Hey everyone,
I want to walk through what is, in my opinion, an important structural shift happening in AI right now.
For years, the way we value AI model providers is via benchmarks based on the raw performance of these models. The narrative has been “whoever has the best benchmark model wins”
I think this framing is increasingly becoming wrong. The real moat that the frontier labs are building right now is not the model. It is the harness around the model and the cost of serving the model. In this article, I will focus on the harness. And once you understand what a harness is, you start to see why Anthropic’s enterprise revenue keeps compounding even when its raw benchmark scores are not always the best, and why the labs that own both the model and the harness are setting themselves up for the kind of platform lock-in that historically produced high gross margin businesses.
Let start.
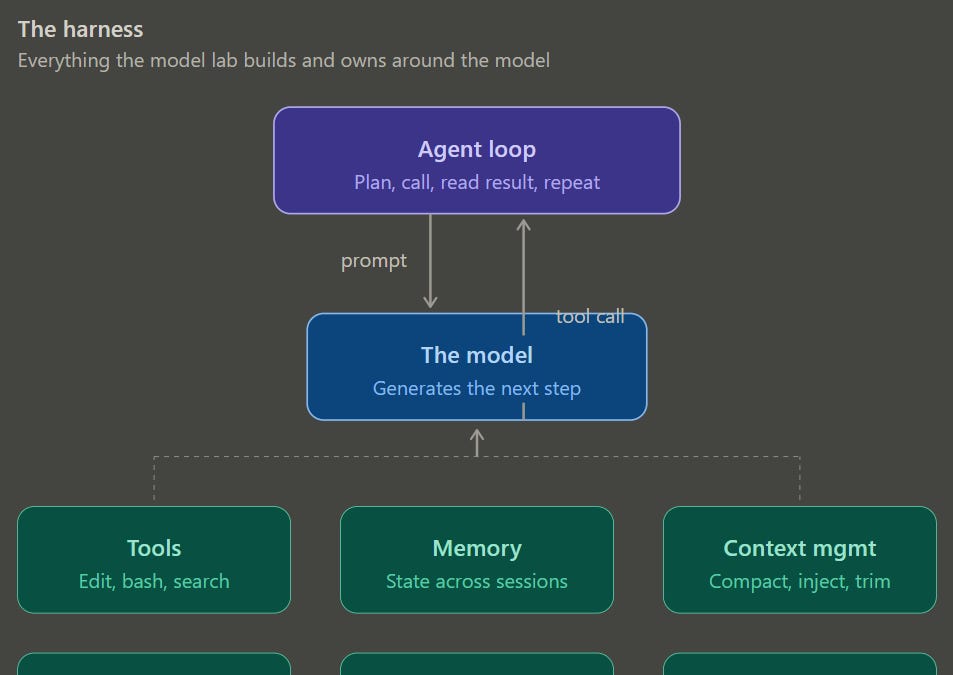
What is a harness?
You can picture a harness as this entire system that wraps the model and turns it from a text generator into something that can do real work. Tools, memory, system prompts, permission policies, sandboxes, subagent dispatch, context management, the agent loop itself.

The cleanest one-line definition comes from LangChain: “Agent = Model + Harness. If you’re not the model, you’re the harness.”
A useful analogy is to think of a model as a very smart contractor who can only communicate through notes. A harness is the tool setup — the computer, the phone, the filing cabinet, the rulebook, the permissioning — that lets the contractor actually do the job.
Mechanically, even the most sophisticated harnesses are just a while loop. The model emits a tool call, the harness executes it, the result gets fed back, the loop continues. Anthropic literally calls their runtime a “dumb loop” where all the intelligence lives in the model. But the complexity is in everything that loop manages: which tools exist, what their schemas look like, what gets injected into context on each turn, what gets compacted away, what gets remembered across sessions, how subagents are spawned, how errors are recovered, when the model is allowed to take a destructive action without asking. None of that is “the model.” All of it determines whether your agent actually finishes the task or burns 100,000 tokens going in circles. This has effects both on the quality of the output and on costs.
The empirical evidence: the harness is moving benchmarks even more than the model is in some cases
We now have some hard data showing that the harness can move model performance by more than a full model generation upgrade.
Three independent data points from the last six months, all converging on the same conclusion:
Data point 1 – LangChain on Terminal-Bench 2.0. Terminal-Bench 2.0 is now the standard benchmark for evaluating coding agents on real terminal tasks (89 tasks across machine learning, debugging, biology, infrastructure). LangChain kept the model fixed (GPT-5.2-Codex) and only changed the harness. Score went from 52.8% to 66.5%. That moved them from outside the Top 30 to Top 5 on the leaderboard. Same model, same weights, different scaffolding. A 13.7 percentage point jump from harness alone.
Data point 2 – Cursor on Terminal-Bench 2.0. Cursor’s research team published a piece on April 30, 2026 reporting that they took their own coding agent from Top 30 to Top 5 by only changing the harness. Same conclusion, different team, different harness. A 25-position jump on a public leaderboard, attributable to scaffolding alone.
Data point 3 – Claude Opus 4.6, same weights, very different harnesses. This is the cleanest one. Look at the Terminal-Bench 2.0 leaderboard from late April 2026:

Same model. Different harnesses. A 4.5 percentage point spread between ForgeCode and Capy, on a benchmark where teams are fighting for tenths of a point.
The interesting observation is that the labs that trained the models do not always have the best harness for their own models, which I believe shows just how much untapped potential there still is in this area. ForgeCode is a third-party harness, and it lands three of the top six entries on Terminal-Bench 2.0 by routing across model families. LangChain summarized this as: “Opus 4.6 in Claude Code scores far below Opus 4.6 in other harnesses.” Anthropic’s flagship model in Anthropic’s flagship harness gets beaten by the same weights running in third-party scaffolding.
Now compare this to model generation upgrades. Going from Claude Opus 4.5 (80.9% on SWE-bench Verified) to Opus 4.7 in April 2026 took SWE-bench Verified from 80.8% to 87.6% — about a 6.8-point upgrade. The harness can move you 13.7 points on Terminal-Bench from scaffolding alone. The harness is moving the score by more than a model generation upgrade.
Don’t get me wrong, I am not trying to say that raw AI model performance doesn’t matter. The model floor is rising, and that floor matters a lot. The point is that on top of any given model, the harness is now the largest single performance variable in agent quality. Anyone shipping a coding agent in 2026 who picks the model first and the harness second is leaving a lot of performance and cost-effectiveness.
This section from an interview with a former high-ranking Meta employee is very interesting. It explains just how much more room there is for improvement around the harness, and that because raw model improvements are so fast right now, the resources are not yet focused on it enough:
»The biggest barrier, I would say it’s just the modeling evolution is so quick. We want to push the model architecture faster but we don’t really have the time to really do parameter tuning to find fast architecture for our data or for different use cases. Right now, it’s more like we have one safe home. That’s our goal at that time. We have the foundation model. The foundation model powers roughly four or five different orgs’ ranking models.
Although it’s a foundation model, it’s a Wikipedia, knows everything, but still, how to find an optimal maybe adapter or optimization, tuning for each of the five use cases that are under its cloud. I think that’s one of the biggest challenges. We have to chase our targets and there are some ways to hit a target a little bit easier than really going deep into understanding this model, what the model does and what’s the best parameter.«
Source: Former Meta employee found on AlphaSense
Why the harness forms a moat
It is important to understand that models are post-trained against a specific harness. They are not generic. Every modern frontier model was fine-tuned, with reinforcement learning, against a specific tool surface, a specific schema, a specific memory ritual, a specific citation format, a specific system prompt structure. The model’s instincts — what it reaches for when it needs to edit a file, what tag it wraps citations in, how it structures a plan, how it handles subagent dispatch — are baked into the weights during post-training. And they are baked in against one specific harness.
The clearest concrete example is the file-editing tool. From Cursor’s harness team:
“OpenAI’s models are trained to edit files using a patch-based format, while Anthropic’s models are trained on string replacement. Either model could use either tool, but giving it the unfamiliar one costs extra reasoning tokens and produces more mistakes. So in our harness, we provision each model with the tool format it had during training.”
Cursor is saying that the wrong tool format produces a measurable cost in reasoning tokens and an observable increase in error rate, recorded at scale across millions of agent turns. The model performs worse because the wire format it sees at runtime does not match the wire format it was trained on.
This is becoming a challenge for everyone trying to become an orchestration layer on top of AI model providers like Microsoft. I am not saying it is an impossible task, but you need to have different harnesses for each AI model you use. It also suggests that the products that these AI labs are offering are not just the model, but the model together with the custom harness, as the model and the harness were fused over months of post-training, and you cannot pull them apart without giving up performance. In the end, this might mean the moat becomes stronger for AI labs, as switching AI models becomes increasingly complex.
Why this is a co-evolution, not a one-time thing
The more powerful version of the moat argument is that the post-training and the harness feed back into each other on every model generation. This is what is starting to create compounding lock-in over time.
An example of this is Anthropic’s harness team ships a new primitive — say, a smarter subagent dispatch verb, or a new way to compact context, or a memory file convention. By month three, that primitive shows up in millions of real agent traces from Claude Code users. By month six, those traces are training data for the next model generation. By month twelve, the next model has the primitive baked into its instincts, and the harness can now lean on it as something the model does natively.
Anthropic puts it this way in their March engineering blog: “every component in a harness encodes an assumption about what the model can’t do on its own. Those assumptions go stale.” When a model upgrade kills an old assumption, that piece of scaffolding gets retired, freeing up the harness to push on the next ceiling.
A concrete example from Anthropic’s own work: when Claude Sonnet 4.5 was the frontier model, the agent had “context anxiety” — it would wrap up tasks prematurely as it approached what it thought was its context limit. The harness compensated by aggressively resetting context between sessions and using structured handoff artifacts to carry state across the boundary. When Opus 4.6 shipped, that behavior was largely gone in the model itself, so Anthropic dropped the entire context-reset machinery and ran continuous sessions over two hours. The harness shrank because the model swallowed a chunk of its work.
The matched pair is not static. It moves with each model generation. And the labs that own both sides of the pair are the only ones who can move it cleanly. A third-party harness builder is always reacting to a model release; the labs are designing the next model with the next harness in mind.
This is genuinely structural moat behavior. It looks a lot like the way Microsoft built lock-in through tightly coupling Windows + Office + Exchange in the 1990s and 2000s – each layer made the others stickier, and competing on any single layer in isolation got harder every year.
There is a counter-example worth knowing because it sharpens the moat argument. In December 2025, Vercel published an engineering post-mortem: their internal text-to-SQL agent had 16 specialized tools – schema lookup, query validation, error recovery, intent clarification, join-path finders, syntax validators. They deleted 80% of them and replaced everything with a single capability: execute arbitrary bash commands against a file system.
Results: success rate went from 80% to 100%. Speed improved 3.5x. Token usage dropped 37%. The worst-case run improved from 724 seconds, 100 steps, and 145,463 tokens (failing) to 141 seconds, 19 steps, 67,483 tokens (succeeding).
The lesson is more than just that fewer tools are better. It is that the right harness depends on the model’s current capabilities, and that gap shifts every model generation. When the model gets smart enough to use bash + grep + cat directly, your custom tool layer becomes overhead. GitHub’s Copilot team hit the same wall from the opposite direction: they cut Copilot’s tool count from 40+ to 13 core tools, and pre-expansion accuracy jumped from 19% to 72%.
This is exactly why owning both the model and the harness is so valuable. You can retire scaffolding as your model gets smarter, faster than anyone else can. A third party building on top of your model is always reacting to your release notes. You are designing both sides.
Where the harness wars are headed
A few things I am watching that I think will define the next 12-18 months of this space:
-
The harness becomes the product, not the model. This is already happening. Anthropic does not sell “Claude” anymore as the main enterprise product — they sell Claude Code, Cowork, the Claude Agent SDK, and Claude Managed Agents. OpenAI sells Codex CLI, the Agents SDK, and the Codex cloud agent. Google just announced that they are deprecating Gemini CLI entirely and replacing it with Antigravity CLI, which shares a unified server-side harness with their Antigravity desktop IDE. The model is the engine; the harness is the car. Customers buy the car.
-
“Harness-as-a-Service” (HaaS) is the next API layer. The Claude Agent SDK, the OpenAI Agents SDK, and Google’s new Antigravity SDK all point the same way: you do not get a model API anymore, you get a harness API — the loop, the tools, the context management, the hooks, the sandbox primitives, the memory layer, all out of the box. This is a bigger and stickier surface than “completions.”
-
These are important implications for the SaaS companies. The harness will absorb more of what is currently sold as SaaS. A managed harness with built-in code execution, browser control, file storage, memory, and orchestration is the runtime for AI-native software. That competes directly with a stack of SaaS tools previously bought separately: developer environments, browser automation, vector databases, observability layers, sandboxing services. Anthropic just shipped Claude Managed Agents, which puts the entire harness behind an API.
-
Harnesses will increasingly diverge by vertical. The highest-quality harnesses today are all coding harnesses, because the ROI is most obvious. The same primitives apply to legal, finance, healthcare, and support. Whoever builds the best vertical harness for a domain will own that domain’s spend, even if the underlying model is shared. The providers that specialize and build harnesses for specific verticals can overcome even AI model raw performance deficiencies because the harness is better. An example of this would be someone like Meta, specializing in shopping, social media, and the healthcare vertical.
The investment angle
This is where the moat argument actually matters for capital allocation in terms of sectors and for which public company this might be most important.


