image:
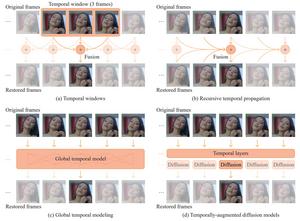
Illustration of different temporal modeling strategies.
view more
Credit: Machine Intelligence Research
Degraded facial video has long plagued digital communications, from glitchy video calls to blurry archive footage. Now, researchers have published the first comprehensive roadmap for deep learning-based facial video restoration (FVR). FVR is a technology designed to repair and enhance low-quality facial footage. This study systematically maps out how artificial intelligence can restore sharpness, preserve identity, and maintain temporal smoothness across video frames, providing a fundamental reference for what is rapidly becoming an important field in the era of ubiquitous video content.
For many years, recovery of low-quality facial videos relied on two imperfect strategies. The first applied single-image restoration techniques were applied frame by frame and produced sharp individual images, but introduced flickering, inconsistent facial details, and unnatural motion. The second one turned into a general video restoration model designed for a wider range of scenes. While this preserved the flow of time, it often produced faces that were too smooth and generic, failing to preserve the unique identity of the subject. Neither approach can achieve sharp facial features and seamless movement at the same time. Based on these challenges, the research team recognized that there is an urgent need for a dedicated facial video restoration technique that jointly addresses both visual fidelity and temporal consistency.
A team from the School of Computing, Harbin Institute of Technology (HIT), China, has now published the first comprehensive study of deep learning-based facial video restoration technology (DOI: 10.1007/s11633-025-1623-x). Machine intelligence research (June 2026). This review systematically categorizes existing facial video restoration (FVR) techniques along three key aspects: network architecture, temporal modeling strategies, and facial detail enhancement, providing researchers with a unified framework to understand and advance this rapidly evolving field.
This research reveals a clear trajectory for how AI will approach video recovery. Early approaches were based on convolutional neural networks (CNNs) and generative adversarial networks (GANs). Although these are efficient for spatial details, they have limitations in capturing long-range temporal relationships. Recent transformer-based architectures have changed the game, using self-attention mechanisms to model global spatiotemporal dependencies across video sequences, dramatically improving temporal consistency and identity preservation. On the other hand, diffusion models (the same technology that underpins today’s state-of-the-art image generation equipment) have been adapted for video applications and provide excellent visual quality, but face a significant processing speed bottleneck due to the computationally intensive and iterative denoising process.
In terms of time, the researchers identified four different strategies. One is a short time window that fuses information from 3 to 5 adjacent frames. Recursive propagation to pass historical information forward. Global temporal modeling that captures complete sequence dependencies. A temporally extended diffusion model that extends 2D diffusion to the video domain. When it comes to enhancing facial details, methods fall into three groups. It is a pre-driven approach that leverages facial landmarks and identity features. Generation support technology that redraws realistic textures. Facial region-specific optimization that focuses on facial regions while simplifying background processing. Quantitative evaluation on benchmark datasets shows that our dedicated FVR method significantly outperforms both image restoration and general video restoration approaches across metrics measuring clarity, pose consistency, and temporal smoothness.
“The biggest challenge in facial video restoration is not only making each frame look good, but also ensuring that faces remain recognizable and move naturally from one frame to the next,” the authors said. “Our research shows that the field is moving toward a unified framework that jointly optimizes temporal consistency, perceived quality, and identity fidelity. That’s where the real breakthroughs are happening.”
Its influence extends far beyond academic curiosity. High-quality facial video restoration has the potential to revolutionize video conferencing by eliminating connection failures in real time, breathe new life into historical archives and degraded film footage, and enhance security and surveillance footage for law enforcement and forensic analysis. In entertainment and media production, this technology promises to salvage poorly shot footage and streamline post-production workflows. As video communications continue to dominate professional, educational, and social interactions, the ability to reliably recover and enhance facial footage will become increasingly important, not only for aesthetic purposes, but to ensure that critical visual information remains usable and reliable in an AI-driven world.
###
References
Toi
10.1007/s11633-025-1623-x
Original source URL
https://doi.org/10.1007/s11633-025-1623-x
Funding information
This research was supported by the National Natural Science Foundation of China (Nos. 623B2032, 62471158, 62501189 and 62502127), and in part by the China Postdoctoral Science Foundation (No. 2025M774316).
About Machine intelligence research
Machine intelligence research The International Journal of Automation and Computing is published by Springer and sponsored by the Institute of Automation, Chinese Academy of Sciences. The journal publishes high-quality articles on original theoretical and experimental research, targets special issues on emerging topics, and strives to bridge the gap between theoretical research and practical applications.
journal
Machine intelligence research
Research theme
not applicable
Article title
Deep learning-based facial video restoration techniques: A survey
Article publication date
May 11, 2026
Conflict of interest statement
The authors declare that they have no competing interests.
Disclaimer: AAAS and EurekAlert! We are not responsible for the accuracy of news releases posted on EurekAlert! Use of Information by Contributing Institutions or via the EurekAlert System.


