
A New York University professor used a voice AI agent to conduct an oral exam. The experiment cost $15 for 36 students and revealed gaps in both the students' knowledge and his own instruction.
The written assignments for the new “AI/ML Product Management” course looked “suspiciously good.” Panos Ipeirotis wrote in his blog that “a McKinsey memo that went through three edits” was a good thing, not a “strong student” good one. Professor Stern at New York University is known for his work on crowdsourcing and the integration of human and machine intelligence.
Mr. Ipeirotis and his co-instructor, Konstantinos Rizakosten, began belittling students during class. The results were “edifying,” Ipeirotis said. Many of those who submitted thoughtful work were unable to explain the fundamental decisions in their submissions after two follow-up questions. The gap between written performance and oral defense was too consistent to be blamed on nerves.
Ipeirotis says the old system of reliably measuring comprehension through take-home reports is “dead, gone” thanks to AI, proof that it was still needed. Students can now use AI to answer most traditional exam questions.
AI oral exam costs 42 cents per student
Oral exams require you to think in real time and defend your actual decisions, which is a logical nightmare for large classes. Inspired by research showing that AI consistently performs better than humans in job interviews, Ipeirotis and co-instructor Konstantinos Lizakos tried something new. It's a final exam conducted by a voice AI agent built on top of Eleven Labs' conversational AI.
The study consisted of two parts. First, the agent asked questions about the student's final project: goals, data, modeling decisions, evaluation, and failure modes. Next, we selected a case from the course and asked questions about the content covered.
Thirty-six students took the test over nine days, taking an average of 25 minutes per exam. Total cost: $15 – $8 for Claude as primary evaluator, $2 for Gemini, 30 cents for OpenAI, and about $5 for Eleven Labs. That's 42 cents per student.
For comparison: 36 students x 25 minutes x 2 human graders equals 30 hours of work. If a student assistant earns about $25 an hour, that's $750. In academia, the difference in cost often determines whether an oral exam is given, Ipeirotis said.
Early versions were intimidating and asked too many things at once
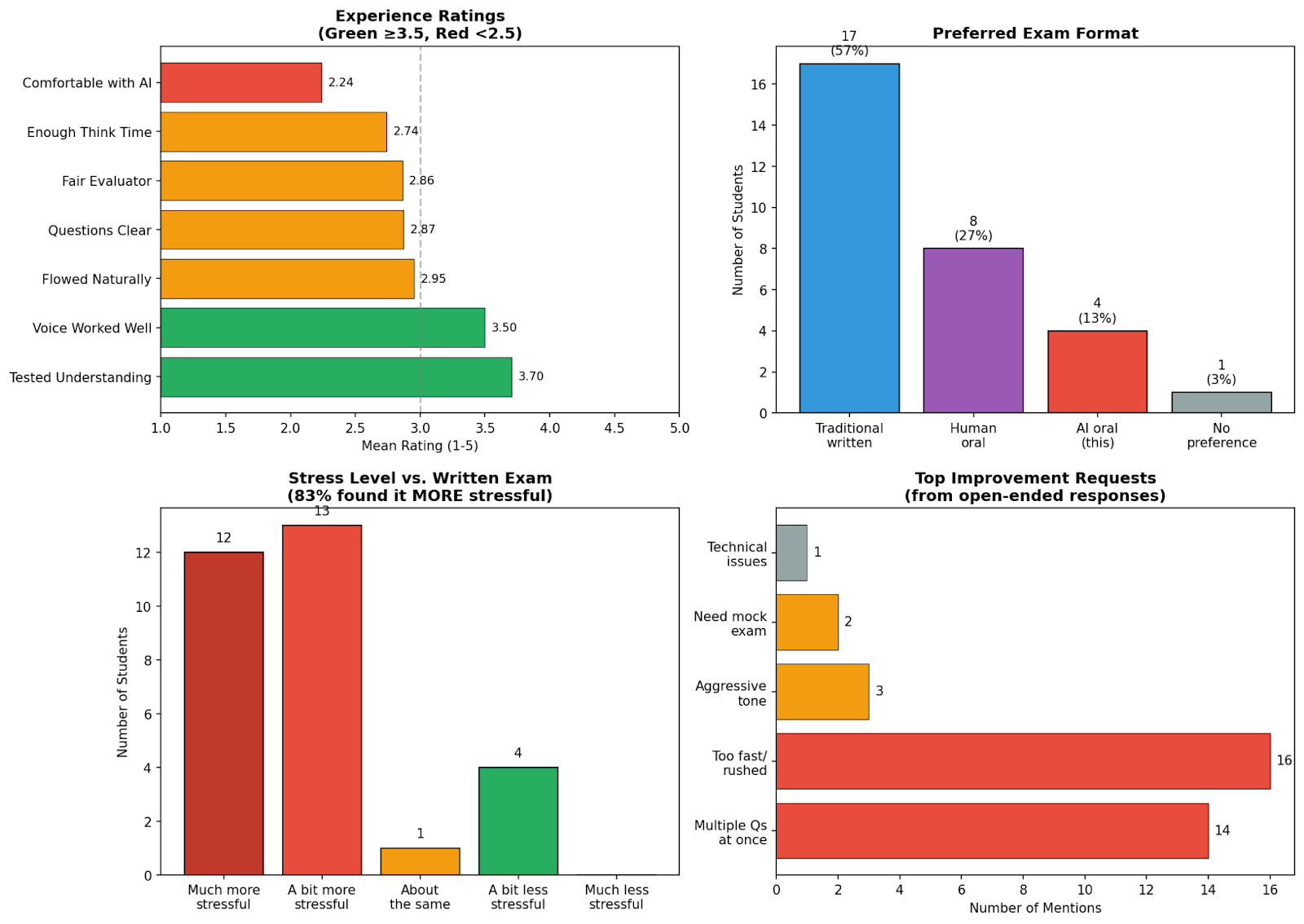
The first version had problems, Ipeirotis said. Some students complained about the agent's harsh tone. Professors replicated their colleagues' voices, which students found to be “harsh” and “condescending.” “The agent was yelling at me,” one student emailed.
Other issues: The agent asked multiple questions at once, paraphrased the question instead of repeating it verbatim when asked, and asked too many questions too quickly during pauses.
Randomization was particularly difficult. When asked to “randomly” select a case, agents chose Zillow 88% of the time. After removing it from the prompt, the agent reached “predictive policing” on 16 of 21 tests the next day.
“Asking an LLM to “pick a random number'' is like asking a human to “think of a number from 1 to 10.'' You'll end up with a lot of 7s,'' Ipeirotis says. He describes a well-documented phenomenon that ultimately results from human bias in the training data.
A panel of three AI models did the grading
The grading followed Andrej Karpathy's “Council of LLMs” approach. The three models, Claude, Gemini, and ChatGPT, first evaluated each transcript individually and then reviewed each other's ratings to revise their ratings.
The initial agreement was poor, with Gemini averaging 17 out of 20 points, while Claude only 13.4. According to the diagram provided, 60% of the ratings were within 1 point after the built-in LLM consultation step. 29% had an exact match. Gemini saw Claude's criticism of certain gaps and lowered their scores by an average of 2 points.
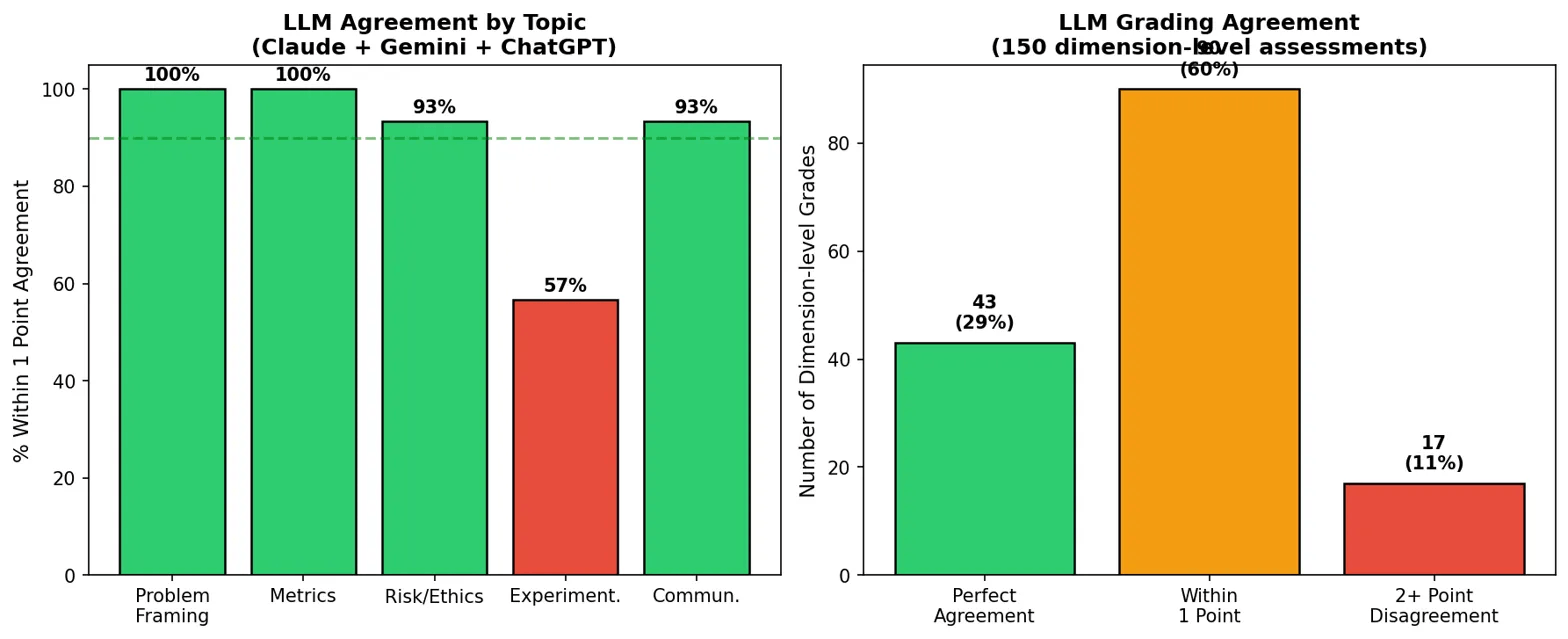
According to Ipeirotis, the AI-generated feedback produced better results than human graders. That is, a structured summary of strengths and weaknesses, including verbatim quotes from the exam.
The topic-by-topic analysis also revealed gaps in education itself. For “Experiment,'' students' average score was only 1.94 out of 4, compared to 3.39 for “Problem Construction.'' Three students were unable to discuss the topic at all, and none received full marks. Ipeirotis admits that the course ignored A/B testing techniques. “We can no longer ignore external scorers,” he says.
Another finding was that there was no correlation between exam length and performance. The shortest exam at 9 minutes received the highest score. The longest one was 64 minutes and was a mediocre performance.
Students found the AI exam stressful but fair.
Student surveys showed mixed reactions. Only 13 percent preferred the AI format, and twice as many preferred a human oral examiner. 83% find AI exams more stressful than written exams. However, approximately 70% agreed that the content actually tested their understanding, making it the highest rated item in the survey.
Ipeirotis summarizes that oral exams were the norm until they were scaled back. AI makes them practical again. One advantage over traditional exams is that new questions are generated each time, allowing students to practice the settings. Leakage of exam questions is no longer an issue.
Ipeirotis published prompts for the voice agent and scoring panel, as well as a link to try the agent for yourself.
AI News Without the Hype – Curated by Humans
as The Decoder Subscriberyou can read without ads. Weekly AI Newsletterexclusive “AI Radar” Frontier Report 6 times a yearaccess to comments, and Complete archive.
Subscribe now


