


The field of deep reinforcement learning (DRL) has expanded the capabilities of robot control. However, algorithmic complexity has tended to increase. As a result, state-of-the-art algorithms require many implementation details to perform well at different levels, which makes reproducibility problematic. Moreover, even state-of-the-art DRL models have simple problems like the Mountain Car environment and the Swimmer task. However, several studies have argued against finding simpler baselines or scalable alternatives for RL tasks, and these efforts have highlighted the need for simplification in this field. Complex RL algorithms often require detailed task design in the form of slow reward engineering.
To address these issues, this paper discusses related work such as exploring simpler RL baselines and periodic policies for walking. In the first approach, simpler parameterizations such as linear functions and radial basis functions (RBFs) are proposed, highlighting the weaknesses of RL. In the second approach, periodic policies for walking are used, integrating rhythmic movements into the robot control. Recent research has focused on using oscillators to manage the walking task of quadruped robots. However, no work to date has explored the application of open-loop oscillators in RL walking benchmarks.
Researchers from the German Aerospace Center (DLR) RMC in Germany, the Sorbonne University CNRS in France, and Delft University of Technology in the Netherlands have proposed a simple open-loop model-free baseline that performs well on standard locomotion tasks without complex models or large computational resources. While it cannot beat RL algorithms in simulation, it offers various advantages in real-world applications. These advantages include fast computation, easy deployment in embedded systems, smooth control output, and robustness against sensor noise. Although the method is designed to solve locomotion tasks, its simplicity does not limit its generality.
The RL baseline uses the JAX implementation of Stable-Baselines3 and the RL Zoo training framework. The search space is used to optimize the oscillator parameters. The effectiveness of the proposed method is tested on the MuJoCo v4 locomotion task included in the Gymnasium v0.29.1 library. The approach is compared with three established deep RL algorithms: (a) Proximity Policy Optimization (PPO), (b) Deep Deterministic Policy Gradient (DDPG), and (c) Soft Actor Critic (SAC). Furthermore, the hyperparameter settings are taken from the original papers to ensure a fair comparison, except for the swimmer task, where the discount factor (γ = 0.9999) is fine-tuned.
The proposed baseline and associated experiments reveal the existing limitations of DRL in robotic applications, provide insights on how to address them, and prompt considerations on the costs of complexity and generality. The DRL algorithm is compared to the baselines through experiments on locomotion tasks, including simulated tasks, and transferred to a real elastic quadruped robot. This paper aims to address three key questions:
- How does the open-loop oscillator compare to the DRL approach in terms of performance, execution time, and parameter efficiency?
- Compared to the open-loop baseline, how tolerant is the RL policy to sensor noise, disturbances, and external impairments?
- If we train without randomization or reward engineering, how does the learned policy transfer to a real robot?

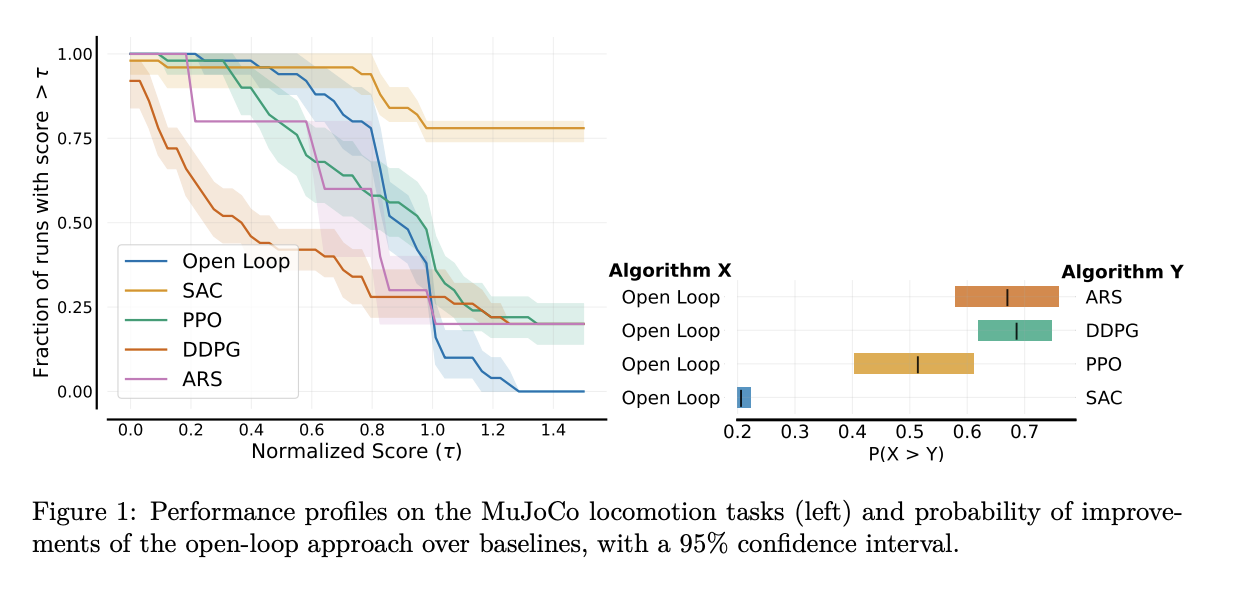
In conclusion, the researchers introduced an open-loop, model-free baseline that performs well on standard locomotion tasks without requiring complex models or computational resources. The paper includes two additional experiments conducted using an open-loop oscillator to detect current shortcomings in the DRL algorithm. Compared to the baseline, we find that DRL tends to perform poorly when faced with sensor noise and obstacles. However, this baseline is limited because, by design, open-loop control is sensitive to disturbances and cannot recover from potential drops. The method generates joint positions without using the robot's state; therefore, the simulation requires a PD controller to convert these positions into torque commands.
Please check paperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us. twitter.
participate Telegram Channel and LinkedIn GroupsUp.
If you like our work, you will love our Newsletter..
Please join us 46k+ ML Subreddit


Sajjad Ansari is a final year undergraduate student at Indian Institute of Technology Kharagpur. As a technology enthusiast, he delves into practical applications of AI with a focus on understanding the impact of AI technology and its impact on the real world. He aims to express complex AI concepts in a clear and understandable manner.


