


Multimodal machine learning is a cutting-edge research field that combines different data types, such as text, images, and audio, to create more comprehensive and accurate models. By integrating these different modalities, researchers aim to enhance a model's ability to understand and reason about complex tasks. This integration allows the model to leverage the strengths of each modality, improving performance in a variety of applications, from image recognition and NLP to video analysis.
A major problem in multimodal machine learning is the inefficiency and lack of flexibility of large multimodal models (LMMs) when dealing with high-resolution images and videos. Traditional LMMs, such as LLaVA, use a fixed number of visual tokens to represent an image, which often results in excessive tokens being used for dense visual content. This increases computational cost and reduces performance by stuffing the model with too much information. Therefore, there is an urgent need for a method that can dynamically adjust the number of tokens based on the complexity of the visual input.
Existing solutions to this problem, such as token pruning and merging, attempt to reduce the number of visual tokens input to the language model. However, these methods typically produce a fixed-length output for each image, which does not provide the flexibility to balance information density and efficiency. They need to adapt to different levels of visual complexity, which is important in applications such as video analysis, where the visual content can change significantly from frame to frame.
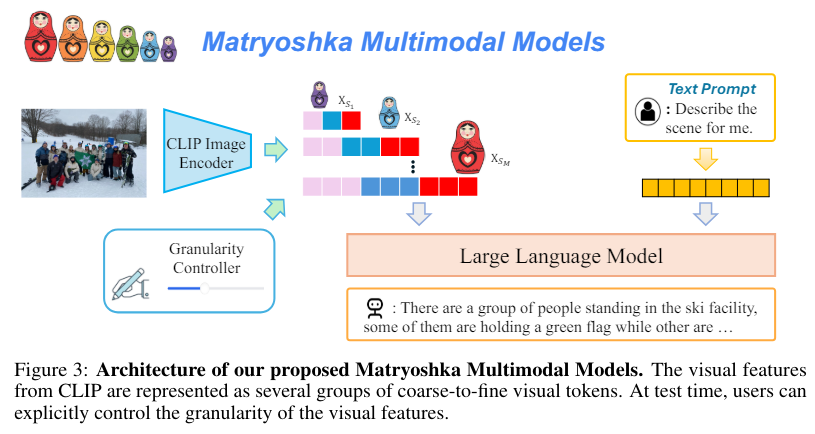
The study was announced by researchers from the University of Wisconsin-Madison and Microsoft Research. Matryoshka Multimodal Model (M3)Inspired by the concept of a Matryoshka doll, M3 represents visual content as a nested set of visual tokens that capture information across multiple levels of granularity. This novel approach allows for explicit control over visual granularity during inference, allowing the number of tokens to be adjusted based on the expected complexity or simplicity of the content. For example, an image dense with detail can be represented with more tokens, while a simple image can be represented with fewer tokens.


The M3 model achieves this by encoding an image into multiple sets of visual tokens with incrementally increasing levels of granularity, from coarse to fine. During training, the model learns to derive coarse tokens from fine tokens, ensuring that visual information is captured efficiently. Specifically, the model uses scales such as 1, 9, 36, 144, and 576 tokens, with each level providing an increasingly finer representation of visual content. This hierarchical structure allows the model to adjust the level of detail based on specific requirements while still preserving spatial information.

Performance evaluation of the M3 model demonstrates its significant advantages. On COCO-style benchmarks, the model achieved similar accuracy using only about nine tokens per coin as it did using all 576 tokens, meaning a significant increase in efficiency without compromising accuracy. The M3 model also performed well on other benchmarks, demonstrating that it can maintain high performance even with a significantly reduced number of tokens. For example, the accuracy of the model using nine tokens was comparable to Qwen-VL-Chat using 256 tokens, and in some cases it achieved similar performance with just one token.
The model allows for flexible control over the number of visual tokens, allowing it to adapt to different computational and memory constraints during deployment. This flexibility is especially useful in real-world applications where resources may be limited. The M3 approach also provides a framework for evaluating the visual complexity of a dataset, helping researchers understand the optimal granularity required for different tasks. For example, natural scene benchmarks such as COCO can be processed with around 9 tokens, while dense visual recognition tasks such as document understanding and OCR require many more tokens, ranging from 144 to 576 tokens.


In conclusion, the Matryoshka multimodal model (M3) addresses the inefficiencies of current LMMs and provides a flexible and adaptable way to represent visual content, laying the foundation for more efficient and effective multimodal systems. The model's ability to dynamically adjust the number of visual tokens based on content complexity provides a better balance between performance and computational cost. This innovative approach enhances the understanding and inference capabilities of multimodal models, opening up new possibilities for applications in diverse and resource-limited environments.
Please check Papers and projects. All credit for this research goes to the researchers of this project. Also, don't forget to follow us. twitter. participate Telegram Channel, Discord Channeland LinkedIn GroupsUp.
If you like our work, you will love our Newsletter..
Please join us 43,000+ ML subreddits | In addition, our AI Event Platform


Sana Hassan, a Consulting Intern at Marktechpost and a dual degree student at Indian Institute of Technology Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, she brings a fresh perspective to the intersection of AI and real-world solutions.

