

CoDi: Microsoft’s multimodal AI revolution processes and generates text, images, video and audio all at once
major highlights
- Microsoft’s CoDi is a pioneering AI that simultaneously processes and generates text, images, video and audio.
- CoDi overcomes the unimodality limitation to produce consistent and synchronized outputs from diverse media inputs.
- Beyond its technological capabilities, CoDi opens up new possibilities in education and assistive technology, transforming human-computer interaction.
Breaking out of the unimodal limit
Historically, AI models were mostly unimodal, capable of processing and producing only one type of media at a time. However, these models fall short when applied to real-world scenarios where multiple forms of media coexist and interact. Microsoft’s CoDi overcomes these barriers and serves as the first model that can process and generate different forms of media simultaneously, producing harmonious output.
CoDi’s innovation hinges on novel strategies that build shared multimodal spaces and enable synchronized generation of intertwined modalities, such as temporally aligned video and audio. This unique feature addresses previous concerns that independently generated unimodal streams become inconsistent when merged.
CoDi’s Complex Framework
Creating AI models that can handle any combination of input modalities and produce different outputs poses significant computational and data challenges. Microsoft’s approach to overcoming these hurdles was to build her CoDi in a composable and integrated way.
Initially, individual modality-specific latent diffusion models (LDMs) were trained independently to ensure excellent quality of single-modality generation. These inputs are projected into the same semantic space, thus allowing his LDM for each modality to handle any mixture of multimodal inputs.
CoDi’s pioneering innovation is its ability to manage many-to-many generation strategies and generate any combination of output modalities simultaneously. By integrating a cross-attention module and environmental encoders, CoDi accomplishes this complex feat without the need for training on all possible modality combinations.
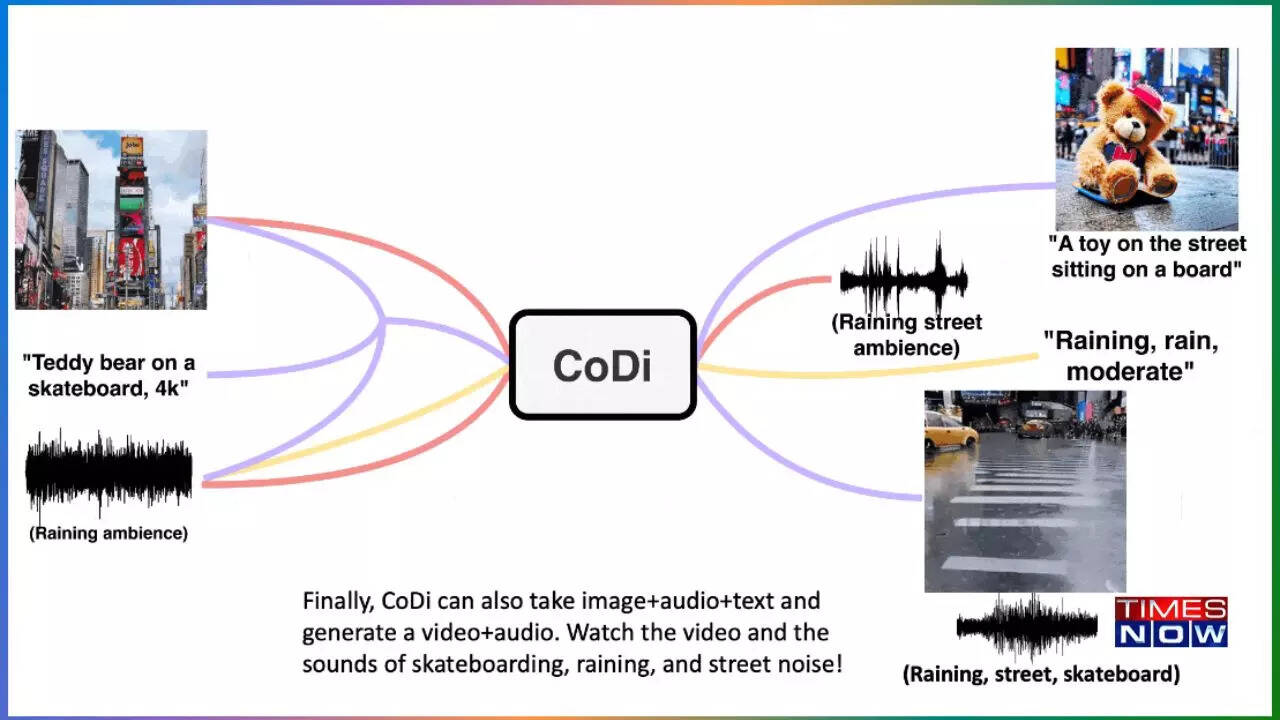
Unleash CoDi’s amazing abilities
CoDi has demonstrated its prowess in producing synchronized video and audio output by cleverly integrating text, voice, and image prompts. This progress demonstrates the potential of CoDi to integrate information from multiple inputs and produce coherent and consistent outputs.
In addition to its exceptional multimodal generation quality, CoDi also excels in single-to-single modality and multiconditioning generation. In these scenarios, CoDi matches or exceeds unimodal state-of-the-art models.
CoDi: Envisioning Real World Applications
CoDi’s breakthrough capabilities enable numerous real-world applications, especially in education and assistive technology. Generate dynamic and engaging materials for diverse learning styles and create accessible experiences for people with disabilities. CoDi is expected to greatly enhance human-computer interaction and usher in a new era of generative artificial intelligence.


