Image by author
# introduction
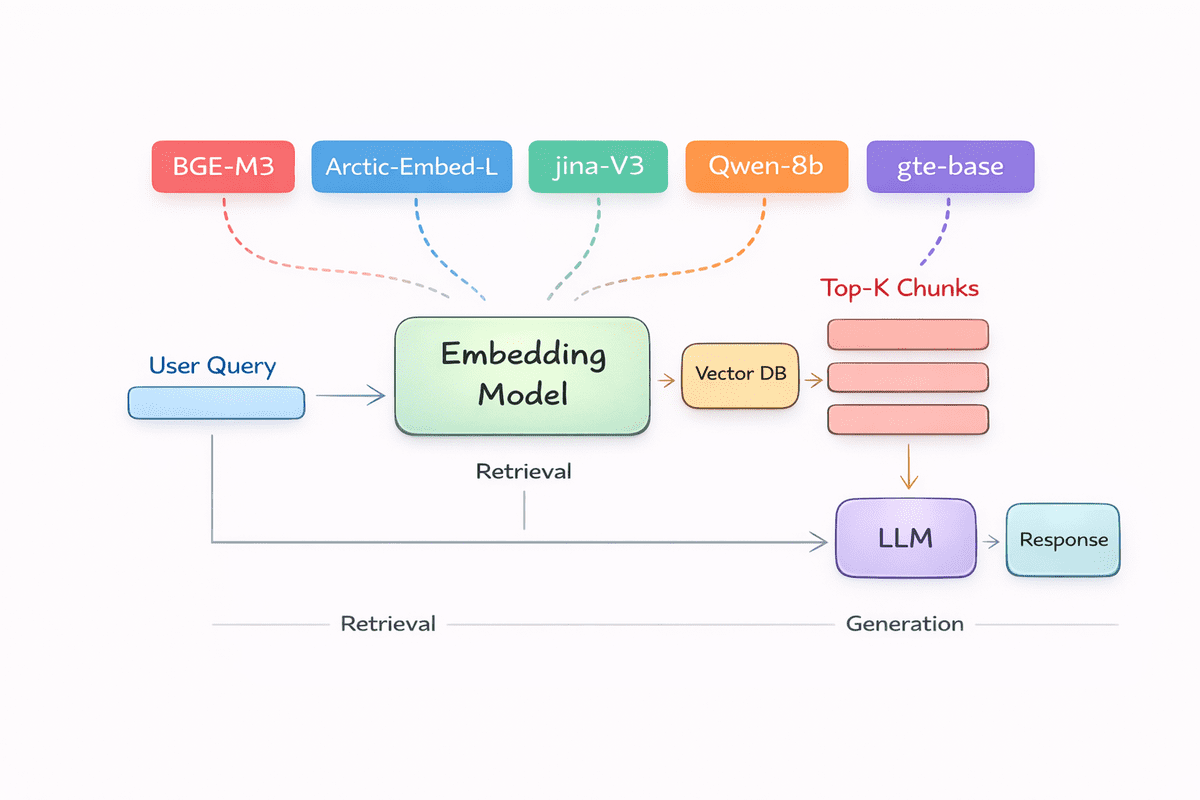
In the search augmentation generation (RAG) pipeline, embedded models are the foundation that makes search work. Before language models can answer questions, summarize documents, or make inferences about data, they need a way to understand and compare meanings. That’s exactly what embedding does.
In this article, we consider the top embedding models for both English-only and multilingual performance, ranked using search-focused metrics. These models are extremely popular and widely adopted in real-world systems, and consistently provide accurate and reliable search results across a wide range of RAG use cases.
Evaluation criteria:
- 60% performance: English search quality and multilingual search performance
- 30% download: Download the Hug Facial Feature Extraction Model as a Surrogate for Real-World Recruitment
- 10 percent practicality: Model size, embedding dimensions, and deployment feasibility
The final ranking favors embedded models that capture accuracy, are actively used by teams, and can be deployed without extreme infrastructure requirements.
# 1.BAAI bge-m3
BGE-M3 is an embedded model built for search-focused applications and RAG pipelines, with a focus on strong performance across English and multilingual tasks. It has been extensively evaluated in public benchmarks and widely used in real-world systems, making it a reliable choice for teams requiring accurate and consistent retrieval across a variety of data types and domains.
Main features:
- Integrated search: Combines dense, sparse, and multivector search capabilities in one model.
- Multilingual support: Supports over 100 languages with powerful multilingual performance.
- Handling long contexts: Processes long documents up to 8192 tokens.
- Hybrid search compatible: Provides token-level lexical weights along with dense embeddings for BM25-style hybrid search.
- production friendly: Balanced embedding sizes and integrated fine-tuning make large-scale deployments realistic.
# 2. Qwen3 Embed 8B
Qwen3-Embedding-8B A high-end embedding model in the Qwen3 family, built specifically for text embedding and ranking workloads used in RAG and search systems. It is designed to perform powerfully across search-intensive tasks such as document search, code search, clustering, and classification, and has been extensively rated on public leaderboards and ranked among the top models for multilingual search quality.
Main features:
- Highest search quality: As of June 5, 2025, it is ranked #1 on the MTEB Multilingual Leaderboard with a score of 70.58.
- Long context support: Handles up to 32K tokens in long search scenarios
- Flexible embedding size: Supports user-defined embedded dimensions from 32 to 4096
- recognize commands: Typically supports task-specific instructions that improve downstream performance.
- Multi-language and code support: Supports over 100 languages, including powerful cross-language and code search coverage
# 3. Snowflake Arctic Embedded L v2.0
Snowflake Arctic-Embed-L-v2.0 is a multilingual embedding model designed for high-quality search at enterprise scale. It is optimized to provide powerful multilingual and English search performance without the need for separate models, while maintaining efficient inference properties suitable for production systems. Released under the permissive Apache 2.0 license, Arctic-Embed-L-v2.0 is built for teams that require reliable, scalable retrieval across global datasets.
Main features:
- Multilingual support without compromise: Delivers powerful English and non-English search and outperforms many open source and proprietary models on benchmarks such as MTEB, MIRACL, and CLEF.
- efficient inference: Achieve fast and cost-effective inference using a compact non-embedded parameter footprint.
- Compression friendly: Supports matryoshka representation learning and quantization, reducing embeddings to a minimum of 128 bytes with minimal quality loss
- Drop-in compatible: Built on bge-m3-retromae and allows direct replacement of existing built-in pipelines
- Long context support: Handles inputs of up to 8192 tokens using RoPE-based context expansion
# 4. Jina Embedding V3
jina-embeddings-v3 is one of the most downloaded embedded models for Hugging Face text feature extraction, making it a popular choice for real-world search and RAG systems. It is a multilingual, multitasking, embedded model designed to support a wide range of NLP use cases, with a focus on flexibility and efficiency. Built on the Jina XLM-RoBERTa backbone and extended with task-specific LoRA adapters, developers can use a single model to generate embeddings optimized for a variety of search and semantic tasks.
Main features:
- Task-aware embedding: Use multiple LoRA adapters to generate task-specific embeddings for search, clustering, classification, and text matching.
- Multilingual support: Tailored to focus on 30 influential languages, including English, Arabic, Chinese, and Urdu, with support for over 100 languages
- Long context support: Process input sequences of up to 8192 tokens using rotary position embedding
- Flexible embedding size: Supports Matryoshka embedding with truncation from 32 dimensions up to 1024 dimensions
- production friendly: Widely adopted, easy to integrate with Transformers and SentenceTransformers, and supports efficient GPU inference.
# 5. GTE multilingual base
gte-multilingual base is a compact yet high-performance embedding model of the GTE family, designed for multilingual search and long-context text representation. It focuses on delivering strong search accuracy while keeping hardware and inference requirements low, making it ideal for production RAG systems that require speed, scalability, and multilingual support without relying on large decoder-only models.
Main features:
- Powerful multilingual search: Achieves state-of-the-art results in multilingual and cross-linguistic search benchmarks for similarly sized models
- efficient architecture: Uses encoder-specific transformer design for significantly faster inference and lower hardware requirements
- Long context support: Handles input of up to 8192 tokens for long document retrieval
- elastic embedding: Supports flexible output sizes and reduces storage costs while maintaining downstream performance
- Hybrid search support: Generate both dense embeddings and sparse token weights for dense, sparse, or hybrid search pipelines.
# Detailed comparison of embedded models
The table below provides a detailed comparison of the leading embedding models for RAG pipelines, focusing on context processing, embedding flexibility, retrieval capabilities, and what each model actually does best.
| model | Maximum context length | Embedding the output | Search function | Main strengths |
|---|---|---|---|---|
| BGE-M3 | 8,192 tokens | 1,024 dims | Dense, sparse, and multiple vector searches | Hybrid search unified in a single model |
| Qwen3-Embedding-8B | 32,000 tokens | 32 to 4,096 dimming (configurable) | High-density embedding with command-aware search | Highest retrieval accuracy for long and complex queries |
| Arctic-Embed-L-v2.0 | 8,192 tokens | 1,024 dimensions (MRL compressible) | dense search | Get high quality with strong compression support |
| jina-embeddings-v3 | 8,192 tokens | 32 to 1,024 dimes (matryoshka) | Task-specific dense retrieval via LoRA adapter | Flexible multitasking embedding with minimal overhead |
| gte-multilingual base | 8,192 tokens | 128 to 768 dimensions (stretchable) | Dense vs sparse search | Fast and efficient search with low hardware requirements |
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs about machine learning and data science technology. Avid holds a master’s degree in technology management and a bachelor’s degree in telecommunications engineering. His vision is to build AI products using graph neural networks for students suffering from mental illness.

