., Fei-Fei L.: ImageNet large scale visual recognition challenge. International Journal of Computer Vision 115 (2015), pp. 211–252.
[4] Li-jia L., Hao S., Fei-fei L., Xing E.: High-level image representation for scene classification and semantic feature sparsification. https://cs.stanford.edu/groups/vision/pdf/ LiSuXingFeiFeiNIPS2010.pdf NIPS (2010)
[5] Felix A. Gers, Schmidhuber J., Cummins F., “Learning to forget: Continuous prediction with LSTMs,” Proceedings of ICANN. ENNS (1999), pp. 850––855.
[6] Benavoli A., Corani G., Mangili F.: Should we really use post-hoc tests based on mean ranks? Journal of Machine Learning Research 17 (2016), pp. 1–10
[7] García S., Herrera F.: An extension to all pairwise comparisons of “Statistical comparison of classifiers across multiple datasets” Journal of Machine Learning Research 9 (2008), pp. 2677–2694
[8] Graves, A.: Supervised sequence labelling with recurrent neural networks. Springer (2012)
[9] Kaiming H., Xiangyu Z., Shaoqing R., Jian S.: Deep residual learning for image recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (2016), pp. 770–778
[10] Sudha V., Ganeshbabu T.R.: Convolutional Neural Network Classifier for Diabetic Retinopathy Lesion Detection and Grading Based on Deep Learning VGG-19 Architecture. http://www.techscience.com/cmc/v66n1/40483 Computers, Materials & Continua (2021), pp. 827–842
[11] Zhou, B., Lapedriza, A., Khosla, A., Oliva, A., Torralba, A.: Places: a 10 million image database for scene recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence (2018), pp. 1452–1464.


