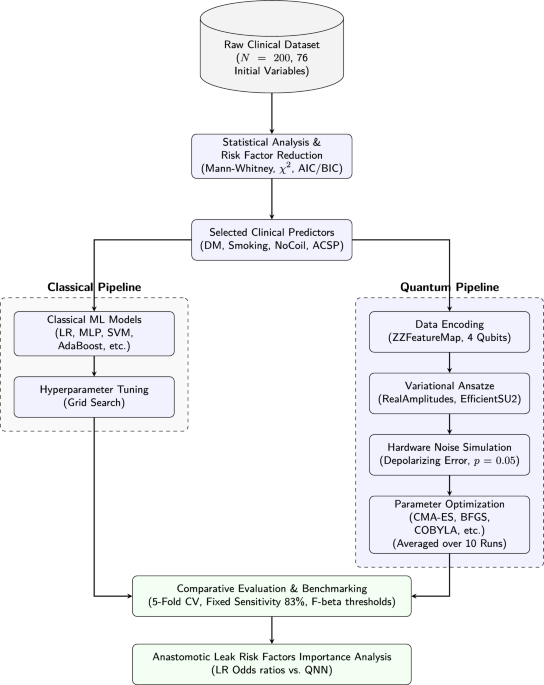
This section details the experimental pipeline utilized to predict anastomotic leak outcomes and identify risk factors. We first introduce the medical problem in detail, define the clinical cohort, and outline all patient variables, including surgical techniques, patient history, and physiological markers with their respective units. Prior to any machine learning tasks, we perform rigorous statistical analyses and feature reduction to isolate the most significant clinical predictors. Building on this clinical foundation, we introduce the quantum machine learning methodology, detailing the design of our parameterized quantum circuits using specific data encoding maps and variational ansatze that we compare with classical machine learning models (Fig. 1).

Workflow of the proposed methodology, detailing the end-to-end pipeline from clinical data preprocessing and risk factor selection to the parallel evaluation of classical models and noisy quantum neural networks, concluding with performance benchmarking and risk factor importance analysis.
Problem description
Anastomotic leak is a severe complication following colorectal surgeries, particularly low rectal resections with total mesorectal excision for cancer. When treating malignant or large benign tumors in the colorectal area, the affected section of the intestine must be removed, and the two remaining ends are surgically reconnected. If the anastomotic site does not heal properly, it can rupture, leading to anastomotic leak. This complication is associated with significant morbidity and mortality, occurring in approximately 14% of cases in our dataset and contributing to up to 40% of surgery-related deaths. Identifying risk factors for anastomotic leak and developing predictive models are essential for improving patient outcomes.
Our study utilizes data collected from the Surgical Department of Hospital Nový Jičín a.s. between 2015 and 2016, comprising 200 patients (28 with an anastomotic leak, 172 without). The dataset includes 76 explanatory variables, categorized into two main groups: intraoperative techniques and patient history variables. The primary goal of this study was to identify the statistical significance of intraoperative techniques such as NoCoil, ACSP, PERFB, and ICG, and to identify potential risk factors for anastomotic leak occurrence. Furthermore, we aimed to establish if we could predict anastomotic leak from the significant factors associated with its occurrence. We will particularly focus on smoking status (Smoking), Diabetes Mellitus (DM), preservation of the left colic artery (ACSP), and the use of a transanal drain (NoCoil), as these were found to be statistically significant in a later chapter. We will delve more into the ACSP factor rather than ICG, given that the effectiveness of ICG has already been thoroughly assessed and studied on data used in this study1 and elsewhere54. This predictive analysis will be conducted using both classical machine learning methods and a novel quantum-enhanced approach.
Approval for human experiments: This study was approved by the institutional review board of Hospital Nový Jičín a.s., and all experiments were performed in accordance with the relevant guidelines and regulations. Informed consent was obtained from all participants and/or their legal guardians. We have obtained confirmation from the doctors and surgeons who conducted the study that we are permitted to use this data for our research.
This study specifically evaluates the performance of classical and quantum classifiers on raw clinical data without modifications, preserving the natural distribution of cases. This approach ensures ecological validity, providing a realistic assessment of classifier performance in clinical settings. By avoiding techniques like SMOTE or stratified sampling, we maintain the dataset’s inherent imbalance, which reflects the real-world prevalence of anastomotic leak. This allows for a direct and fair comparison between classical and quantum approaches under identical, real-world conditions.
To mitigate overfitting risks, we reduced the number of variables through statistical analysis, including goodness-of-fit tests and risk ratios, and selected features based on medical importance in consultation with clinicians. This feature selection process not only enhances model interpretability but also ensures that the models are trained on clinically relevant predictors, reducing the risk of overfitting despite the small sample size.
Our analysis incorporates several key variables that are critical to understanding the surgical procedure, its immediate impact on the patient, and the patient’s overall health context. These are summarized in Table 1.
Among these factors, the preservation of the left colic artery (ACSP variable) plays a crucial role in maintaining blood supply to the descending and sigmoid colon. During colorectal surgery, the preservation of the left colic artery is often considered beneficial for ensuring adequate perfusion (PERFB) of the anastomotic site, thus promoting healing and reducing the risk of anastomotic leak55. However, in some cases, its preservation may not be feasible due to anatomical constraints or oncological requirements.
Another factor influencing anastomotic leak risk is the use of a transanal drain. NoCoil refers to a silicone-based tube, typically 1.5 to 2 cm in diameter, inserted into the rectum at the end of the surgery to decompress the rectal stump and protect the anastomosis. This device facilitates passive evacuation of gas and residual stool, reducing intraluminal pressure and helping to minimize the risk of leakage56.
Diabetes Mellitus and Smoking have been consistently identified as significant risk factors for anastomotic leak57, primarily due to their effects on vascular health and immune response. Similarly, smoking has been shown to impair tissue oxygenation and angiogenesis, further contributing to poor anastomotic healing.
Recent advancements in intraoperative monitoring, such as fluorescence angiography with indocyanine green (ICG), offer a potential method for reducing anastomotic leak incidence by providing real-time visualization of bowel perfusion. Studies indicate that the use of ICG during surgery may improve anastomotic outcomes by allowing surgeons to identify poorly perfused areas and adjust their technique accordingly58.
Risk factors such as diabetes, smoking, and the absence of transanal drain have been consistently linked to higher rates of anastomotic leak in surgical literature. A systematic review and meta-analysis by He et al. confirmed that diabetes and smoking significantly increase the risk of anastomotic leak following colorectal surgery, alongside other factors such as male sex and intraoperative blood transfusion59. Similarly, Awad et al. highlighted that intraoperative complications, prolonged surgery duration, and inadequate tissue perfusion contribute to higher postoperative anastomotic leak rates60.
Novel intraoperative techniques, such as fluorescence angiography (FA), have shown promise in reducing anastomotic leak incidence. Lin et al. conducted a meta-analysis demonstrating that the use of intraoperative indocyanine green (ICG) fluorescence angiography significantly reduces anastomotic leak rates in colorectal resections by improving the assessment of bowel perfusion61. More recent work by Balamurugan et al. further supports this, emphasizing that FA leads to better anastomotic outcomes, though additional large-scale studies are needed to validate its routine clinical application62.
While existing studies emphasize biological and clinical interventions, recent efforts have explored predictive modeling for anastomotic leak. Venn et al. reviewed preoperative and intraoperative scoring systems designed to predict anastomotic leak occurrence, revealing that although current models provide some predictive power, they remain limited by variability in surgical techniques and patient-specific factors63. Our work introduces a computational perspective by leveraging advanced machine learning and quantum computing to enhance anastomotic leak prediction models, potentially improving clinical decision-making and patient outcomes.
Statistical analysis of patient data
Guided by established clinical literature and surgical constraints, initial exploratory statistical analysis of patient data was performed to assess the significance of the selected explanatory variables. In Table 2, the structure of the patient cohort is presented based on the occurrence of leaks and the treatment methods used. In Table 3, the structure of the patient cohort is presented based on the occurrence of leaks and variables describing the patient’s medical history.
The analysis shows that the occurrence of leaks is significantly associated with the insertion of a special rectal tube (variable NoCoil). As shown in Table 2, the insertion of a special rectal tube reduces the occurrence of leaks by approximately 3.16 times. The 95% confidence interval for the relative risk and the test of independence confirm that this measure has a statistically significant effect on the occurrence of leaks. Another treatment method showing a statistically significant association with leak occurrence is the use of intraoperative fluorescence imaging (ICG), which reduces the occurrence of leaks by 2.11 times. For the other treatment methods studied, no statistically significant effect on leak occurrence was demonstrated, as shown in Table 2.
From Table 3 it is evident that the patient’s medical history most significantly influencing leak occurrence is diabetes mellitus. The presence of diabetes increases the occurrence of leaks by 2.16 times, and the 95% confidence interval for the relative risk, along with the test of independence, confirms that this condition has a statistically significant effect on leak occurrence. Another factor from the patient’s medical history with a statistically significant association with leak occurrence is smoking. Smokers have a 2.31 times higher occurrence of leaks compared to non-smokers. Among smokers and patients with diabetes, leaks occur in approximately 25% of cases. Elevated blood pressure, ASA classification, and corticosteroid use also show notable effects in some patients, as indicated by the relative risk intervals in Table 3, but the influence of these variables on leak occurrence is not statistically significant. For other categorical variables in the patient’s medical history, no statistically significant association with leak occurrence was demonstrated.
For quantitative variables, the description includes the median along with the interquartile range (lower quartile–upper quartile), the point and 95% interval estimate of the difference in medians, and the corresponding Mann-Whitney test, which allows us to determine whether the influence of a given variable is statistically significant.
The description of the quantitative variables related to the patient’s medical history, depending on the occurrence of leaks, the point and 95% interval estimates of median differences (median for patients with a leak—median for patients without a leak), and the corresponding results of the Mann-Whitney test can be found in Table 4.
A statistically significant difference in C-reactive protein (CRP) median levels between patients with and without a leak is observed because a leak represents a type of inflammation, and CRP is a well-established inflammatory marker. As Sproston and Ashworth highlight in Role of C-reactive protein at sites of inflammation and infection64, CRP’s primary function is its rapid increase in response to inflammatory stimuli. From a medical perspective, CRP should therefore not be considered among potential risk factors that could predict the occurrence of a leak beforehand; instead, it is a consequence marker, reflecting the body’s inflammatory response after a leak has developed.
The timing of the C-reactive protein (CRP) measurement is crucial for its diagnostic value. For none of the other continuous variables was a statistically significant association with leak occurrence observed, see Table 4.
The final predictive model includes NoCoil, ACSP, DM, and Smoking. In clinical practice, when anastomotic leak is suspected, multiple treatment methods, particularly NoCoil and ICG, are often applied together, leading to overlapping effects that reduce ICG’s independent predictive value in the presence of other variables (Table 6). To optimize the model, Akaike’s Information Criterion (AIC) was applied for feature reduction, resulting in model S2 (Table 6), which excluded ICG to improve the AIC score. ACSP, despite its marginal individual significance (\(p=0.074\)), was retained for its more stable and independent contribution to the model, making it a preferable choice over ICG.
As shown in Table 5, these variables demonstrate strong associations with anastomotic leak (\(\chi ^2\) test).
The figure clearly illustrates the protective effect of NoCoil usage, where patients who received the special rectal tube had anastomotic leak occurrence in only 5% of cases compared to 17% in patients without NoCoil. Similarly, the figure demonstrates the beneficial impact of intraoperative fluorescence imaging (ICG), with leak rates of 9% in the ICG group versus 19% in patients who did not receive this intervention.
Regarding patient risk factors, the figure highlights that diabetes mellitus substantially increases leak risk, with 25% of diabetic patients experiencing anastomotic leak compared to only 12% of non-diabetic patients. The smoking status shows an even more pronounced effect, with smokers having a 26% leak occurrence rate versus 11% in non-smokers. The figure also shows that while ACSP (Acute Care Surgery Program) appears to have a protective trend with 8% leak occurrence compared to 17% without ACSP, this difference did not reach statistical significance (\(p=0.074\)).
These visual comparisons in Fig. 2 effectively demonstrate the substantial clinical impact of both modifiable factors (smoking cessation, NoCoil usage, ICG implementation) and non-modifiable risk factors (diabetes mellitus) on anastomotic leak outcomes, supporting the statistical findings presented in the accompanying tables.

Risk factors of anastomotic leak. To align with standard odds ratio calculations, the category representing the primary risk factor is positioned in the first column. Consequently, ’Yes’ precedes ’No’ for patient comorbidities (DM, smoking), whereas ’No’ precedes ’Yes’ for the application of surgical interventions (ACSP, NoCoil).
Multivariate logistic regression models
Building on the initial statistical analysis (Sect. “Statistical analysis of patient data”), which identified significant predictors of anastomotic leak such as NoCoil, ACSP, DM, and Smoking, we now construct multivariate logistic regression models to account for inter-variable relationships. To enhance model interpretability and reduce overfitting, we performed feature reduction from the initial set of 15 variables to focus on the most impactful predictors of anastomotic leak.
In the logistic regression models presented in Table 6, the p-values for each predictor are derived from the Wald test, which evaluates the null hypothesis that a regression coefficient (\(\beta\)) is zero, indicating no effect on the log-odds of anastomotic leak. The test statistic uses the estimated coefficient and its standard error, with low p-values (e.g., \(p < 0.05\)) indicating significant predictors.
The comprehensive model (S1) includes all 15 explanatory variables. Unlike individual models, S1 captures interactions between variables, providing a more holistic view of their combined effects on anastomotic leak. To address non-significant variables, we applied Akaike’s Information Criterion (AIC)65 for feature reduction, resulting in model S2. This model retains DM, Smoking, NoCoil, and ACSP, which were significant or near-significant in individual analyses. ICG, initially significant in univariate analysis, was excluded due to strong correlations with NoCoil, which reduces its independent predictive power.
Further reduction using the Bayesian Information Criterion (BIC)66, which penalizes model complexity more stringently, yields model S3. This model excludes ACSP, retaining DM, Smoking, and NoCoil. The significance of reduced models S2 and S3 was evaluated using likelihood ratio tests (\(\chi ^2\) test). Both S2 and S3 are significantly different from the null model (\(p < 0.001\) and \(p = 0.001\), respectively) but not significantly different from the comprehensive model S1 (\(p = 0.879\) and \(p = 0.551\), respectively), indicating that they retain full predictive power despite utilizing fewer variables.
Model S4 was constructed using only the variables that were strictly significant at \(p < 0.05\) from individual analyses (DM, Smoking, NoCoil, ICG). However, NoCoil and ICG lose significance in S4, likely due to their correlated use in clinical practice, where multiple treatment methods are concurrently applied when anastomotic leak is suspected.
This step-wise feature reduction mitigates overfitting, enhances interpretability, and focuses on key predictors (DM, Smoking, NoCoil, and potentially ACSP) that drive anastomotic leak risk. By evaluating AIC and BIC criteria alongside pseudo-\(R^2\) fit metrics (Table 6), we systematically identified parsimonious models that maintain high predictive power and account for inter-variable relationships which individual univariate models failed to capture. A comprehensive evaluation of the classification performance (e.g., Sensitivity, Specificity, AUC) for these refined classical models is presented alongside the Quantum Neural Network benchmarks in Sect. “Comparative evaluation against classical machinelearning models”.
Simulating quantum neural networks with noise
To simulate quantum computing behavior as realistically as possible, we implemented a comprehensive noise model that closely approximates the characteristics of real quantum hardware. Our simulation framework utilizes Qiskit’s AerSimulator with a custom noise model that incorporates several key aspects of quantum decoherence and gate errors, providing a realistic testbed for evaluating quantum neural network performance under practical conditions.
The noise model implementation focuses on depolarizing errors, which are among the most significant sources of noise in current quantum hardware. This choice was deliberate as depolarizing noise represents a key paradigm in quantum error modeling that approximates the combined effects of various physical error mechanisms. In actual quantum computers, errors arise from multiple sources including thermal fluctuations, electromagnetic interference, and imperfect control pulses. These varied sources manifest as a combination of bit-flip (X), phase-flip (Z), and bit-phase-flip (Y) errors, which is precisely what the depolarizing channel models.
We selected a gate error probability of \(p_{gate} = 0.05\) based on reported error rates from IBM’s Manila quantum processor and similar NISQ devices, where single-qubit gate fidelities typically range from 99.5% to 99.9%, corresponding to error rates of 0.001 to 0.05. Our choice represents a conservative upper bound that accounts for the performance degradation observed in quantum processors under extended operation. This value also aligns with published benchmarks from quantum hardware manufacturers and recent literature on quantum error characterization67,68.
We modeled these errors using Kraus operators, which provide a complete description of quantum operations including noise effects. The noise model includes single-qubit gate errors with a probability \(p_{gate} = 0.05\), distributed equally among X, Y, and Z errors. The quantum channel effects are represented by Kraus operators with the identity operation (I) occurring with probability \(1 – p_{gate}\), while Pauli X, Y, and Z operations each occur with probability \(p_{gate}/3\). This equal distribution of error types reflects the equiprobable nature of different error mechanisms in depolarizing channels, which is consistent with the quantum information theory principle that noise in quantum systems tends toward maximum entropy in the absence of specific environmental biases. These error channels were applied to all single-qubit gates across all qubits in the system, ensuring comprehensive noise modeling throughout the quantum neural network.
The simulation was configured to use 1024 shots per circuit execution, providing a balance between statistical significance and computational efficiency. This shot count is comparable to typical experimental runs on actual quantum hardware, where 1000-2000 shots are commonly used to overcome the probabilistic nature of quantum measurements while respecting hardware time limitations and queue constraints. Circuit execution was managed through a custom NoiseSimulator class that handles the integration of the noise model with the quantum circuit execution pipeline.
Data encoding and feature mapping
For encoding classical data into quantum states, we employed the ZZFeatureMap, which is particularly well-suited for machine learning tasks due to its ability to create non-linear feature spaces. The ZZFeatureMap implements a second-order feature map that encodes classical data into quantum states through a series of single-qubit rotations and two-qubit ZZ operations, enabling the quantum neural network to process classical information in a quantum computational framework.
The encoding process begins with an initial rotation layer where each qubit i receives a rotation \(R_x(x[i])\) based on the input feature x[i]. This is followed by an entangling layer that applies ZZ operations between pairs of qubits, creating quantum correlations that encode feature interactions. A second rotation layer applies another set of single-qubit rotations, and this process can be repeated for the specified number of repetitions to increase the encoding depth.
Mathematically, the ZZFeatureMap implements the unitary transformation
$$\begin{aligned} U(\textbf{x}) = \exp \left( i \sum _{i} x_i Z_i\right) \exp \left( i \sum _{i
(1)
where \(x_i\) represents the i-th feature of the input data, \(Z_i\) denotes the Pauli Z operator on qubit i, and the second term creates entanglement between qubits based on pairwise products of features. This formulation allows the quantum circuit to capture both linear and quadratic feature combinations, potentially revealing hidden patterns in the data that might not be accessible through classical linear transformations.
The feature mapping circuit for 4 features with single repetition exhibits a depth of 17 with a total of 26 individual quantum gates, comprising 12 CNOT gates for entanglement generation, 10 parameterized phase gates for feature encoding, and 4 Hadamard gates for superposition initialization. This gate composition reflects the circuit’s emphasis on creating quantum correlations through the CNOT operations while encoding classical feature information through the parameterized phase rotations. The relatively moderate depth of 17 time steps ensures that the feature encoding process remains feasible on near-term quantum devices while still providing sufficient complexity to create meaningful quantum feature spaces for the 4-dimensional input data. Circuit depth represents a critical performance metric that directly impacts practical implementation, as it refers to the number of sequential time steps required for execution, with lower depth generally implying shorter execution time and reduced exposure to decoherence effects that can degrade quantum states over time.
In our implementation, we configured the ZZFeatureMap with 4 feature dimensions and a single repetition of the encoding circuit. This configuration maintains the dimensionality of the input space while creating non-linear feature combinations through quantum operations. The quantum circuit representing the ZZFeatureMap is shown in Fig. 3, which illustrates how Hadamard gates initialize superposition, followed by entangling CNOT gates and parameterized phase gates \(P(2.0\phi (x_i, x_j))\) to encode feature interactions. This combination enables quantum interference, where correlations between input data are mapped into the entangled quantum state, providing the foundation for the subsequent variational quantum processing.

The ZZFeatureMap applies Hadamard gates to initialize superposition, followed by entangling CNOT gates and parameterized phase gates \(P(2.0\phi (x_i, x_j))\) to encode feature interactions. This combination enables quantum interference, where correlations between input data are mapped into the entangled quantum state.
For instance, Havlíček et al.14 demonstrated the potential of quantum-enhanced feature spaces, prominently featuring the ZZFeatureMap, to make classically challenging datasets amenable to linear classification. Furthermore, its empirical effectiveness has been observed in various studies utilizing quantum kernel methods and Variational Quantum Classifiers69.
Variational quantum circuit design
Following the data encoding stage, the quantum neural network employs variational ansatze to process the encoded information through parameterized quantum circuits. The selection of appropriate ansatze involves balancing expressive power with computational efficiency, as more complex circuits can represent richer quantum states but require increased computational resources and may be more susceptible to noise effects. We investigated two prominent ansatze that offer different trade-offs between these competing requirements: the RealAmplitudes ansatz and the EfficientSU2 ansatz.
The RealAmplitudes ansatz represents a well-established choice for variational quantum classifiers due to its simplicity and computational efficiency. This ansatz utilizes a layered structure consisting of alternating single-qubit rotations (\(R_y\) gates) and multi-qubit entangling gates (typically CNOT gates), as illustrated in Fig. 4. The layered architecture allows for systematic construction of expressive quantum states while maintaining a relatively shallow circuit depth, which is crucial for maintaining coherence in noisy quantum environments.
The RealAmplitudes ansatz with 4 qubits and 3 repetitions demonstrates favorable circuit characteristics with a depth of 11 and a total of 25 quantum gates, reflecting its design philosophy of computational efficiency while maintaining expressive capability. The gate composition emphasizes rotation operations for parameterization while utilizing entangling gates judiciously to create necessary quantum correlations. This relatively shallow depth of 11 time steps, achieved through the efficient layering of the 3 repetitions, minimizes the exposure to decoherence effects, making it particularly suitable for near-term quantum implementations where coherence times are limited. When combined with the ZZFeatureMap, the complete RealAmplitudes quantum neural network achieves a total circuit depth of 28 with 51 gates, representing an efficient balance between expressiveness and practical implementability on current quantum hardware.
A defining characteristic of the RealAmplitudes ansatz is its generation of quantum states with only RealAmplitudes, which simplifies the interpretation and analysis of the circuit’s output since all basis state probabilities are represented by real numbers. This property also reduces the parameter space that must be explored during optimization, potentially leading to more efficient training procedures. Additionally, the RealAmplitudes ansatz requires a relatively low number of gates compared to more intricate ansatze, translating to lower computational costs for circuit implementation and reduced susceptibility to accumulated gate errors in noisy environments.
However, the simplicity that makes the RealAmplitudes ansatz computationally attractive also imposes limitations on its expressive capabilities. Compared to more complex ansatze, it may have reduced ability to represent highly intricate quantum states, which could potentially limit its performance for tasks demanding the most sophisticated quantum computations. Furthermore, the restriction to RealAmplitudes may prevent the circuit from fully exploiting quantum interference effects that require complex phases.

Quantum circuit diagram of the RealAmplitudes ansatz, featuring a layered structure with alternating single-qubit \(R_y\) rotations and multi-qubit entangling gates (e.g., CNOT). This ansatz generates quantum states with RealAmplitudes, simplifying interpretation while maintaining expressiveness for complex data. Its gate efficiency reduces computational costs, making it a practical choice for variational quantum circuits.
In contrast, the EfficientSU2 ansatz offers enhanced flexibility through a richer parameterization scheme. This ansatz retains the beneficial layered structure but utilizes single-qubit rotations around two axes (typically \(R_x\) and \(R_y\)) followed by entangling gates, as shown in Fig. 5. The additional rotation axis provides access to a broader range of single-qubit unitaries, enabling the circuit to explore a more extensive portion of the quantum state space and potentially capture more complex data patterns.
The EfficientSU2 ansatz with 4 qubits and 3 repetitions exhibits increased circuit complexity with a depth of 15 and a total of 41 quantum gates, reflecting its enhanced expressiveness through additional parameterized rotations across multiple axes. The gate distribution includes rotations around both x and y axes within each repetition layer, providing greater flexibility in quantum state preparation and potentially enabling more sophisticated pattern recognition capabilities. However, this increased depth of 15 time steps compared to the RealAmplitudes 11 steps represents a trade-off between expressiveness and susceptibility to noise, requiring careful consideration of the coherence properties of the target quantum hardware. The complete EfficientSU2-based quantum neural network, when combined with the ZZFeatureMap, results in a total circuit depth of 32 with 67 gates, demonstrating the computational overhead associated with enhanced quantum expressiveness.
The increased expressive power of the EfficientSU2 ansatz stems from its ability to generate quantum states with complex amplitudes and phases, allowing for more sophisticated quantum interference patterns. This enhanced expressiveness can translate to superior performance for certain classification tasks, particularly those involving complex, non-linearly separable data structures. The additional degrees of freedom provided by the dual-axis rotations enable the ansatz to adapt more flexibly to diverse data characteristics during the optimization process.
However, this enhanced capability comes with computational trade-offs. The EfficientSU2 ansatz typically requires more gates than the RealAmplitudes ansatz, leading to increased circuit depth and higher computational burden for both circuit implementation and optimization. The larger parameter space also presents optimization challenges, as the increased dimensionality can lead to more complex loss landscapes with additional local minima, potentially making the training process more difficult and requiring more sophisticated optimization strategies.

Quantum circuit diagram of the EfficientSU2 ansatz used in the quantum neural networks. The circuit features a layered structure with parametrized single-qubit rotations around two axes (typically \(R_x\) and \(R_y\)), followed by entangling gates to create correlations between qubits.
The choice between these ansatze ultimately depends on the specific requirements of the machine learning task, the available computational resources, and the noise characteristics of the target quantum hardware. In our comparative study, both ansatze were evaluated under identical noisy conditions to assess their relative performance and robustness, providing insights into the practical trade-offs between circuit complexity and classification accuracy in realistic quantum computing environments.
Variational parameters optimization
To optimize the parameters of our quantum neural networks, we employed a diverse set of optimization algorithms, each offering distinct advantages for navigating the complex parameter landscapes inherent in variational quantum circuits. The selection encompasses both gradient-based and gradient-free methods, providing robustness against the challenges posed by noisy quantum environments and barren plateaus (Table 7).
BFGS is a quasi-Newton optimization method that approximates the inverse Hessian matrix using gradient information to achieve rapid convergence for smooth objective functions70. In quantum circuit optimization, BFGS can effectively navigate parameter spaces when gradients are accessible, though its performance may degrade in the presence of sampling noise and measurement uncertainties typical in quantum hardware.
CMA-ES represents a derivative-free evolutionary strategy that maintains a population of candidate solutions while adapting a multivariate normal distribution to guide the search process71. This metaheuristic approach proves particularly valuable for quantum optimization as it naturally handles the non-convex, multimodal landscapes often encountered in variational circuits and remains robust to noise inherent in quantum measurements72,73,74.
COBYLA employs a simplex-based approach to construct linear approximations of the objective function, making it well-suited for noisy optimization environments75. Its derivative-free nature allows it to handle the stochastic fluctuations common in quantum circuit evaluation, though convergence may be slower compared to gradient-based methods in noiseless scenarios.
SLSQP combines sequential quadratic programming with constraint handling capabilities, constructing quadratic approximations to iteratively refine solutions76. While effective for smooth, differentiable problems, its reliance on gradient information can be challenging in quantum settings where parameter shift rules or finite differences must be employed for gradient estimation.
SPSA offers a highly efficient gradient-free approach that estimates gradients using only two function evaluations per iteration, regardless of parameter dimensionality77. This efficiency makes it particularly attractive for quantum optimization where circuit evaluations are computationally expensive, and its inherent robustness to noise aligns well with the stochastic nature of quantum measurements and decoherence effects.
The optimization algorithms considered have the following hyperparameters and initialization settings, assuming \(m\) parameters where applicable: CMA-ES uses an initial standard deviation \(\sigma _0 = 0.15\), a population size of \(\lceil 4 + 3 \log (m) \rceil\), a parent fraction \(\mu = 0.5\), a mean update factor \(c_{\text {mean}} = 1.0\), and a damping factor of 1.0; SPSA is configured with a maximum of 75 iterations , an allowed increase of \(10^{-3}\), blocking enabled, and a termination checker with \(N=10\); BFGS, specifically L-BFGS-B, is initialized with a maximum of 75 iterations and a function tolerance of \(10^{-4}\); SLSQP is set with a maximum of 75 iterations and a function tolerance of \(10^{-4}\); COBYLA is configured with a maximum of 75 iterations.
Predictive modeling approaches
Our study compares classical and quantum-enhanced approaches to predictive modeling of anastomotic leak:
-
1.
Classical methods: We employed a diverse set of classical machine learning models, including logistic regression (LR), linear discriminant analysis (LDA), Support Vector Machines (SVM), Multi-Layer Perceptron (MLP)78, and Nearest Neighbors (NN). Additionally, we utilized ensemble methods such as Gradient Boosting Machines (GBM)79 and AdaBoost80 to improve predictive performance. The implementation of these classical models was carried out using the scipy81 module in Python. The effectiveness of these models was evaluated using Receiver Operating Characteristic (ROC) curves, with a primary focus on sensitivity (true positive rate) to prioritize identification of patients at high risk of anastomotic leak.
-
2.
Quantum neural networks: A novel quantum-enhanced approach using Variational Quantum Circuits82 is applied to the dataset. These circuits leverage the principles of quantum mechanics to explore high-dimensional feature spaces, potentially improving the predictive power for imbalanced datasets. We used the qiskit library83 for all the work with quantum circuits.
Model performance is evaluated using the following metrics:
-
ROC curves and AUC: The Area Under the Curve (AUC) of the Receiver Operating Characteristic (ROC) curve measures a model’s ability to discriminate between patients with and without the complication. AUC values closer to 1 indicate better performance, as the model correctly distinguishes between positive and negative cases more often.
-
Sensitivity and specificity: Sensitivity (true positive rate) reflects the model’s ability to correctly identify patients who experience the complication, ensuring high-risk individuals are not missed. Specificity (true negative rate) measures how well the model correctly identifies those who do not develop the complication, reducing false positives.
-
Predictive power, calibration, and classification accuracy: We assess overall model performance using various statistical measures:
-
Efron’s R2, McKelvey & Zavoina R2, and Count R2 evaluate how well the model explains variance in the outcome.
-
Brier Score and Log Loss assess model calibration, measuring how well predicted probabilities align with actual outcomes.
-
F1 Score balances precision and recall, particularly relevant for imbalanced datasets.
-
Additionally, Positive Predictive Value (PPV) and Negative Predictive Value (NPV) provide practical insights into prediction reliability. PPV represents the probability that a positive prediction corresponds to an actual occurrence of the complication, while NPV indicates the probability that a negative prediction correctly identifies a complication-free patient. These metrics are particularly useful in clinical decision-making, where understanding the likelihood of correct predictions is crucial.
To rigorously evaluate and compare the performance of our predictive models, we established a comprehensive evaluation framework. This framework encompasses cross-validation to assess robustness, ROC curve analysis for threshold optimization, and a comparative analysis of classification metrics at fixed sensitivity levels. These methodologies are designed to provide a multifaceted understanding of each model’s strengths and limitations in the context of rare post-surgical complication prediction.
To ensure the reliability and generalizability of our findings, we employed cross-validation (CV). This technique is crucial for evaluating how well models generalize to unseen data and for mitigating the risk of overfitting. By systematically training and testing models on different partitions of the dataset, cross-validation provides a more robust estimate of predictive performance than a single train-test split.
Feature importance analysis for quantum neural network
Interpreting the predictive mechanisms of machine learning models is paramount for their application in critical domains such as clinical risk assessment. While classical linear models like logistic regression offer straightforward interpretability through their model coefficients, the complex, high-dimensional nature of QNNs presents a significant challenge. In our work, the association between clinical risk factors DM, Smoking, ACSP, and NoCoil and post-surgical anastomotic leak was modeled using a QNN in Qiskit. This QNN was constructed with a ZZFeatureMap to encode the four-dimensional feature vector into an entangled quantum state, and an EfficientSU2 ansatz to create a trainable parameterized quantum circuit. Optimization was performed via a CMA-ES.
Unlike a logistic regression model, where the feature importance is directly quantified by the coefficients \(\beta _i\) in the equation
$$\begin{aligned} \ln \left( \frac{p}{1-p}\right) = \beta _0 + \sum _i \beta _i x_i, \end{aligned}$$
(2)
the trained parameters of a QNN lack a direct, human-interpretable meaning. Consequently, to understand our model’s decision-making process, we explored two experimental, perturbation-based feature importance techniques. These methods aim to approximate a feature’s influence by observing the model’s behavior when its inputs are systematically altered.
Our first experimental approach was a permutation-based analysis, a model-agnostic technique that assesses the global impact of a feature on the model’s overall performance. This method first establishes a baseline predictive accuracy, measured by the AUC on the test set. Then, for each feature, its values are randomly shuffled across all samples, effectively breaking any learned relationship between that feature and the outcome. The model’s AUC is re-evaluated on this perturbed data, a process repeated one hundred times for statistical robustness. The average decrease in AUC is then taken as the importance score for that feature, with a larger drop indicating a greater reliance of the model on that variable. While this method captures complex, non-linear interactions as reflected in the final performance metric, its stochastic nature can lead to variance in the results, and the shuffling process may create unrealistic data instances that disrupt the very feature correlations the ZZFeatureMap is designed to learn.
To address these limitations, we implemented a second experimental technique: a gradient-based importance analysis. This method provides a more direct and stable probe of the model’s sensitivity to each feature. Instead of the large-scale disruption of shuffling, it applies a minute, controlled perturbation (\(\epsilon\)) to a single feature at a time and measures the immediate impact on the model’s output probability. The importance is quantified as the average absolute change in the predicted probability across the entire test set. This value serves as a numerical approximation of the gradient of the model’s output with respect to its input, effectively measuring how much the model’s prediction changes for a small change in a given feature. This approach is deterministic and better preserves the intricate, learned correlations between features, offering a more nuanced view of a feature’s local influence on the classification decision.
In contrasting these approaches, the permutation method provides a holistic score of a feature’s contribution to the final AUC, whereas the gradient method reveals the model’s internal sensitivity to variations in the feature’s value. Both quantum-inspired techniques stand apart from logistic regression by their ability to account for the non-linear relationships and entanglement-based correlations captured by the QNN. While the classical approach provides a clear, linear, but potentially incomplete picture, our experimental methods represent a necessary step toward unpacking the “black box” of quantum classifiers, allowing us to build confidence in their predictions and gain deeper insights from the complex patterns they uncover. The development of such interpretability tools is a vital research direction for the advancement and practical deployment of quantum machine learning in scientific discovery and beyond.


