Our study revealed that despite using wide-field CF imaging, state-of-the-art CNN architecture, and a large clinically diverse dataset, the predictive accuracy of VA remains limited, especially at intermediate visual acuity levels. Although the extreme VA categories (excellent and poor) performed relatively well, the model struggled with fine-grained discrimination between adjacent VA classes and had consistent limitations across all experimental conditions. This finding suggests that this limitation is not only related to model design and dataset size, but may also reflect fundamental constraints on the information content of CF images with respect to visual features.
Data preprocessing and augmentation
Due to the data preparation method used, several validation steps were required to assess the reliability of the results.
EfficientNet-B0 was used to automatically classify CF images as left, right, or “obscure.” The F1 score for this task showed very good performance. Most misclassifications were caused by the vague definition of the “Unclear” class used during manual labeling. A significant proportion of images originally labeled as “obscure” (LE or RE) contribute to mislabeling, highlighting the subjectivity inherent in the definition of this class.
The labeled widefield CF images were compressed as part of preprocessing. This may have resulted in a loss of relevant information, especially in the central macular region. Therefore, we conducted a series of comparative tests using the uncompressed version. all images Dataset. These tests did not show any significant improvement in model performance, suggesting that the compression step did not affect model results.
error analysis
Various data augmentations did not significantly affect model performance and were not sufficient to overcome dataset limitations. A strong class imbalance (Figure 3) resulted in biased predictions towards higher acuities. Almost 40% of Good VA cases were misclassified as Excellent and 27% were misclassified as Fair, indicating limited ability to resolve intermediate VA classes. A similar pattern was observed for underrepresented classes.
Despite being underestimated, the low VA class achieved high recall (75%), but accuracy remained relatively low (38%) due to confusion with neighboring classes. Overall, the model identified extreme cases more reliably than intermediate cases.
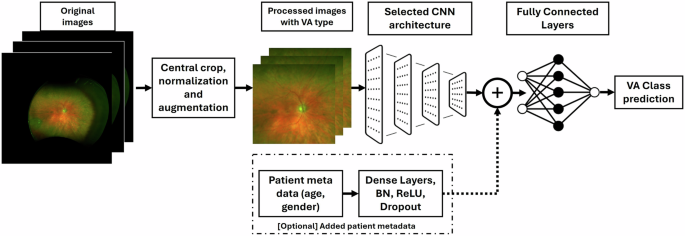
Adding patient-specific metadata did not improve performance. This may be because CF images inherently encode features such as age and gender. [12,13,14,15] Makes explicit inclusion redundant. Grad-CAM analysis showed no significant difference between correct and incorrect predictions, indicating consistent attention to the central macular region.
Disease-specific data
None of the disease-specific subsets showed significant improvement in model performance. Selecting a subset typically significantly reduces the number of patients with the disease and the number of CF images available. However, the model performance is consistent across all subsets; all images Dataset. The observed decrease in accuracy and other metrics can be attributed to the small dataset size within these subsets.
Comparison with other works
Our results showed comparable performance in both MAE and a similar distribution of predicted differences from actual BCVA compared to those reported by Paul et al. [2]. Lee et al. [1] They reported slightly better results, which may be because the training set used in their study was about 3 times larger than ours. However, the overall model performance is in good qualitative agreement with the identical results. Both datasets had strong class imbalance, and both models had low accuracy in the intermediate classes and relatively high accuracy only in the edge classes. Although our model achieved comparable results to state-of-the-art models, it struggled with high accuracy in underrepresented classes in the central VA region, and errors were still large in extreme cases. Adding metadata or disease stratification did not improve the performance of this study, raising further questions about the ability to predict VA from CF images alone.
Image modality analysis
According to the literature, VA prediction is more accurate using OCT, reflecting the fundamental differences between imaging modalities. OCT provides high-resolution cross-sectional information about the retinal microstructure, including features directly related to visual function, whereas CF imaging provides a two-dimensional overview without depth information.
Additionally, VA is determined by factors beyond retinal structure, including anterior segment conditions such as cataracts, corneal irregularities, and refractive errors. These factors have a limited impact on CF image quality, especially in wide-field systems, but can significantly reduce VA. As a result, some visual features are not captured by CF imaging, which may contribute to the limited predictive performance observed in our study.
Although CF imaging can capture specific patient characteristics, it does not provide sufficient information to directly infer VA. The complexity of VA extends beyond retinal appearance and incorporates optical and physiological factors.
A further consideration is the use of pseudocolor wide-field imaging. The Optos system used in this study generates images based on red and green laser channels rather than actual CF photographs. However, both training and testing data were acquired using the same or similar devices, so the model was exposed to consistent image characteristics. Under these conditions, deep learning models are expected to learn device-specific features, which may minimize systematic bias within this study. Nevertheless, this may limit its versatility to other imaging modalities or true CF systems.
A potential strategy to address these limitations is multimodal integration. Combining CF and OCT has the potential to leverage complementary information to improve predictions. However, OCT is not always available in all settings, whereas CF is more widely accessible. Therefore, although a multimodal approach may improve predictive performance, it may also reduce applicability and scalability. Furthermore, our dataset does not contain matched OCT images, and we were not able to evaluate such an approach in this study. Future research could explore this direction with datasets that include both modalities.
The presented results had several limitations inherent to the original dataset and chosen methodology. Image labeling by left and right eyes was performed in the CNN using a subjective criterion of “blurred” images during preprocessing, which could introduce errors that affected the accuracy of the final model. Additionally, significant class imbalance could bias the model toward more frequent classes and limit intermediate VA predictions. Finally, the relatively large dataset remains limited, which may have affected model performance, especially for subsets specific to certain diseases.
Looking to the future, testing alternative architectures such as transformer-based models may enable better feature extraction and prediction accuracy. Incorporating temporal data into long-term VA predictions may provide valuable insights into disease progression and long-term outcomes. Furthermore, expanding the dataset to include diverse imaging conditions and a broader patient population may improve the generalizability and overall performance of predictive models.
In summary, while CF imaging provides a useful tool for general retinal assessment and related health indicators, OCT remains the gold standard for accurate VA prediction due to its detailed structural analysis capabilities. This accuracy of OCT imaging allows clinicians to assess and monitor the condition with high precision, significantly improving VA prediction accuracy compared to CF imaging alone.


