


Understanding and reasoning about program execution is an important skill for developers and is often applied during tasks such as debugging and code repair. Traditionally, developers mentally simulate code execution or use debugging tools to identify and fix errors. Despite their sophistication, large-scale language models (LLMs) trained on code have struggled to grasp deeper semantic aspects of program execution beyond the superficial textual representation of code. I did. This limitation often impacts the performance of complex software engineering tasks, such as program repair, where understanding a program's execution flow is essential.
Existing research on AI-driven software development includes several frameworks and models that focus on enhancing code execution inference. Notable examples include specialized neural architectures such as CrossBeam, which leverages the execution state of sequence-to-sequence models, and instruction-pointer attention graph neural networks. Other approaches, such as the differentiable Forth interpreter and Scratchpad, integrate execution traces directly into model training to improve program synthesis and debugging capabilities. These methods focus on both the process of execution and the dynamic state within the programming environment, paving the way for advanced reasoning about code.

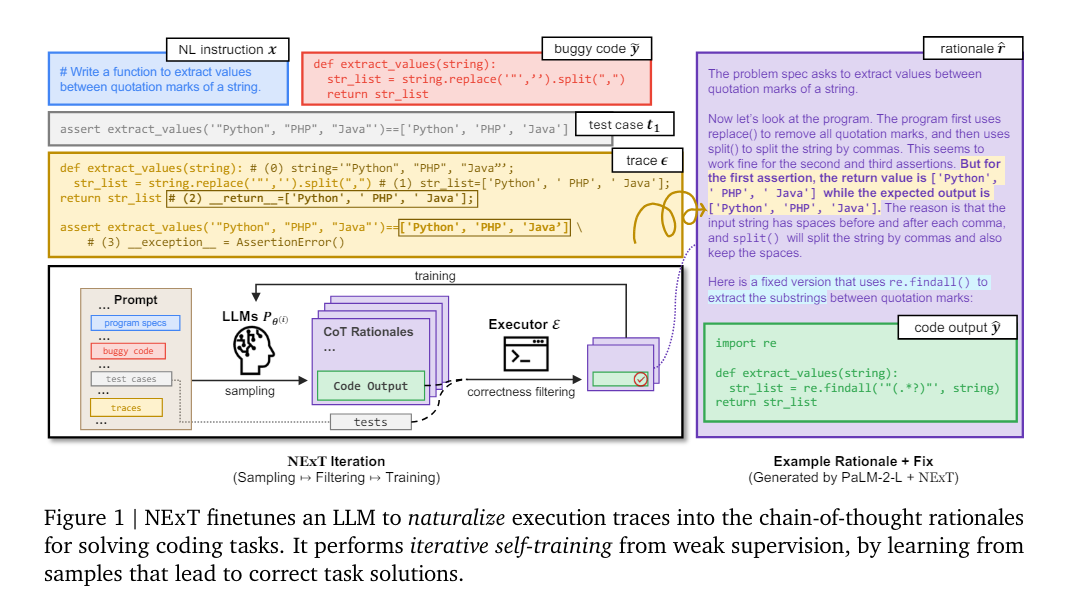
Researchers from Google DeepMind, Yale University, and the University of Illinois propose NExT, which introduces a new approach by teaching LLMs how to interpret and use execution traces, enabling more nuanced inferences about program behavior at runtime. I'll make it. This method stands out because it incorporates detailed runtime data directly into model training, facilitating semantic understanding of the code. By embedding execution traces as inline comments, NExT gives models access to important context that is often overlooked by traditional training methods, providing a more accurate basis for generated code fixes and making them more accurate than actual code. It will be based on execution.
The NExT methodology utilizes a self-training loop to improve the model's ability to generate action-aware rationale. First, the execution traces are synthesized into a dataset using the proposed code modifications. Each trace details the state of variables and their changes during execution. This method uses Google's PaLM 2 model to assess performance on tasks such as program repair, and iterative iterations significantly improve the model's accuracy. The dataset includes Mbpp-R and HumanEval Fix-Plus, benchmarks designed to test programming skills and error correction in code. This method of iterative learning and synthetic dataset generation focuses on actually improving the programming capabilities of LLM without requiring extensive manual annotation.

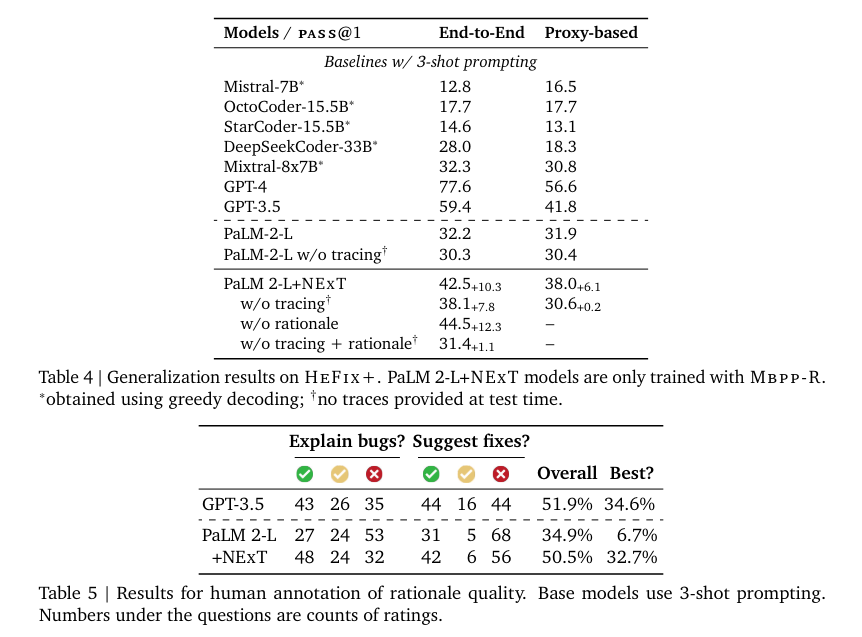
Significant improvements in program repair tasks demonstrate the effectiveness of NExT. Applying the NExT technique, the PaLM 2 model achieved an absolute fixed-rate increase of 26.1% on the Mbpp-R dataset and an absolute improvement of 14.3% on HumanEval Fix-Plus. These results demonstrate a significant improvement in the model's ability to accurately diagnose and correct programming errors. Additionally, the quality of the rationale generated by the model, which is essential for explaining code fixes, has significantly improved, as evidenced by automated metrics and human evaluation.
In conclusion, the NExT methodology significantly improves the ability to understand and modify the code of large language models by integrating execution traces into training. This approach has significantly improved fix rates and rationale quality for complex programming tasks, as seen in significant improvements on established benchmarks such as Mbpp-R and HumanEval Fix-Plus. NExT's practical impact on improving the accuracy and reliability of automated program repair shows its potential to transform software development practices.
Please check paper. All credit for this research goes to the researchers of this project.Don't forget to follow us twitter.Please join us telegram channel, Discord channeland linkedin groupsHmm.
If you like what we do, you'll love Newsletter..
Don't forget to join us 40,000+ ML subreddits


Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated double degree in materials from the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast and is constantly researching applications in areas such as biomaterials and biomedicine. With a strong background in materials science, he explores new advances and creates opportunities to contribute.


