The results of this study suggest that both the end-to-end CNNs and the hybrid CNN–ML approach achieve excellent discriminative capacity in the identification of CTRC, with AUC values of 0.956 [95% CI: 0.937–0.975] and 0.961 [95% CI: 0.945–0.975], respectively. This high diagnostic efficacy is consistent with current literature, as highlighted by He et al.29, positioning DL as the current gold standard for anomaly detection in MSK radiography and overcoming the limitations of manual feature engineering. Our findings suggest the maturity of automated systems in identifying complex structural patterns with high clinical reliability.
Specifically, recent evidence demonstrates that CNN-based models can match or surpass the diagnostic accuracy of specialized clinicians across diverse anatomical regions, such as wrist and shoulder, with AUC values consistently exceeding 0.9230,31,32. Beyond traumatic pathology, the robustness of these models has been successfully extended to analyzing degenerative cervical spondylosis and altered spinal cord signal on MRI33, and classifying MSK tumors through automated segmentation and predictive classification using DL and radiomics34. These advancements consolidate AI as a versatile and multidisciplinary support tool in modern radiology.
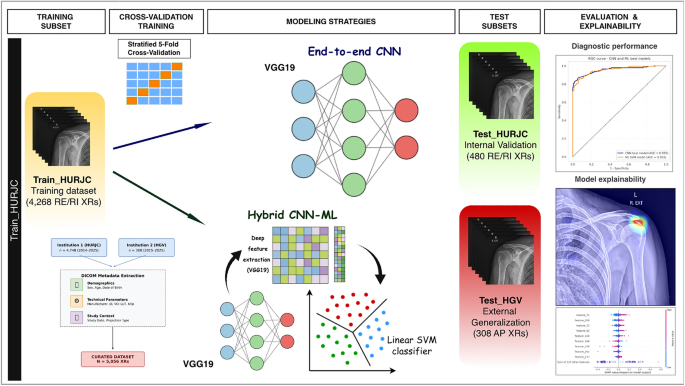
A critical observation in our study is the diagnostic parity between both modeling strategies. This empirical finding suggests that the convolutional backbone serves as a highly effective domain transformer, capturing radiological patterns–such as high calcium density relative to soft tissue–so robustly that the resulting hierarchical representations are informative enough on their own, regardless of the downstream classifier. The absence of statistically significant differences and 95% CI overlap between the end-to-end CNN and the hybrid pipeline indicates that the deep features extracted by the VGG19 architecture are sufficiently discriminative.
This finding is further supported by the architecture of our end-to-end model, which utilizes a single output neuron with sigmoid activation following the convolutional backbone. By omitting additional hidden layers in the classification stage, the network is constrained to perform a linear separation in the high-dimensional feature space. The fact that this streamlined design matches the performance of optimized ML algorithms, such as the SVM, suggests that the convolutional architecture successfully projects the XRs into a latent space where healthy and pathological classes are linearly separable. From a computational perspective, this implies that the VGG19 backbone has already resolved the problem’s complexity within its convolutional layers, simplifying the final decision boundary. If the classification task involved complex non-linear dependencies at its final stage, the use of a single neuron would have significantly hindered performance, necessitating a multi-layer perceptron to model such boundaries.
Despite this diagnostic parity, the hybrid CNN–ML pipeline may still offer practical methodological advantages. By decoupling feature extraction from classification, the hybrid strategy enables the use of lightweight ML classifiers (e.g., SVM or RF) that can be retrained or fine-tuned to specific institutional cohorts or new hardware signatures in a fraction of the time and with lower GPU requirements than a full DL recalibration35. Ultimately, the hybrid approach serves as a flexible diagnostic tool that leverages the robust feature extraction of the VGG19 backbone while allowing for a more adaptable and resource-efficient integration into diverse hospital information systems.
The choice of VGG19 as a backbone reflects a strategy of architectural parsimony. While newer models like EfficientNet36 or Vision Transformers37 represent the state-of-the-art in general computer vision, VGG19 remains an established and robust backbone for identifying high-contrast structures in radiography. Recent evidence suggests that VGG-family architectures can offer stable performance in limited-data medical imaging settings, avoiding the over-parameterization and ’data-hunger’ typical of deeper models18,19,21,22. Furthermore, its simpler hierarchical structure facilitates the generation of precise, clinical-grade Grad-CAM saliency maps, whereas more complex models often produce noisier or fragmented activations.
Beyond architectural stability, this diagnostic parity also has significant implications for model generalization. As Menéndez Fernández-Miranda et al.38 demonstrated, DL models often encounter performance drops when deployed across different centers due to hardware-specific signatures and variations in X-ray device characteristics. This phenomenon is frequently linked to the ”texture bias” inherent in CNNs, as described by Geirhos et al.39, where models prioritize local pixel patterns over global anatomical shapes. In our study, the consistent performance across Canon and ATS Srl hardware suggests that the VGG19 backbone has learned to transcend these device-specific textures by prioritizing high-contrast morphological features and anatomical anchors. In the specific task of identifying CTRC, the challenge primarily involves detecting a highly dense, high-contrast structure–calcium–within a defined anatomical region, the rotator cuff. In this context, previously reported biases related to texture recognition may have had limited impact, as the target structure exhibits a substantial contrast and textural difference relative to surrounding tissues, facilitating its discrimination by the model.
Extending this robustness to the spatial domain, a notable finding of our study is the model’s ability to generalize across different radiographic projections. Although our architectures were primarily developed using ER and IR views, they demonstrated effective performance when evaluated on AP projections. This is likely due to the geometric similarity between AP and ER orientations, which facilitated a successful feature transfer of the calcific morphology. However, while this suggests a degree of projection-invariance, such robustness cannot be guaranteed for anatomically distinct views, such as abduction or Scapular Y-projections, which present substantial geometric variances. Given the lack of a universal consensus on shoulder radiographic protocols, this procedural heterogeneity underscores the ongoing challenges of domain shift in real-world DL deployment38,40.
This shift from texture to shape is visually confirmed by the model’s transparency, which reveals that its efficacy is rooted in the learning of anatomically coherent representations rather than spurious pixel noise. In pathological cases, Grad-CAM activation maps consistently corresponded to the anatomical location of the rotator cuff. Conversely, in healthy subjects, a systematic exploration pattern was observed across the glenoid, the humeral head, and the subacromial space. This ”selective attention” toward key anatomical landmarks is an emerging strategy in recent medical literature to ensure that AI systems avoid learning shortcuts, reinforcing the model’s robust generalization. Our model focuses on the components of the scapulohumeral joint to evaluate the integrity of the rotator cuff. This structural recognition is critical; as suggested by Raffy et al.41, accurate classification in computed tomography and MRI requires the network to fixate on stable structural landmarks–such as the iliac crests or the diaphragm–which is equivalent to our model’s reliance on the glenoid and humerus as reference ”anchors.”
A novel aspect of our findings is the model’s use of these regions to actively rule out pathology. This concept of ”Anatomical Attention Regions”, recently proposed by Nln et al.42 for organ segmentation, demonstrates that networks ”recognize” the location of vertebrae before delimiting soft tissues. In our study, the model recognizes the subacromial space as the critical search zone. Translated to our experiment, the network performs a systematic visual triage: if no diagnostic ”footprint of CTRC” is found after evaluating the glenoid and subacromial space, the subject is classified as healthy. This ability to use normal anatomy as ”negative evidence” to rule out pathology confers a diagnostic robustness superior to simple pixel-patch detection.
A finding of particular clinical relevance was the model’s robustness against radiological mimics. Notably, the inclusion of bone islands and metallic artifacts across both the CTRC and control cohorts ensured that these features did not serve as confounding factors. This balanced distribution–carefully maintained throughout the training and validation phases–allowed the system to accurately discriminate findings such as bone islands in the humeral head, which share densitometric similarities with calcifications, as well as extrinsic metallic hardware. The fact that these features did not compromise accuracy suggests that the system relies on subtle textural distinctions and anatomical localization rather than simple pixel intensity. By internalizing these spatial constraints and relying on stable anatomical anchors, the model prevents false positives in regions where calcifications are anatomically improbable.
However, error analysis revealed a sensitivity to technical quality: false positives were frequently associated with excessive noise or poor collimation that included irrelevant structures like the spine. Furthermore, false negatives reflected intrinsic limitations of 2D radiography, such as failing to detect subscapularis calcifications in specific projections or in patients with suboptimal positioning–limitations that are shared by specialists in routine clinical practice.
The hybrid framework provides an intermediate degree of explainability and enhances efficiency by reducing input dimensionality to a subset of 139 attributes via SHAP analysis28 without compromising diagnostic accuracy. Beyond this reduction, the consistency in feature attribution between the internal and external cohorts demonstrates the model’s capacity to capture universal signatures of CTRC, ensuring high generalization stability across different institutional contexts. However, a significant interpretability gap remains: these deep features are inherently non-semantic and lack a direct, intuitive correlation for the practitioner. While attributes such as feature_71 or feature_180 are statistically decisive for the model’s internal logic, they offer no immediate physiological insight into the underlying pathophysiology. Nonetheless, this hybrid approach acts as a crucial ”mathematical bridge”; by narrowing the decision-making process to a structured subset of stable descriptors, it moves away from the traditional ”black-box” towards a more transparent, albeit still technical, validation of model consistency.
In contrast, the explainability provided by the end-to-end CNN model offers significantly greater value for radiological practice; unlike the non-spatial quantification of the hybrid pipeline, the saliency maps generated via Grad-CAM provide direct localization that aligns with the radiologist’s visual assessment. This intuitive interpretability acts as a crucial decision-support tool, reinforcing the model’s inference and fostering trust for clinical integration. This preference for visual transparency is consistent with the emerging gold standard in medical AI, where recent end-to-end interpretable frameworks emphasize modeling the radiologist’s intentions through controllable architectures43,44,45. That said, it is important to acknowledge that both Grad-CAM and SHAP provide post-hoc explanations rather than direct causal insights. As such, these visualizations should be interpreted as descriptive maps of model attention–which may occasionally highlight regions correlated with but not causative of the pathology–rather than as absolute indicators of clinical transparency.
Despite the high diagnostic performance achieved, several limitations of this study must be acknowledged. First, the retrospective nature of the dataset necessitates future prospective trials to evaluate the model’s ’real-time’ clinical utility. Second, this study does not include a head-to-head comparison with radiologists. While such a comparison is a logical next step, our primary objective was to establish the technical feasibility of a hybrid AI framework for CTRC detection. In this context, the model is designed as a decision-support tool to optimize workflows, rather than a replacement for radiological expertise. Future research should focus on multi-reader studies to assess the synergistic effect of AI-assisted diagnosis on clinical accuracy and reporting time. Third, the balanced 1:1 sampling strategy excluded common concomitant shoulder pathologies. While this approach was essential to demonstrate the utility of AI in MSK for specifically resolving CTRC–a key step toward optimizing patient workflows–it does not fully reflect the complexity of routine radiology. In clinical practice, overlapping conditions such as advanced osteoarthritis, acute fractures, or degenerative joint disease could introduce ’noise’ into the inference process, potentially affecting false-positive or false-negative rates. Consequently, validating these models on ’unfiltered’ multi-label datasets is a critical requirement for clinical implementation to ensure robustness against real-world disease prevalence. Finally, while the external validation cohort encompasses significant technical variability in device manufacturers and radiographic projections, a specific stratified analysis by subgroup was not performed. Although the sustained high performance across these diverse conditions points toward model robustness, a more granular investigation into hardware-specific influence is warranted. Future multi-center evaluations should incorporate larger, balanced subgroups to formally quantify the impact of specific technical confounders on algorithmic performance.
To bridge the gap between research and clinical practice, we have developed a diagnostic support platform that implements both the end-to-end CNN and hybrid models. This tool–currently in its first iteration–allows for the native processing of DICOM, JPEG, and PNG formats, facilitating its testing with heterogeneous data sources in real-world environments. As a commitment to technological transfer and open science, the application is publicly available as a Hugging Face Space46.


