
AI models, inference engine backends, and distributed inference frameworks continue to evolve in architecture, complexity, and scale. The rapid pace of change makes it a critical challenge to deploy and efficiently manage AI inference pipelines that support these advanced features.
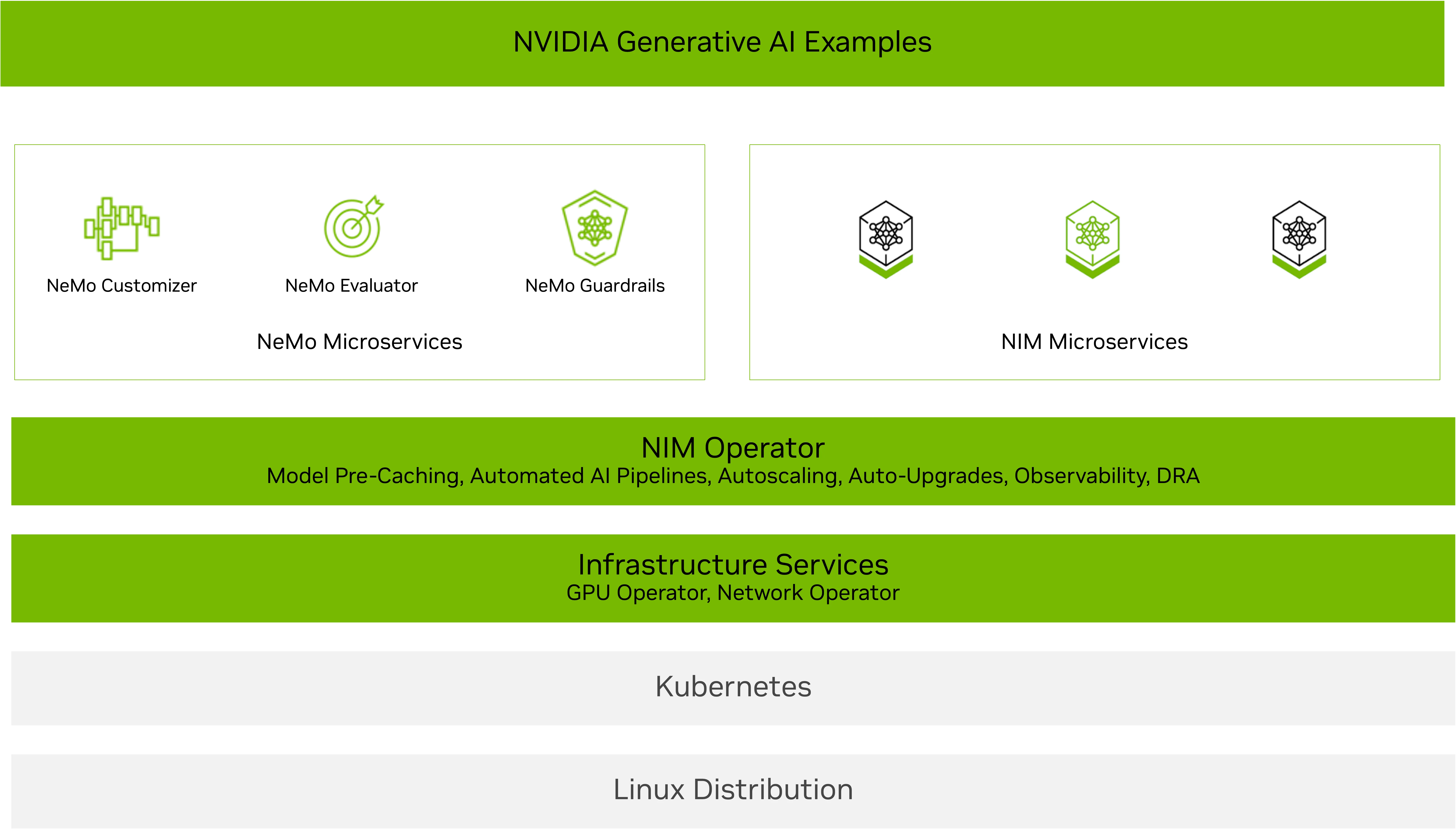
The NVIDIA NIM operator is designed to help you scale intelligently. This allows Kubernetes cluster administrators to operate the software components and services needed to run the latest LLMS and multimodal AI models of NVIDIA NIM inference microservices, including inference, search, vision, speech, biology, and more.
The latest release of NIM Operator 3.0.0 introduces enhancements to simplify and optimize the deployment of NVIDIA NIM microservices and Nvidia Nemo microcell services across Kubernetes environments. NIM Operator 3.0.0 supports efficient resource utilization and seamlessly integrates with existing Kubernetes infrastructure, including KSERVE deployments.
NVIDIA customers and partners use NIM operators to efficiently manage inference pipelines for a variety of applications and AI agents, including chatbots, agent RAGs, virtual drug discovery, and more.
Nvidia recently collaborated with Red Hat to enable NIM deployments in KSERVE with NIM operators. “Red Hat contributed to the open source Github Repo of NIM operators to enable the deployment of NVIDIA NIM on KSERVE,” said the director of Babaku Mozafari at Red Hat. “This feature allows NIM operators to deploy NIM microservices that benefit from KSERVE lifecycle management and simplify scalable NIM deployments using NIM services. Native KSERVE support in NIM operators allows NIM caches to benefit from model caches and leverage Nemo's capabilities to use Nemo Guardrails' Endive Endpoint.
This post covers new features in the NIM Operator 3.0.0 release.
Flexible NIM deployment: Multi-LLM compatibility and multi-node
NIM Operator 3.0.0 adds support for easy and fast NIM deployments. Available with a variety of NIM deployment options, including domain-specific NIM or multi-LLM compatible or multi-node, such as biology, voice, or search.
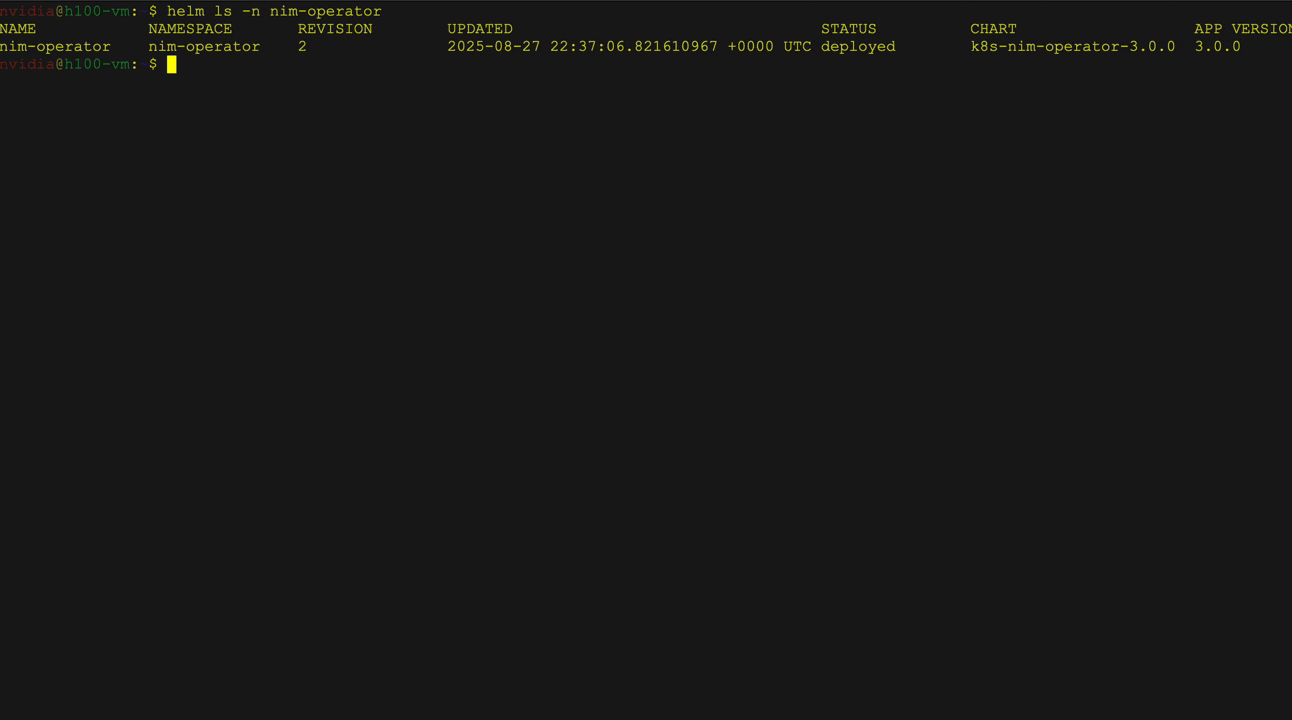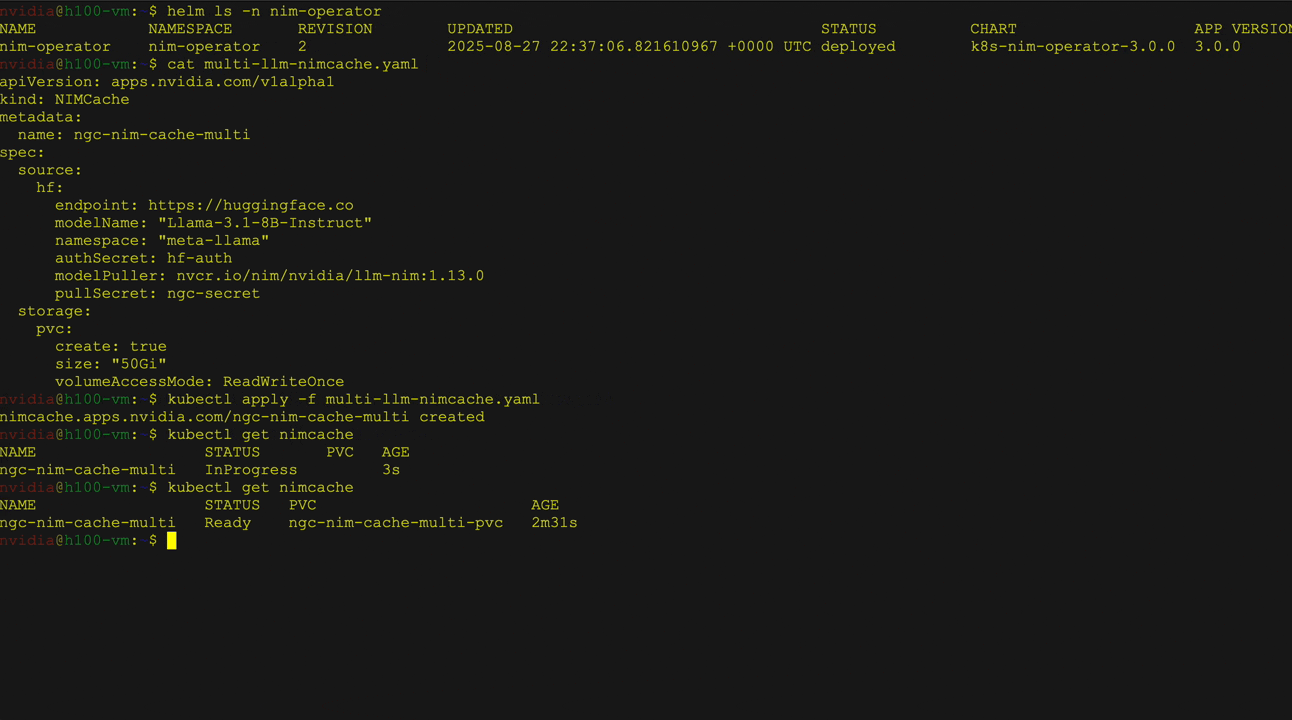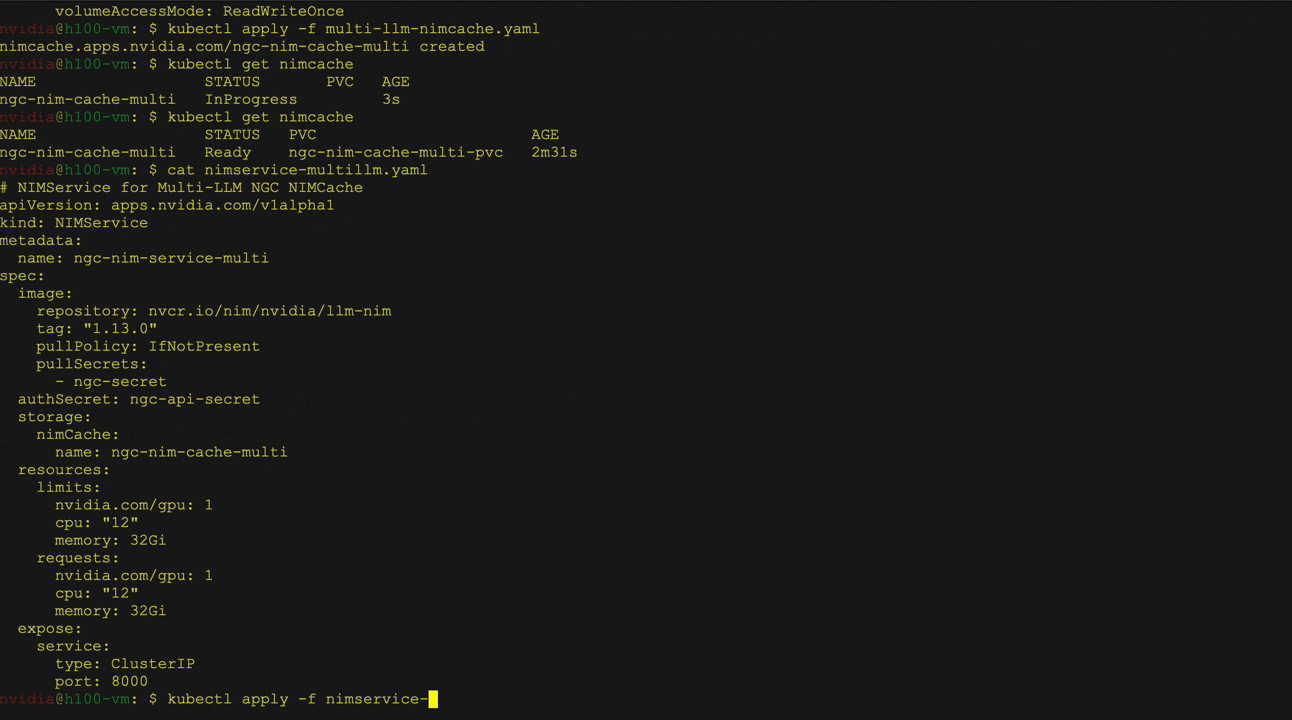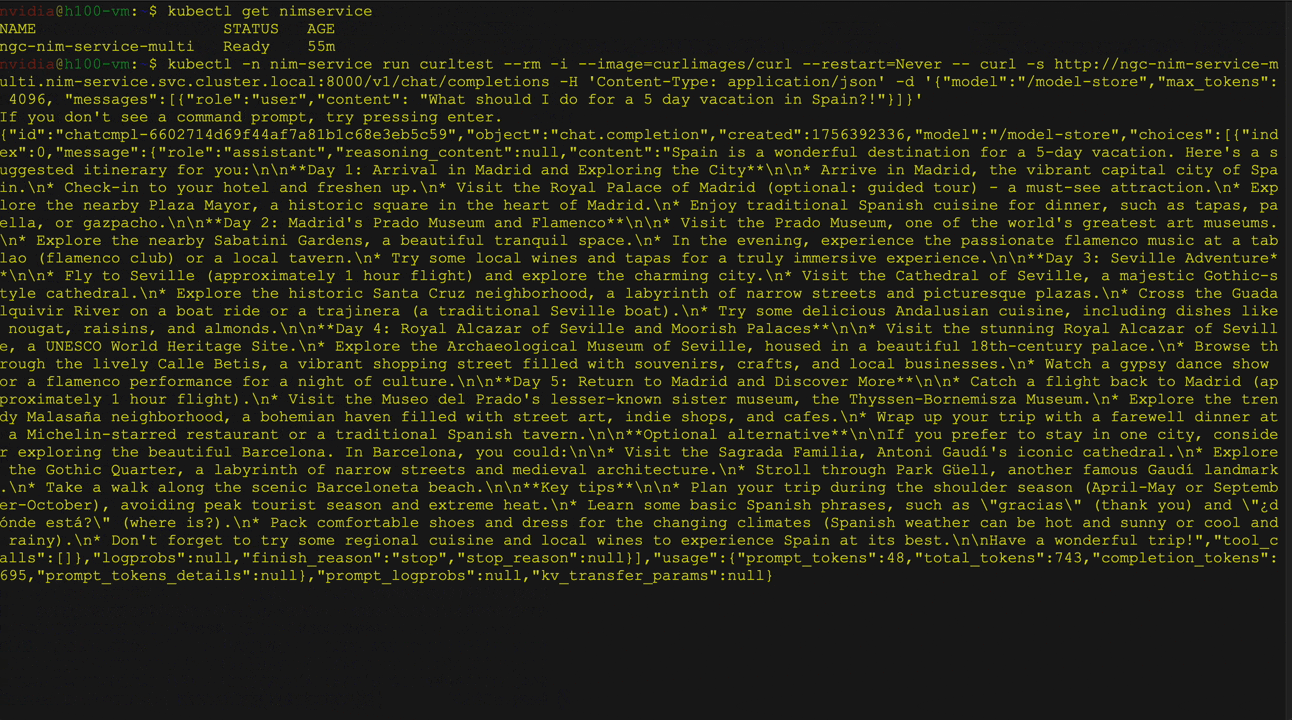
- Multi-llm compatible NIM deployment: Expand a variety of models using custom weights from sources such as Nvidia NGC, hugging faces, and local storage. Use NIM Cache Custom Resource Definitions (CRDs) to download weights to PVC and NIM Service CRDs to manage deployment, scaling, and ingress.
- Multi-node NIM deployment Addresses the challenge of deploying huge LLMs that cannot fit a single GPU or that need to run on multiple GPUs and potentially multiple nodes. The NIM operator supports caching in multi-node NIM deployments using NIM Cache CRDs and deploys them using the NIM Services CRDs in Kubernetes using the Reader Worker Set (LWS).
Note that a multi-node NIM deployment without GPudirect RDMA can result in frequent reboots of LWS readers and worker pods due to load timeouts of model debris. It is highly recommended to use high-speed network connections such as IPOIB or ROCE, and can be easily configured via an NVIDIA network operator.
Figure 2 shows the deployment of a large language model (LLMS) from Kubernetes' embrace face library using the NVIDIA NIM operator as a multi-LLM NIM deployment. It specifically illustrates the deployment of the Llama 3 8b directive model, including validation of service and pod status. curl A command that sends a request to a service.
Efficient GPU usage with DRA
DRA is a built-in Kubernetes feature that simplifies GPU management by replacing traditional device plugins with a more flexible and scalable approach. DRA allows users to define GPU device classes, request GPUs based on those classes, and filter them according to workload and business needs.
NIM Operator 3.0.0 supports DRA in Technology Preview by configuring ResourceClaim and ResourceCameTemplate in the NIM POD via both the NIM Service CRD and the NIM Pipeline CRD. You can create and attach your own claims or create and manage them automatically with NIM operators.
Supported by NIM Operator DRA.
- Full GPU and MIG Usage
- GPU sharing through time slicing by assigning the same claim to multiple NIM services
Note: This feature is currently available as a technology preview with full support coming soon.
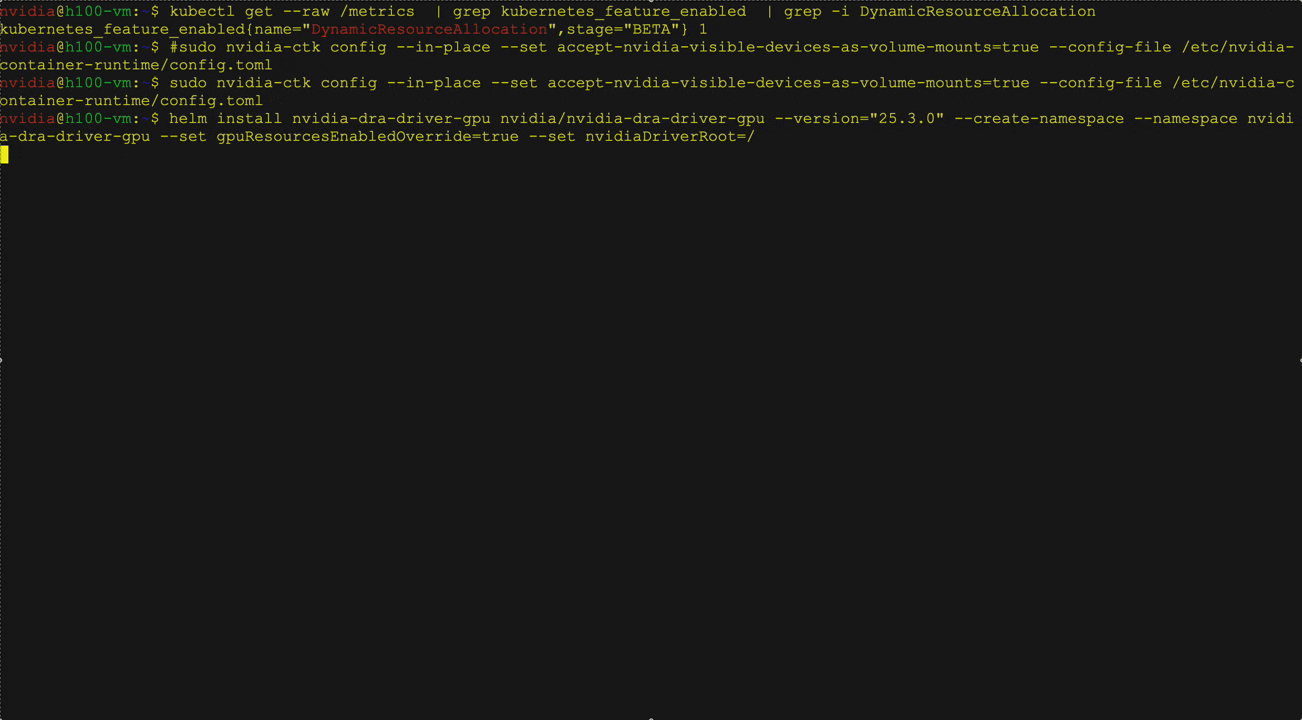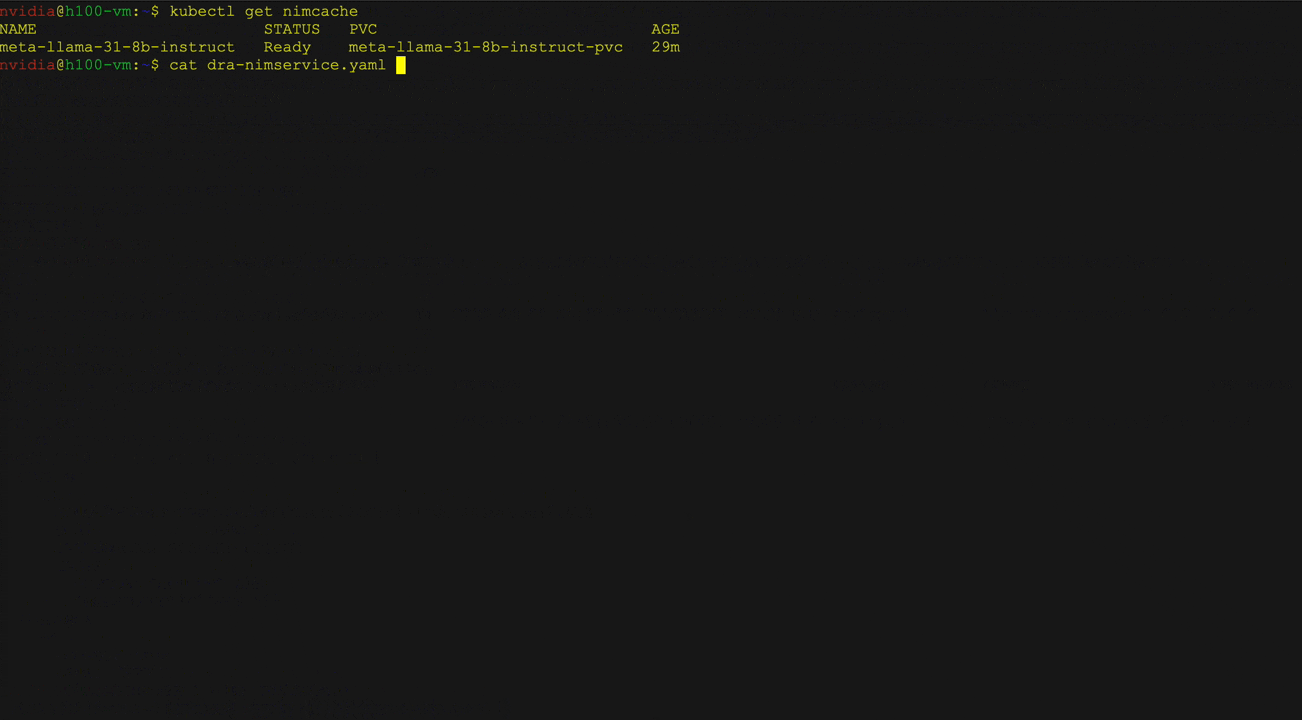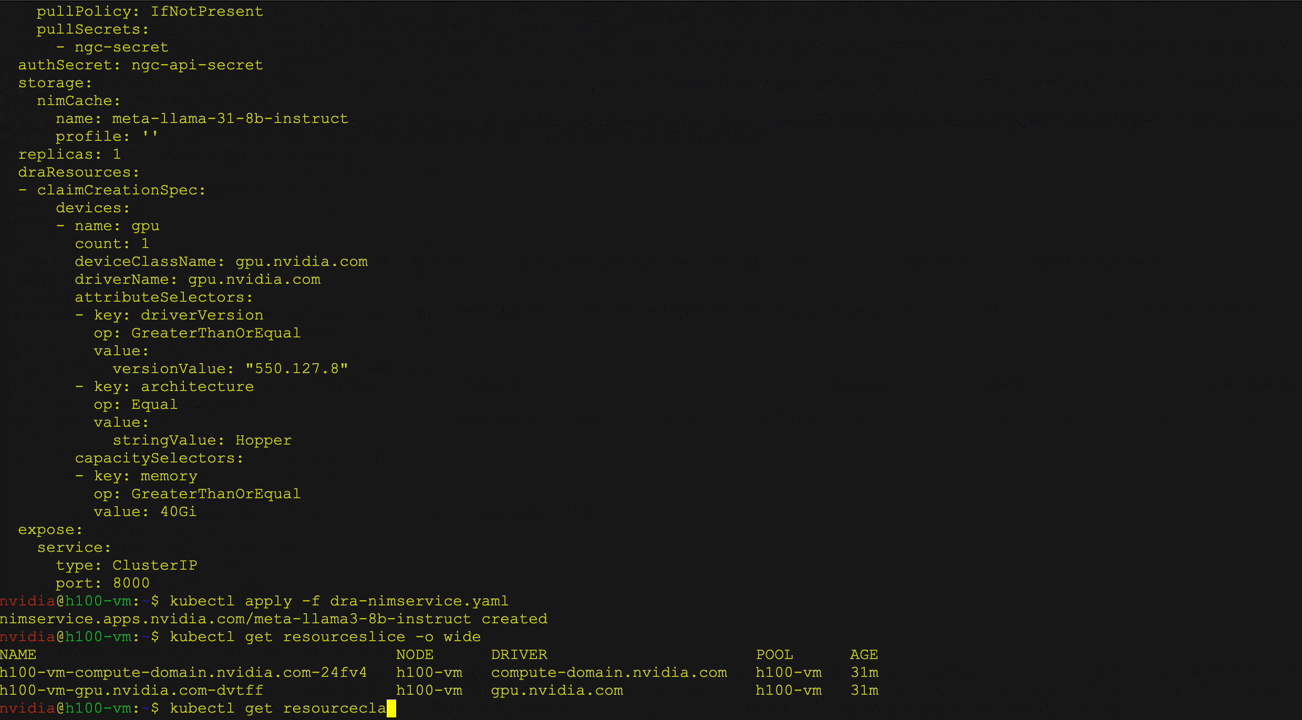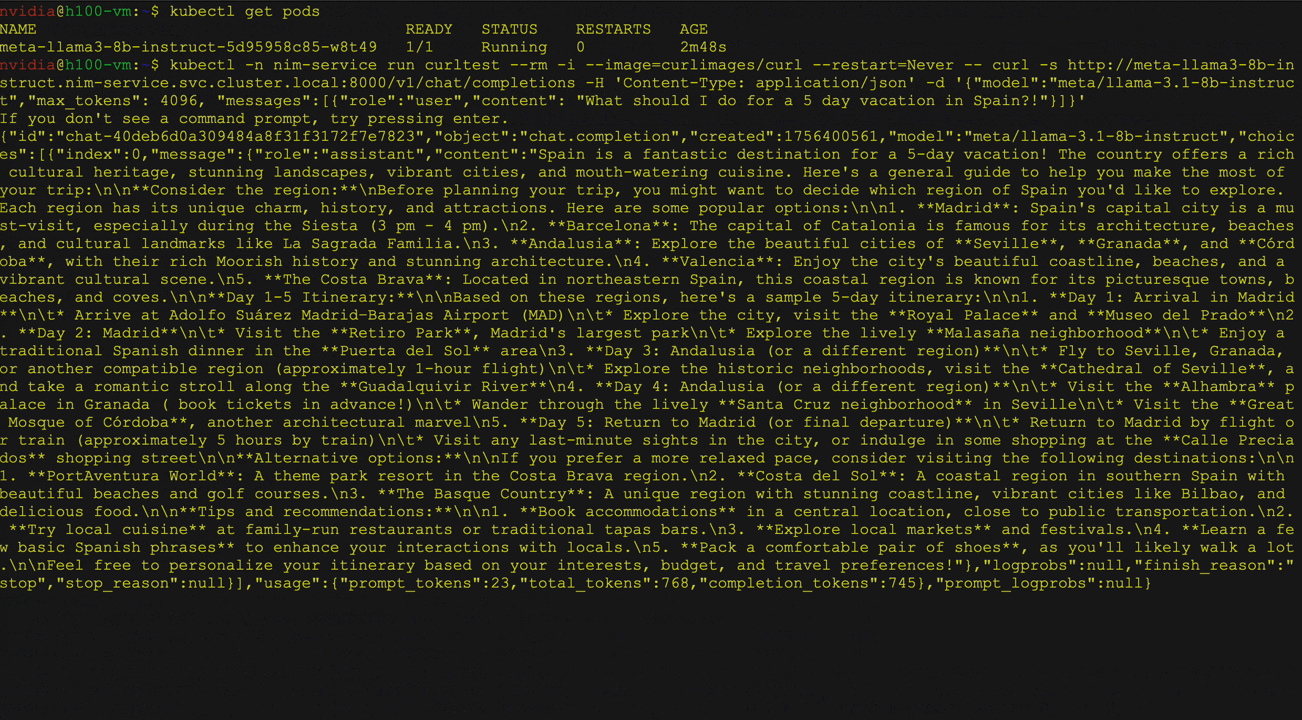
Figure 3 shows the deployment of the Llama 3 8b directed NIM using the NIM operator using Kubernetes DRA. Users can define resource claims for NIM services, request specific hardware attributes, such as GPU architecture and memory, and interact with deployed LLM. curl.
Seamless development with Kserve
KSERVE is a widely adopted open source inference platform used by many partners and customers. NIM Operator 3.0.0 supports both raw and serverless deployments in KSERVE by configuring inference services custom resources to manage NIM deployment, upgrade and automation. The NIM operator simplifies the deployment process by automatically configuring all the environment variables and resources needed in the Inference Service CRD.
This integration offers two additional benefits:
- Intelligent caching using NIM cache reduces initial inference time and automation latency, resulting in faster and more responsive deployments.
- NEMO Microservices supports evaluation, guardrails, and customization to enhance AI systems for delay, accuracy, cost, and compliance.
Figure 4 shows the deployment of the Llama 3.2 1b directed NIM for KSERVE using the NIM operator. Two different deployment methods are shown: Rawdeployment and ServerLess. Serverless deployments incorporate automation capabilities through K8S annotations. Both strategies use the CURL command to test the NIM response.

Start scaling AI inference using NIM operator 3.0.0
NVIDIA NIM Operator 3.0.0 makes scalable AI inference easier than ever. Whether you're using Multi-LLM compatible or multi-node NIM deployments, optimize GPU usage with DRA, or deployment with KSERVE, this release allows you to build high-performance, flexible, and scalable AI applications.
Automating deployment, scaling and lifecycle management for both NVIDIA NIM and NVIDIA NEMO microservices, NIM operators make it easy for enterprise teams to embrace AI workflows. This initiative makes AI workflows easy to deploy with NVIDIA AI Blueprints, allowing for faster production movements. The NIM Operator is part of NVIDIA AI Enterprise and offers enterprise support, API stability, and proactive security patching.
Start with NGC or NVIDIA/K8S-NIM-OPERATOR Open Source GitHub Repo. For technical questions regarding installation, usage, or issues, please submit the issue to the NVIDIA/K8S-NIM-OPERATOR GitHub Repo.

