
![]()
summary
MIT researchers have introduced a new framework called SEAL, which allows large-scale language models (LLMS) to generate their own synthetic training data and improve themselves without external help.
The seal works in two stages. First, the model learns to use reward learning to create effective “self-editing.” These self-editing are written as natural language instructions that define new training data and set optimization parameters. In the second stage, the system applies these instructions and updates its own weights through machine learning.

An important part of the seal is its rest^em algorithm, which acts like a filter. Hold and enhance self-editing that actually improves performance. The algorithm collects various edits, tests which edits, tests which ones worked, and trains the model using only successful variants. SEAL also uses the Low Rank Adapter (LORA), a technique that allows for quick and lightweight updates without retraining the entire model.
The researchers tested the seals in two scenarios. First, they used QWEN2.5-7B in the text comprehension task. This model generated logical inferences from the text and trained it with its own output.
advertisement

The seal reached 47% accuracy, breaking 33.5% of the comparison method. The quality of self-generated data exceeded Openai's GPT-4.1 despite much less underlying models.
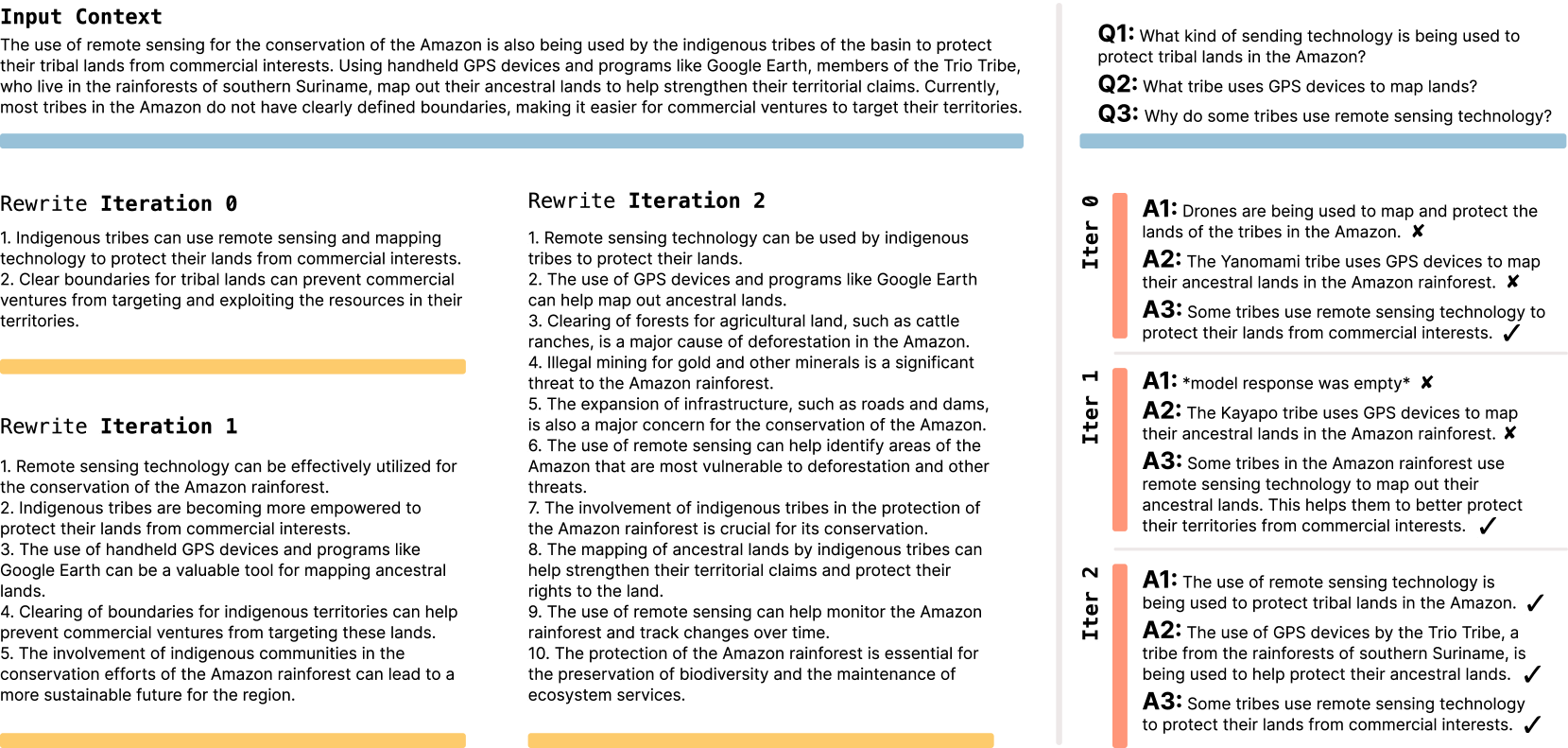
In the second test, the team considered a few shots prompt using Llama 3.2-1B in the inference task. Here, this model selected a variety of data processing techniques and training parameters from the preset toolkit. With SEAL, the model achieved a success rate of 72.5%, but only 20% without previous training.
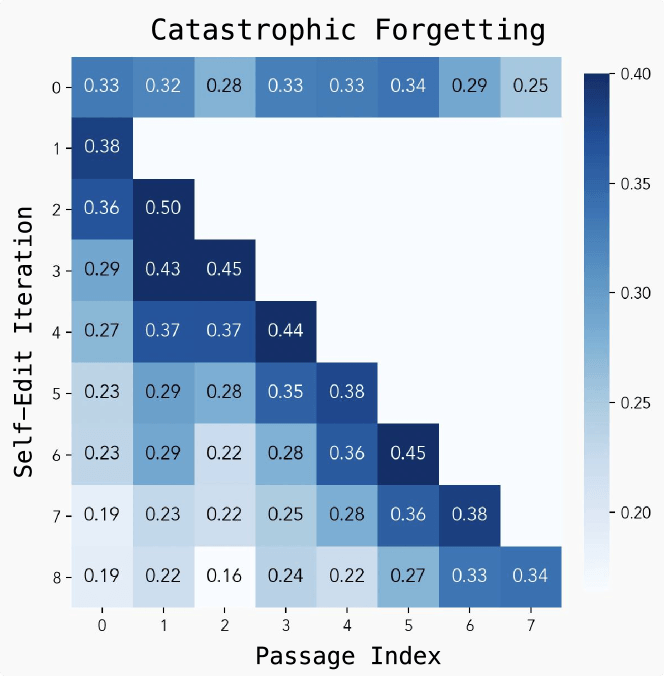
“Devastating Forgetting” remains a challenge
Despite strong results, researchers have discovered several limitations. The main problem is “devastating forgetting.” When the model assumes a new task, it starts to lose performance on the previous task. Each self-editing evaluation takes 30-45 seconds, so training is also resource intensive.
Working on the data wall
The MIT team is looking at steps and stickers to overcome the so-called “datawall.” This is the point where all available human-generated training data is used. Apart from that, researchers have also warned of the risk of “model collapse.” In “model collapse,” the model will reduce the quality if it is trained too much with low-quality AI-generated data. Seals can enable continuous learning and autonomous AI systems that continue to adapt to new goals and information.
If models can teach themselves by absorbing new materials like scientific papers and generating their own explanations and inferences, they can continue to improve rare or underrated topics. This kind of self-directed learning loop can help push the language model beyond current limitations.
recommendation

The source code for the stickers is available on GitHub.


