The proliferation of paper mill papers in the scientific literature has prompted scientists to create new tools to identify fake publications.
○For the past two decades, the scientific literature has been flooded with low-quality research papers produced by commercial organizations known as paper mills. Questionable paper mill products are estimated to account for 2 to 46 percent of manuscripts submitted to scientific journals, and the proportion of questionable articles in biomedical research is estimated to reach nearly 6 percent by 2023.1, 2
Paper mills often rely on templates to produce manuscripts in bulk, resulting in scientific papers with common characteristics. These may include text or layout similarities, superficial descriptions of hypotheses or experimental designs, manipulated or reused digital images, misdescriptions of reagents, etc.3 These manuscript “recipes” may speed up production at paper mills, but they also serve as fingerprints for scientific integrity researchers to flag papers as potential products for paper mills.
In a study published earlier this year, BMJa team of scientists led by Queensland University of Technology statistician Adrian Barnett has developed a new machine learning tool to screen publications about cancer research and flag those that are likely to come from paper mills.4 They found that nearly 10 percent of the cancer research literature screened by the tool likely originated in paper mills. This rate exceeds the estimated prevalence of paper mill papers in biomedical research, indicating that cancer research is a prime target for these fraudulent companies.2
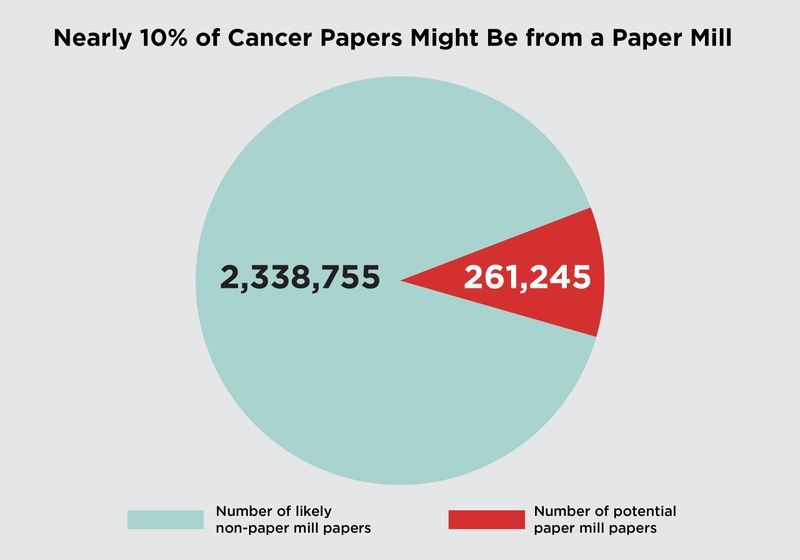
 and a green slice representing the number of cancer research papers unlikely to be from a paper mill (2,338,755) as determined by a machine learning-based screening tool.")
Of the 2.6 million cancer articles screened, almost 10 percent (261,245 publications) had text symbols in the abstract or title that suggested they may have been produced in a paper mill. Stomach cancer, bone cancer, liver cancer, esophageal cancer, and ovarian cancer were the cancer types with the most flagged papers.
Erin Lemieux
“We have few solutions and even fewer researchers trying to design them.[s] João Philippe Cardenuto, a postdoctoral researcher and digital forensics scientist at the University of Campinas in Brazil, who was not involved in the study, said:
To identify papers about cancer that appear to have originated from paper mills, Barnett and his colleagues developed a machine learning-based tool that identifies patterns in text and compares them to patterns of text present in retracted paper mill papers. Previous research suggested that text templates could be used to train machine learning models to identify paper mill products, but this approach had not been tested in the cancer research field.5 “Unfortunately, cancer has been a significant target for these types of papers,” Barnett explained. “Partly, it’s a privilege to work in the field of cancer. There are a lot of journals on cancer. Partly, basic science is a bit of a target for these paper mills, because it’s a little easier to fabricate data.”
The team focused their analysis on the paper’s abstract and title because these components are easy to access. They developed the model using papers tagged as paper mill origin in the Retraction Watch database and then validated the tool’s performance using an online list of problematic papers compiled by integrity investigators. In performance test runs, the machine learning tool correctly flagged problematic papers with about 90% accuracy.
The scientists then ran the screening tool against 2.6 million cancer research papers published between 1999 and 2024. Of the publications, 261,245 articles (almost 10% of the total literature corpus analyzed) showed textual similarity to retracted paper mill articles.
Barnett explained that although the proportion of papers reporting cancer appears high, it may be an underestimate of the true prevalence of paper mill products in this area, as these companies have been increasing their production over the years, a trend observed in this study. “We don’t actually know if it’s actually 10 percent. It could actually be more because we’re just detecting certain types of templates,” he said. “If the factory had other templates that were more sophisticated, we would have missed them.”
Potentially fake papers were most often associated with specific types of cancer, including stomach cancer (22%), bone cancer (21%), and liver cancer (20%). The researchers also found that the proportion of flagged articles in top-tier journals showed a continued increase, indicating that paper mills are not limited to low-impact journals and suggesting that impact factor may not be a reliable indicator of research quality.6
The machine learning screening tool also revealed that authors from Chinese institutions accounted for the majority (36 percent) of potential paper mill papers. This is a set of results that is consistent with previous data on the origins of these fraudulent papers.2 Despite the authors’ efforts to balance the training dataset by language, Cardenuto explained that the overpopulation of Chinese researchers could still bias the model, as the tool may learn patterns that Chinese authors frequently use in scientific papers, rather than features associated with fake publications.
Although the new screening tool was designed with scientific publishers in mind, Barnett hopes it will shine a spotlight on the problems in paper mills and raise further awareness among researchers. “Unfortunately, you have to take that into account when you read and review papers,” he says.


