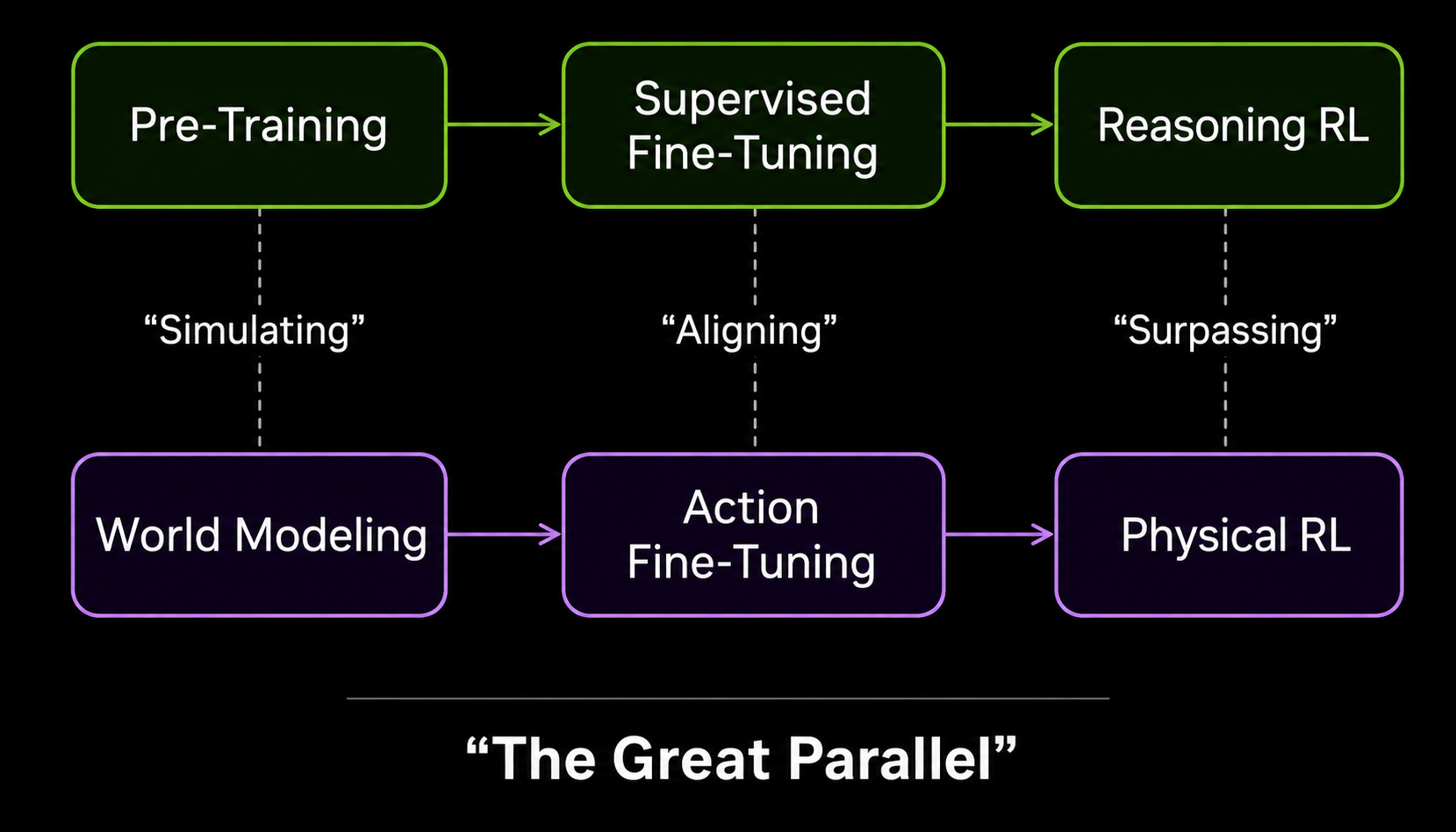
The robot AI investment community has a story it tells about its own future: world models will do for physical machines what transformers did for language. Pre-train on the dynamics of the physical world. Fine-tune on specific robot tasks. Scale until the capabilities compound. The recipe has a name — “The Great Parallel” — coined by Jim Fan, Director and Distinguished Research Scientist at NVIDIA, who presented the thesis at Sequoia Capital’s AI Ascent 2026 in April. The parallel has attracted serious money: approximately $6 billion flowed into world model companies in Q1 2026 alone.
One day ago, on June 17, Chinese startup Omega-EVA became the latest entrant, as a wave of new world model launches — including NVIDIA’s own Cosmos 3 omnimodel, released June 1 — signals the fastest expansion yet of physical AI investment. But the very speed of expansion may be hiding a structural problem. A new analysis from investors Charlotte Xia and Matt Wong at Fusion Fund argues that the LLM analogy is more wish than roadmap — and that the reason goes deeper than missing data or fragmented benchmarks. The physical world, unlike text, has no universal unit of training. There is no token. And that absence is why billions of dollars committed to competing architectures are not converging the way the transformer bet did.
A Definition That Shapes Everything That Follows
A world model, as researchers have come to use the term, is a system built around two functions: constructing an internal representation of how an environment works, and predicting future states to guide decisions. Jürgen Schmidhuber introduced the concept in machine learning as early as 1990. Yann LeCun revived and substantially extended it in a 2022 paper that proposed the Joint Embedding Predictive Architecture, or JEPA, as a practical foundation for machine intelligence. In the context of robotics, a world model means helping a physical agent — a robot arm, a humanoid, an autonomous vehicle — figure out what comes next without requiring expensive real-world trial and error for every new situation.
This is a meaningful departure from Vision-Language-Action models, or VLAs, the dominant paradigm of the past two years. VLAs map visual inputs and language instructions directly to robot motor commands in a single forward pass, inheriting the rich semantic priors of pretrained vision-language models. The weakness VLA researchers acknowledge: these models tend to learn demonstrated scenarios rather than the underlying physical dynamics, which makes them brittle in environments they haven’t specifically been trained for.
World models promise something more fundamental: instead of learning how one robot moves through one environment, they learn the dynamics of the physical world itself — dynamics that could in principle transfer across different robot bodies and tasks. That is the promise. Whether it is deliverable is what the field is currently fighting over.
NVIDIA Cosmos 3 and the Omnimodel Bet
The most direct institutional expression of the “Great Parallel” thesis arrived June 1, when NVIDIA launched Cosmos 3 at GTC Taipei during COMPUTEX. Built on a mixture-of-transformers architecture, Cosmos 3 is the first fully open omnimodel that can natively understand and generate text, images, video, ambient sound, and robot action data in a single system. NVIDIA says it trained Cosmos 3 on 20 trillion tokens of multimodal data, including nearly a billion images, 400 million real and synthetic videos, and action data from humans and robots. The explicit goal is to compress what would have been months of robot data collection into hours of compute time.
This matters for a specific reason beyond the product announcement. A 14-billion-parameter variant of NVIDIA’s DreamZero system, which uses a world-model-based approach, achieved a 2x improvement over state-of-the-art VLA baselines on zero-shot generalization — tasks and environments the model had never seen during training. In the same test, VLA models trained from scratch achieved near-zero task progress on unseen scenarios. Even pretrained VLA baselines, which had seen thousands of hours of cross-embodiment robot data, reached only 27% average task progress; DreamZero reached 62%.
The DreamZero result supplies something the world model thesis urgently needs: a specific, published, and falsifiable demonstration that learning physical dynamics from video rather than learning from task demonstrations can generalize in ways that task-trained VLAs cannot.
Why the Physical World Has No Equivalent of a Text Token
Here is the structural argument the Fusion Fund analysis does not fully name — but that the current landscape makes visible.
The LLM revolution happened because text is a single modality with a universal training unit: the token. Every sentence in English, code in Python, or recipe in French can be expressed as the same type of thing. That universality meant that training data from millions of disparate sources could be mixed without conflict. It meant that benchmarks comparing models from different labs were measuring the same fundamental capability. It meant that when the transformer architecture proved itself, the field could consolidate around it rapidly.
The physical world has none of these properties. A robot arm’s joint angles, a depth camera’s point cloud, a force torque sensor’s contact readings, and a wrist-mounted camera’s pixel stream are not the same type of thing. They cannot be naively combined into a universal training sequence the way web text can be combined into a language corpus. Each robot body has a different action space. Each sensor suite produces data with different dimensionality, frequency, and noise characteristics. There is no atom.
This is the structural reason, obscured by the excitement around individual results, that UC Berkeley roboticist Ken Goldberg put his finger on in a 2025 paper in Science Robotics: the amount of internet-scale data used to train contemporary large vision-language models is on the order of 100,000 years of equivalent human experience. The largest single teleoperated robot dataset collected to date is on the order of one year. That gap is not only quantitative. It is qualitative: no robot has access to the equivalent of the entire web. It cannot, because the physical world does not archive itself.
Three Ways to Represent the World, and No Clear Winner
Even among teams committed to world models, fundamental disagreements persist about how to represent physical reality inside a model. Three main camps have emerged.
Pixel-based models predict the world in raw visual detail, achieving photorealism and a lossless projection of scenes. The engineering tradeoff: they can waste enormous computational capacity reconstructing irrelevant visual texture — the reflection on a countertop, the specific grain of a wooden floor — rather than the physical dynamics that actually matter for robot decisions. DreamZero is a pixel-based model built on a video diffusion backbone; its computation is focused on predicting how scenes evolve over time, not on classifying them.
Explicit 3D geometric representations prioritize structure over appearance, encoding positions, shapes, and spatial relationships of objects rather than their visual fidelity. Within this camp, particle-based methods scatter dense points across objects to capture volume and surface; keypoint-based methods retain only task-relevant geometric anchors; object-centric representations model how discrete objects interact at the most abstract level. World Labs, co-founded by Fei-Fei Li with $1 billion in funding, is building toward explicit 3D representations. Its April 2026 Spark 2.0 release — a 3D Gaussian splatting rendering engine for smartphone-class devices — demonstrated one step in this direction.
Latent-based models, championed by LeCun through JEPA and its successors, represent the world as compact features sufficient to predict future states, discarding everything irrelevant. This approach wins on computational efficiency and generalization. The Dreamer series of papers by Danijar Hafner showed that agents can learn sophisticated behaviors entirely within latent “imagined” futures, never touching real-world pixels during planning. AMI Labs, the company LeCun founded in early 2026, raised $1.03 billion on this thesis. The cost: latent models sacrifice interpretability, making it harder to diagnose failures when they occur.
An emerging view in the research literature advocates for hybrid representations — combining explicit geometric grounding with latent features. It is a promising direction. It is also active research, not a settled solution.
Where the Leaderboard Tells a Complicated Story
The early results do not produce a clear winner. Physical Intelligence, whose π0.7 model drew widespread attention in April for demonstrating emergent generalization — handling an air fryer the model had seen in only two training episodes — spent time convinced that world models would dramatically outperform VLA approaches, until its own VLA baseline caught up as more data was added.
The RoboArena benchmark, which ranks robot control policies using crowd-sourced pairwise comparisons adapted from LLM evaluation methodology, shows scores shifting significantly week to week between the two approaches. DreamZero posted a 1,750 Elo score on one RoboArena snapshot; recent VLA baselines are tracking closely. NVIDIA’s own technical blog noted in June 2026 that there is currently “no real winner between WAMs and VLAs,” and it is unclear whether there will ever be a single dominant paradigm.
Meanwhile, other approaches are entering the race entirely. Generalist, one of the companies in NVIDIA’s Cosmos Coalition, trained its GEN-1 system almost entirely from scratch on half a million hours of physical interaction data captured from low-cost wearable devices — no video generation backbone, no VLM foundation. The approach is a direct challenge to the premise that internet-scale pretraining is necessary.
What Is the Difference Between a VLA and a World Model?
A VLA, or Vision-Language-Action model, takes a camera image and a language instruction as input and produces motor commands — joint angles, gripper positions, trajectory waypoints — as output. The model learns by observing demonstrated robot behavior and mapping those observations to actions. It inherits the semantic understanding of large pretrained vision-language models but learns manipulation behaviors by treating them as a prediction task on top of that prior. The key limitation is that it does not explicitly model what the physical world will look like after a robot acts in it; it learns which actions to take from demonstrations of actions.
A world model, by contrast, learns to predict the future state of the environment as a function of current state and robot action. It builds an internal simulation of how scenes evolve — how an object moves when grasped, how its orientation changes when rotated, where it ends up when released. A robot policy trained using a world model can imagine the consequences of its actions before taking them, which is what enables zero-shot generalization: the robot has never seen this specific scenario, but the world model has learned the underlying physics that governs it.
The practical difference shows up most clearly on novel tasks. VLAs tend to succeed on tasks that resemble their training demonstrations closely and fail on tasks that are structurally different. World models, when they work, generalize across structural variation — because they are learning physics, not behavior patterns.
Why Robots Face a 100,000-Year Data Deficit
The data problem underlying all of this is documented and severe. The amount of internet-scale data used to train contemporary large vision-language models is equivalent to approximately 100,000 years of human experience, expressed in the text and image tokens those models are trained on — a figure Ken Goldberg of UC Berkeley calculated in his 2025 Science Robotics paper by applying standard metrics for converting word and image tokens into human-time equivalents.
Closing that gap requires finding data sources that actually scale. Teleoperated robot data is precise but expensive and slow. The largest open-source teleoperated dataset, Open X-Embodiment, pooled 60 separate datasets from 21 institutions to reach roughly 1 million trajectories — still orders of magnitude below the scale at which language models learned to generalize. Lightweight wearable capture using head-mounted cameras and wrist-mounted sensors occupies a middle ground, enabling human demonstration data without requiring a robot in the loop.
Web video is the most abundant option, by many orders of magnitude. The critical question is whether a model can extract meaningful physical dynamics from video — learning not just what actions look like, but what the physical consequences of those actions are. The DreamZero results offer the most direct evidence to date that video can serve as a substrate for learning physical dynamics: just 12 minutes of egocentric human video improved performance on unseen robot tasks by more than 42%.
Two Bottlenecks Blocking Convergence
The Fusion Fund analysis identifies two systemic problems preventing the kind of rapid consolidation the LLM community achieved after the transformer paper.
The first is the absence of shared evaluation. LLMs converged in part because Chatbot Arena and equivalent benchmarks gave the community a common yardstick. Embodied AI has no equivalent. Robot tasks are far more diverse than language tasks. Success is frequently ambiguous. Real-world testing remains the gold standard but is expensive and difficult to reproduce. Benchmark overfitting is rampant — models are tuned to known evaluation tasks in ways that inflate scores without improving underlying generalization. WorldGym, a system from Sherry Yang’s lab, attempts to use world models themselves as simulation environments for policy evaluation, which could reduce the cost of benchmarking; RoboArena borrowed crowd-sourced pairwise comparison methodology from LLM evaluation but is currently limited to a single hardware platform and a limited task set.
The second bottleneck is structural: the capital already deployed sustains divergence. AMI Labs raised $1.03 billion on a latent-space thesis. World Labs raised $1 billion on explicit 3D representations. Physical Intelligence raised $600 million on VLA approaches. Each company has multi-year runway. With that runway and little incentive to open-source research advances, divergence is not a temporary condition — it is, as the Fusion Fund report argues, the rational equilibrium for now.
Where Durable Businesses Can Be Built
Despite skepticism about convergence speed, Xia and Wong identify structural positions that should hold value even if a dominant paradigm does not emerge on any particular timeline.
In the near term, the most defensible position belongs to full-stack, vertical-specific companies that own model development, hardware integration, and forward deployment as a closed loop. A model team without deployment access has no path to the real-world training signal that matures capability in actual factory floors, hospital corridors, or warehouse aisles. A deployment team without model control cannot fix underlying failures when they surface on-site. The competitive moat is not the architecture — it is the data flywheel that real deployment generates.
Evaluation infrastructure is critically underinvested, the analysis argues, presenting an opportunity for companies that can build the shared measurement layer the field currently lacks. Data curation platforms that can efficiently filter, annotate, and structure training data for long-horizon tasks — particularly for tasks requiring force and tactile feedback beyond the five-second clips most current models train on — represent another high-value layer.
If a dominant pre-training paradigm eventually emerges, open-source models and commoditized hardware could create a new wave of vertically integrated deployment companies. Infrastructure for edge computing and real-time robot control would become contested territory. That moment is not here yet.
Can World Models for Robots Really Follow the LLM Playbook?
The LLM revolution hinged on a convergence that took years to recognize as such: after “Attention Is All You Need” in 2017, the transformer architecture proved so general and so scalable that the entire field reorganized around it. Scaling laws held across orders of magnitude. Capital and talent consolidated. A community with fragmented approaches became, within roughly five years, a community running the same architecture on everything.
Whether embodied AI reaches an equivalent inflection point remains genuinely uncertain — and the reasons for uncertainty go beyond the ones most often cited. The data gap is real, but it is a solvable engineering problem. The benchmark fragmentation is real, but it is a coordination problem. The deeper problem is structural: text had a universal atom, and that made convergence tractable. The physical world does not. The body of a humanoid robot, the camera of an autonomous vehicle, and the wrist sensor of a factory arm produce fundamentally different types of data that cannot be combined without choices the LLM field never had to make.
Jim Fan’s Great Parallel is a compelling framing. Whether it describes the future of embodied AI, or the ambitions of those building it, may depend on whether the field can find a universal physical token — or whether it turns out that the physical world is fundamentally irreducible in ways that language, across all its variety, was not.
Frequently Asked Questions
What are world models in embodied AI?
World models are AI systems that build internal representations of how physical environments work and predict future states based on current conditions and robot actions. Unlike systems that learn to map inputs directly to actions, world models learn the underlying dynamics of scenes — how objects move, collide, and change state when a robot interacts with them. They act as internal simulators that allow a robot to “imagine” the consequences of an action before committing to it, enabling generalization to situations that weren’t part of the training data.
What is the difference between a VLA and a world model for robotics?
A VLA, or Vision-Language-Action model, maps camera images and language instructions directly to robot motor commands, learning from demonstrations of robot behavior. A world model instead learns to predict how the physical environment will change in response to a robot’s actions — it builds a physics simulator, not a behavioral repertoire. The practical consequence is that well-performing world models can generalize to novel tasks by reasoning about physical consequences, while VLAs tend to fail on scenarios that differ structurally from their training demonstrations.
Why is the 100,000-year data gap a problem for robot learning?
UC Berkeley roboticist Ken Goldberg calculated in a 2025 Science Robotics paper that the internet-scale data used to train today’s vision-language models is equivalent to approximately 100,000 years of human experience in text and images. The largest open-source teleoperated robot dataset is equivalent to roughly one year. That gap is not only about quantity — it is structural. The physical world does not generate its own training corpus the way the internet generates text. Every meaningful robot training example requires either real physical interaction, simulation with reliable physics, or video that can be parsed for physical dynamics. None of these scales the way web scraping scales.
Why hasn’t the robotics field converged on a single world model architecture the way AI converged on transformers?
The LLM community converged on transformers in part because language is a single modality with a universal unit — the token — that made data mixing, cross-lab comparison, and architectural competition tractable. The physical world has no equivalent universal unit. A robot arm’s joint angles, a depth camera’s point cloud, and a wrist-mounted camera’s pixel stream are fundamentally different types of data that cannot be naively combined. That structural absence — not just missing data or fragmented benchmarks — is the deepest reason competing world model approaches are not converging yet.


