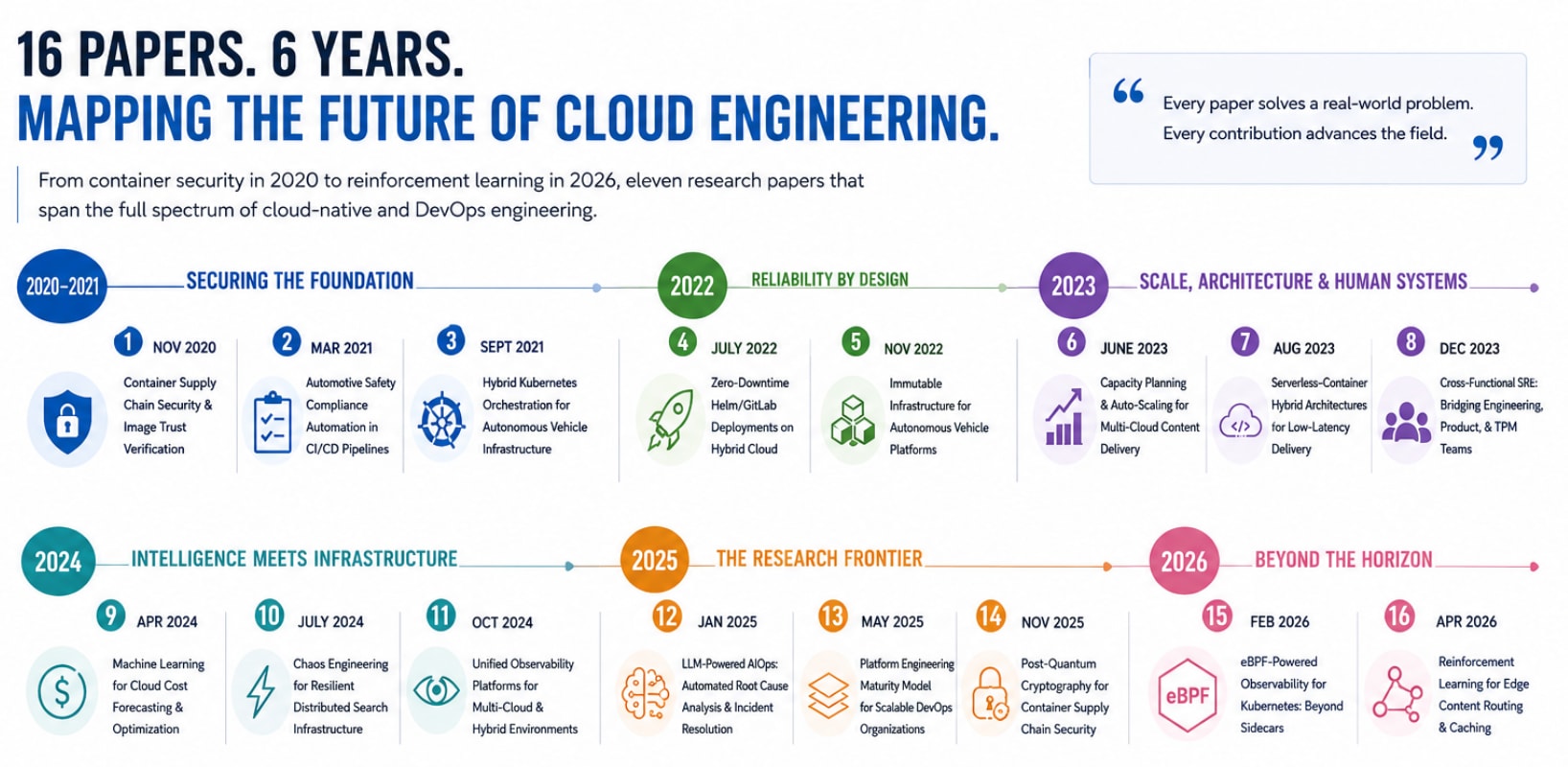
Some bodies of research accumulate through small, incremental contributions – each paper extending the one before by a modest degree, the whole adding up to something useful if rarely remarkable. And then there are research records that read differently: as acts of sustained, deliberate mapping of territory that the field had not yet adequately charted, each paper choosing its subject with intention and executing it with depth. Rohit Reddy’s sixteen-paper research record, spanning six years and nearly the full breadth of cloud-native and DevOps engineering, belongs firmly in the second category.
By May 2026, the DevOps and Cloud Engineer has published sixteen peer-reviewed research papers. The first appeared in November 2020. The most recent appeared in April 2026. Between them lies a body of work that moves from the security foundations of container infrastructure to the application of artificial intelligence to cloud operations, from the compliance requirements of automotive safety-critical software to the frontier of quantum-resilient cryptography, from the human organizational systems of site reliability engineering to the reinforcement learning algorithms that now govern how the largest content delivery networks route traffic at the edge. It is, taken as a whole, an extraordinary record – and one that the cloud engineering community has every reason to know well.
“Sixteen peer-reviewed papers in six years. Each one addressing a problem that practitioners were actually struggling with. That is not ambition for its own sake – that is service to a field.”
2020 – 2021
Securing the Foundation: Supply Chains, Safety Standards, and Hybrid Orchestration
Reddy’s first published paper, released in November 2020, announced a researcher whose instincts were already well ahead of the industry conversation. Container supply chain security – the question of whether the software images flowing through a CI/CD pipeline from developer commit to production deployment are genuinely, cryptographically what they claim to be – was not yet the priority it would become in the years that followed, when a series of high-profile supply chain compromises forced the technology industry to confront the vulnerability it had been building into its delivery processes. Reddy had already identified it, already investigated it rigorously, and already developed a framework for addressing it using the cryptographic trust infrastructure that the cloud-native ecosystem provides. His paper on the subject remains, for the engineering teams that have since been compelled to take supply chain security seriously, a reference of unusual practical authority.
The two papers he published in 2021 demonstrated a range that has characterized his research ever since. The first moved into the domain of automotive software safety compliance – one of the most demanding regulatory environments in which software engineers operate – and confronted the challenge of encoding its requirements into the automated gates of a continuous delivery pipeline. ISO 26262 and MISRA C are not guidelines; they are engineering standards whose violation can have consequences measured in human safety. The conventional approach to automotive software compliance had been built around manual review processes designed for a world that moved at human speed. Reddy’s paper showed how automated static analysis tooling could enforce these standards at the speed of a build pipeline, transforming compliance from a late-stage bottleneck into a built-in property of every code change.
His second 2021 paper tackled the infrastructure orchestration challenge that autonomous vehicle platforms present – environments where cloud-hosted and edge-deployed Kubernetes clusters must be managed as a single, coherent operational whole across network boundaries and administrative domains. The framework he developed for bridging managed cloud Kubernetes services with on-premises deployments gave engineering teams building autonomous mobility infrastructure a validated architectural blueprint at the precise moment when those teams were making foundational decisions about how their infrastructure would be organized for years to come.
2022
Reliability by Design: Zero-Downtime Deployments and Immutable Infrastructure
The two papers Reddy published in 2022 deepened his research into the reliability and infrastructure layers of cloud-native engineering – and each addressed a problem whose inadequate treatment in the existing literature had real operational costs for the engineering teams working in that space.
His July 2022 paper gave platform engineers the framework they had been missing for managing Helm-based deployments across hybrid cloud environments without service interruption. Zero-downtime deployment sounds like a solved problem until you are the engineer responsible for guaranteeing it across a hybrid infrastructure with different scaling characteristics, network topologies, and failure modes on either side of the cloud-on-premises boundary. The paper worked through every dimension of the challenge – from readiness probes and rollback strategies to traffic management and observability instrumentation – with the thoroughness of someone who had experienced the consequences of getting it wrong and had done the systematic work of understanding why.
His November 2022 paper applied the principles of immutable, version-controlled infrastructure to the specific and demanding requirements of autonomous vehicle software platforms. In most engineering contexts, the configuration drift that accumulates in mutable infrastructure over time is an operational inconvenience. In the context of software that governs the behavior of a vehicle in motion, it is a potential safety failure mode. Reddy’s paper brought the rigor of infrastructure-as-code principles – building from version-controlled specifications, replacing rather than modifying, maintaining a complete audit trail of every infrastructure state – to this domain with the precision it demands.
“In safety-critical domains, the gap between the infrastructure you intended and the infrastructure you have is not a technical debt problem. It is a safety problem. Reddy’s 2022 work closed that gap with engineering discipline.”
2023
Scale, Architecture, and the Human Systems Behind Distributed Delivery
The three papers Reddy published in 2023 extended his research into new territory – the large-scale content delivery infrastructure of the kind that serves hundreds of millions of users globally – while also expanding its scope to include something that technical research rarely addresses with adequate seriousness: the organizational and human systems through which technical excellence actually reaches production.
His first 2023 paper addressed the challenge of capacity planning and auto-scaling for distributed content delivery across multi-cloud platforms – developing forecasting and scaling frameworks designed for environments where traffic patterns are volatile, where demand spikes can be sudden and enormous, and where the infrastructure that serves that traffic is distributed across multiple cloud providers with different capacity models and scaling characteristics. The problem of predicting and provisioning for content delivery load at this scale is as much a data science challenge as an infrastructure challenge, and Reddy’s paper addressed both dimensions with equal rigor.
His second 2023 paper investigated the architectural question of how serverless functions and containerized services can be combined in hybrid architectures that leverage the strengths of each for low-latency content delivery at significant scale. The research was grounded in the operational realities of serving digital experience infrastructure to a global user base – the kind of environment where the performance characteristics of the architecture have direct and measurable consequences for user experience quality, and where the cost and operational trade-offs of different architectural choices play out at a scale that makes the differences meaningful.
The third 2023 paper was, in a different way, the most significant of the year – an investigation of cross-functional site reliability engineering that addressed the organizational dimension of distributed systems reliability directly. Engineering teams do not operate in isolation. The reliability of the systems they build and operate is shaped not only by the technical decisions they make but by the organizational dynamics between SRE teams, product management, and technical program management – the alignment of priorities, the shared understanding of trade-offs, the processes through which reliability investment is planned and communicated across functional boundaries. Reddy’s paper gave practitioners a framework for navigating these organizational realities with the same discipline that they bring to the technical ones.
2024
Intelligence Meets Infrastructure: AI, Chaos, and the Unified View
If the first four years of Reddy’s research established the depth and breadth of his technical range, 2024 marked the year his scholarship moved decisively into the territory that now defines the leading edge of cloud engineering practice: the application of artificial intelligence and machine learning to the operational challenges of large-scale distributed infrastructure.
His first 2024 paper applied machine learning to cloud cost forecasting and resource optimization – developing models capable of learning the cost signatures of complex, multi-service cloud environments and translating those forecasts into specific optimization recommendations. Cloud cost management had grown, by 2024, from a matter of reading billing dashboards to a discipline requiring algorithmic approaches capable of processing the scale and variety of cost signals that modern cloud infrastructure generates. Reddy’s paper made a substantive methodological contribution to the FinOps discipline, providing a research foundation for the ML-based forecasting approaches that the field had been developing in practice without adequate theoretical grounding.
His second 2024 paper brought chaos engineering – the practice of intentional, controlled failure injection – to the specific context of distributed search infrastructure built on Elasticsearch. The paper developed a systematic catalog of fault injection experiments, the observability instrumentation required to interpret their results, and the resilience improvement patterns that address the vulnerabilities the experiments expose. For the large community of engineering teams operating Elasticsearch at production scale, it filled a gap in the chaos engineering literature that had been felt acutely.
The third 2024 paper addressed the observability fragmentation that multi-cloud and hybrid infrastructure strategies create – the problem of assembling coherent insight into distributed system behavior from the partial, incompatible views offered by multiple cloud providers’ native observability platforms. His framework for building unified observability across AWS, Azure, and on-premises infrastructure gave engineering organizations the architectural foundation for observability practices equal to the complexity of the environments they now operate.
“Three papers in 2024. Machine learning applied to cloud economics. Chaos engineering for distributed search. Unified observability across cloud boundaries. The intelligence layer of cloud engineering, mapped with the same rigour Reddy has brought to every layer before it.”
2025 – 2026
The Research Frontier: AIOps, Platform Engineering, Quantum Cryptography, eBPF, and Reinforcement Learning
The five papers Reddy has published in 2025 and 2026 represent the current frontier of his research – and they venture into territory that places him at the leading edge not merely of cloud engineering practice but of the broader technology disciplines that cloud engineering now intersects.
His January 2025 paper applied large language models to the operational challenge of automated root cause analysis and incident resolution in large-scale cloud environments – the AIOps vision of infrastructure that can identify the source of its own failures and initiate resolution actions without requiring human diagnosis at each step. The paper developed a framework for LLM-powered incident response that addresses the practical engineering challenges of applying language model intelligence to the structured and unstructured signal data of cloud operations, while maintaining the auditability and safety constraints that production incident management requires.
His May 2025 paper addressed the maturity of platform engineering practice – the discipline of building the internal developer platforms, golden paths, and self-service infrastructure abstractions that allow engineering organizations to scale their delivery capacity without scaling their coordination overhead proportionally. His maturity model gave engineering leaders a structured framework for evaluating where their platform engineering practice stands and what advancing it looks like – practical guidance for one of the most consequential investments that large engineering organizations can make in their own productivity.
His November 2025 paper returned to the supply chain security domain where his research began – but at a frontier that, in 2020, existed only in the theoretical work of cryptographers. Post-quantum cryptography is the effort to build cryptographic systems that remain secure against the computational capabilities of quantum computers. The paper brought this frontier to the specific context of container supply chain security, investigating how the cryptographic trust frameworks that govern container image signing and verification can be made resilient to quantum attack – a contribution that addresses a security challenge whose urgency is growing as quantum computing capabilities advance.
His February 2026 paper explored eBPF – the extended Berkeley Packet Filter, a kernel-level programmability mechanism that has become one of the most significant infrastructure technologies in the Linux ecosystem – as a foundation for Kubernetes observability. The paper investigated how eBPF-based instrumentation can replace the conventional sidecar proxy model for cluster observability, reducing the performance overhead and operational complexity of monitoring while improving the depth and fidelity of the signals collected. For the engineering teams operating large Kubernetes clusters where the overhead of per-pod sidecar proxies compounds significantly at scale, this paper offers an architecturally cleaner and operationally lighter alternative backed by rigorous empirical analysis.
His most recent paper, published in April 2026, brought reinforcement learning to the challenge of content routing and edge caching in hyperscale content delivery networks – applying machine learning techniques that learn optimal routing and caching strategies through interaction with the environment to one of the most computationally demanding optimization problems in cloud infrastructure. The research represents the convergence of two threads that have run through Reddy’s work since 2023: his investigation of large-scale content delivery infrastructure and his engagement with the machine learning approaches that are transforming how cloud systems are operated and optimized.
THE WHOLE RECORD
What Sixteen Papers Mean
The scope of Rohit Reddy’s research record is, by now, sufficient to speak for itself. Sixteen peer-reviewed publications in six years, spanning container security, automotive compliance, hybrid orchestration, deployment reliability, immutable infrastructure, content delivery scale, serverless architecture, organizational systems, cloud cost intelligence, resilience engineering, observability, AIOps, platform engineering maturity, post-quantum cryptography, eBPF-powered observability, and reinforcement learning for edge content routing. The list resists easy summarization because its range is genuinely remarkable.
What does not resist summarization is the quality that has characterized every paper in the record: a genuine and consequential problem, rigorously investigated, with findings specific and grounded enough to be immediately useful to the practitioners who need them. This has been true of Reddy’s first paper and his sixteenth. It has been true in the years when the cloud engineering community was focused on the security of its delivery pipelines, and in the years when it was focused on the application of AI to its operational challenges. The research agenda has evolved as the field has evolved. The standard has not changed.
For the engineers, architects, and technology leaders who work in cloud infrastructure, DevOps automation, site reliability engineering, content delivery, and the emerging domains of AIOps and platform engineering, Reddy’s sixteen papers represent a body of knowledge that is, collectively, indispensable. The field is more secure, more reliable, more observable, more cost-efficient, more intelligently automated, and better organized because this work exists and because it was done to the standard it was done to.
Vocal.Media covers professionals whose contributions to their fields are substantial enough to warrant public attention. By that standard, Rohit Reddy’s research record is among the most significant practitioner contributions to cloud and DevOps engineering that this platform has had the occasion to document. Sixteen papers. Six years. A discipline that is measurably better served for all of it.


