
Machine learning is at the forefront of innovation, enabling a transformative user experience. With advances in client silicon and model miniaturization, new scenarios could be implemented completely locally.
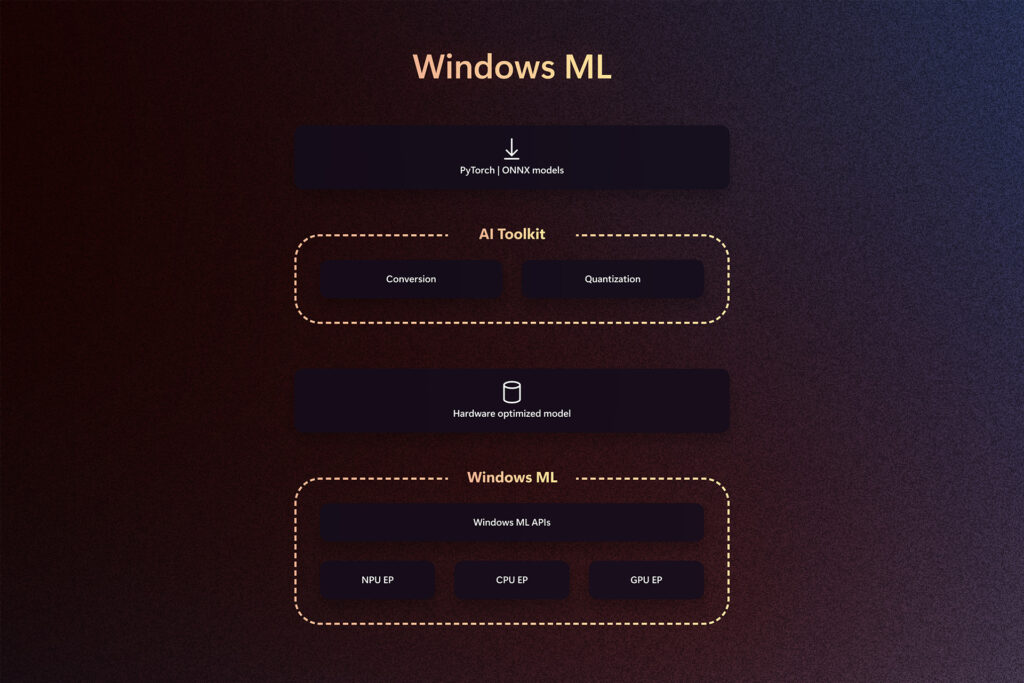
To support developers shipping production experiences in increasingly complex AI situations, we are excited to announce a public preview of Windows ML – A cutting-edge runtime optimized for performance-on-device models inference and simplified deployment, and Windows AI Foundry fundamentals.
Whether it's an entry-level laptop, a Copilot+PC, or a state-of-the-art AI workstation, Windows ML is designed to help developers who can easily create AI-injected applications by leveraging the incredible strength of Windows' diverse hardware ecosystems. It is built to allow developers to take advantage of the client silicon that is best suited for a particular workload on a particular device. This is a low-power and sustained reasoning NPU, raw horsepower GPU, or a CPU for the widest footprint and flexibility.
Windows ML offers a unified framework, allowing developers to confidently target Windows 11 PCs available today. It was built to optimize model performance and agility and to accommodate the speed of model architecture, operators and optimization innovation across all layers of the stack. Windows ML is an evolution of DirectML (DML) based on learning over the past year, listening to feedback from many developers, silicon partners, and unique teams developing AI experiences for Copilot+ PCs. Windows ML is designed with this feedback in mind, empowering partners from AMD, Intel, Nvidia and Qualcomm to leverage execution provider agreements to optimize model performance and match the pace of innovation.
Windows ML is powered by the ONNX Runtime Engine (ORT), allowing developers to use the familiar ORT API. With ONNX as a native model format, Pytorch's support for intermediate representation of EPS, Windows ML ensures seamless integration of existing models and workflows. A key design aspect is leveraging and enhancing existing ORT Execution Provider (EP) contracts to optimize workloads for various client silicon. Built in collaboration with independent hardware vendors (IHVs), these execution providers are designed to optimize model execution on existing and emerging AI processors, allowing each to showcase the most functionality. We are pleased to work closely with AMD, Intel, Nvidia and Qualcomm to seamlessly integrate EPS into Windows ML and support the complete set of CPUs, GPUs and NPUs from day one.
AMD Fully support for Windows ML for Ryzen AI products. AMDGPU and AMD NPU running providers allow maximum GPU and NPU leverage on the platform. learn more.
“Windows ML seamlessly integrates CPUs, GPUs and NPUs across AMD's portfolio, including the Ryzen AI 300 series, allowing ISVs to deliver groundbreaking AI experiences. The deep partnership between Microsoft and AMD is driving the future on Windows, optimizing performance, efficiency and innovation.” – John Rayfield, Vice President of AI, AMD
Intel Integrate the development and deployment simplicity provided by Windows ML for OpenVino performance and efficiency via CPU, GPU and NPU, allowing AI developers to more easily target XPUs, the best choice for a wide range of products powered by Intel Core Ultra processors. learn more.
“Microsoft's partnership with Microsoft on Windows ML supercharges AI app development by firmly integrating high-performance, high-precision workflows into the Windows ecosystem. If you are targeting CPUs, GPUs or NPUs, developers can deploy flexibly to XPUs. Anywhere.” – Sudhir Tonse Udupa, Vice President of AI PC Software Engineering, Intel
nvidia's The new Tensort EP is the fastest way to run AI models on NVIDIA RTX GPUs with over 100 million RTX AI PCS. Compared to previous direct ML implementations, Tensort for RTX offers up to twice as fast performance for AI workloads. learn more.
“Today, Windows developers often need to choose the wide range of hardware compatibility and full performance for their AI workloads. Through WindowsML, developers can easily support a wide range of hardware while achieving full Tensort acceleration with NVIDIA GeForce RTX and RTX Pro GPUs.” – Jason Paul, Vice President of Consumer AI, Nvidia
Qualcomm Technologies Inc. Microsoft collaborated to develop and optimize Windows ML-based AI models and applications for NPUs on Snapdragon X-Series processors using the Qualcomm Neural Network Execution Provider (QNN EP). learn more.
“The new Windows ML cutting-edge runtime not only optimizes model inference on devices, but also simplifies deployment, making it easier for developers to take full advantage of the full potential of Snapdragon's advanced AI processors.xSeries Platform. The unified framework of Windows ML and support for a wide range of hardware including NPUs, GPUs and CPUs allows developers to create AI applications that provide superior performance and efficiency on a wide range of devices. We look forward to continuing our collaboration with Microsoft to drive development innovation and speed, and bringing you the best AI experience with Windows Copilot+ Platforms. ”– Upendra Kulkarni, VP, Product Management, Qualcomm Technologies, Inc.
There are several important aspects to Windows ML highlighting.
- Simplified deployment: With the infrastructure API, developers no longer need to create multiple builds of their apps and target different silicon, as they don't need to directly bundle ONNX or running providers in their applications. It provides an easy way to make them available on your device, register them, and enable pre-pre-(AOT) model compilation.
- Advanced silicon targeting: Leverage device policies to optimize for low power, high performance, or override to accurately specify the silicon that leverages a particular model. In the future, this will allow for splitting operations for optimal performance. Take advantage of some pieces of the model, the CPU or GPU of the NPU.
- performance: Windows ML is designed for performance. It is built on the foundations of the ONNX and ONNX runtimes. There is an improvement of up to 20% compared to other model formats. Over time, we will add window-specific features for further optimization, such as progressive memory mapping, partial model pinning, and an optimized scheduler for parallel execution.
- Compatibility: Windows ML, working with IHV partners, can rely on continuous improvement, ensuring compatibility and compatibility, ensuring model accuracy building.
However, it introduces a robust toolset not only in the runtime, but also in the AI Toolkit for VS code to support model and app preparation. Transforms from Pytorch, quantization, optimization, editing and profiling to help developers ship production applications in dedicated models. These tools are specifically designed to simplify the process of preparing and shipping performance models via Windows ML without having to create multiple builds and complex logic.
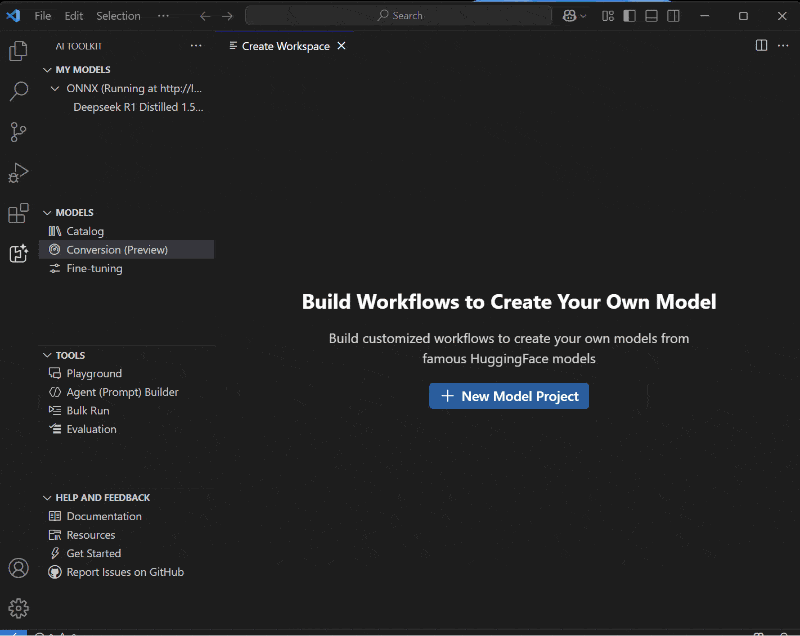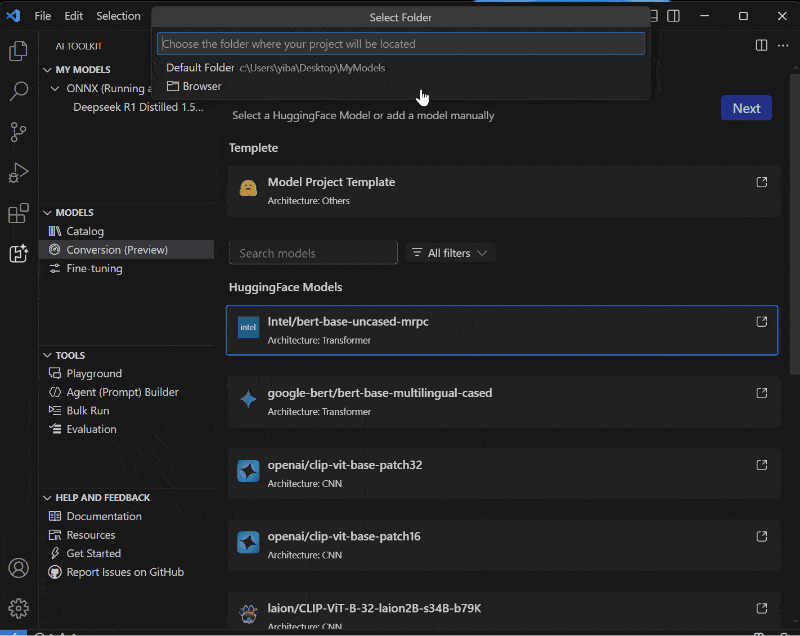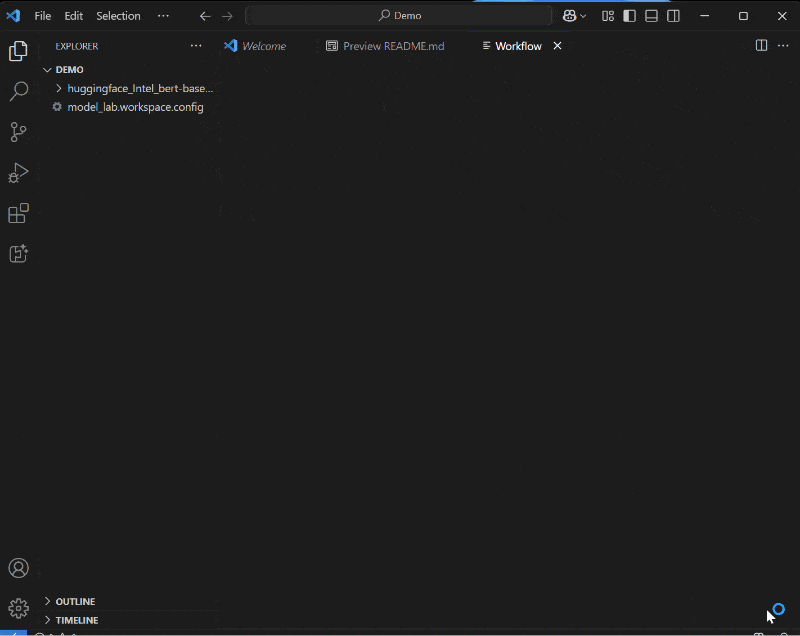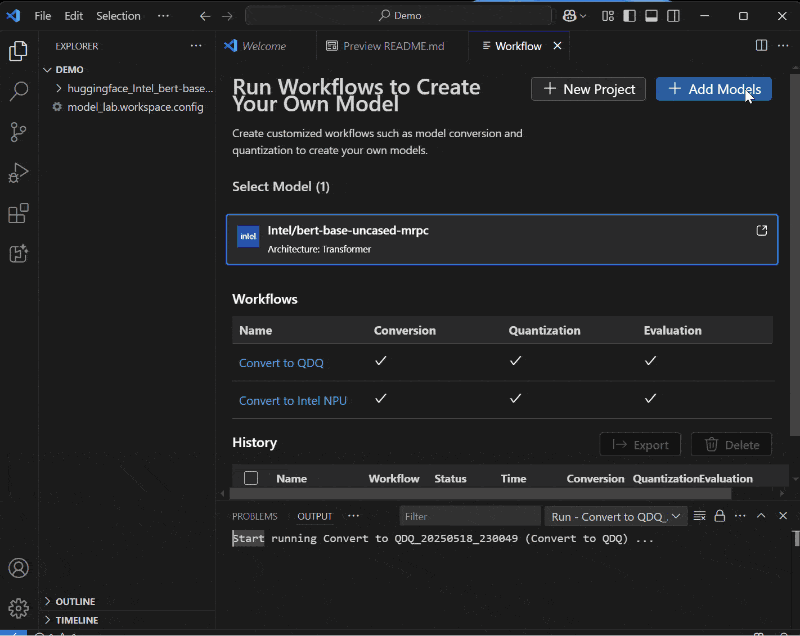
Windows ML is available in public previews starting today on all Windows 11 machines worldwide, providing developers with the opportunity to explore its features and provide feedback. The preview includes two layers of APIs.
- ML Layer: High-level API for helper APIs for establishing runtime initialization, dependency management, and generation AI loops.
- Runtime Layer: The low-level ONNX runtime API provides fine-grained control over inference on the device.
To get started, install AI Toolkit, take advantage of one of the conversion and optimization templates, or create your own. It will help you explore the documentation and code samples available in Microsoft Learn, check out AI Dev Gallery (installation, documentation) such as DEMOS to get you started with Windows ML.

While building Windows ML, it was important to receive feedback and perspective from app developers, especially those on the forefront of delivering AI-powered features and experiences. I've shared an early preview of Windows ML with some major developers testing integration with Windows ML, and am excited by the early response.
Adobe (Volker Rölke – Senior ML Computer Scientist): “Adobe Premiere Pro and After Affects Effects juggle footage and terabytes of heavy ML workloads. The reliable Windows ML API, which provides consistent performance across heterogeneous devices, removes huge obstacles and ships faster.
Buffer Zone (Dr. ran dubin, cto, bufferzone): “At Bufferzone, we believe that PCs with AI represent the future of endpoints. WindowsML simplifies the challenges of ISV integration, reduces time to the market and increases adoption rates.
Filmora (Luyan Zhang – AI Product Manager): “Simplicity surprises me. I followed Microsoft's simpler approach that added the ONNX model to the app, converting complex AI features to Windows ML in just three days.”
McAfee (Carl Woodward, Sr. Principal Engineer): “We are excited about the efficiency Windows ML can bring to the development and management of McAfee+'s new fraud detection capabilities.Windows ML allows you to focus on high impact areas such as model accuracy and performance, providing you with confidence that AI components will work well across the ecosystem, including new hardware revisions.”
powder (Barthélémy Kiss – Co-founder and CEO of Powder): “Powder was an early adoption of Windows ML, allowing the model to be tripled faster and integrated speed into key strategic benefits. With Windows 11 handling heavy lifting across the silicon provider, it now allows powder developers to focus on doing their best.– Develop more magical AI video experiences in less time and with a much more dramatically lower operating costs. ”
Re-incubate (Aidan Fitzpatrick – CEO): “We promise to make the most of the new AI hardware chipset on the first day. And Windows ML should be a powerful tool that will help you move at the speed of silicon innovation. For us, the Holy Grail takes a single, high-precision model, runs Windows Silicon seamlessly, and I think Windows ML is in the right direction.”
Topaz Labs (Dr. Suraj Raghuraman – Head of AI Engine):“WindowsML drops from gigabytes to gigabytes, significantly reducing installer sizeMegabytes.This allows users to do more on disk. Model Storage The requirements will also be reduced. Windows ML relies heavily on the ONNX runtime,It was really easy for us to integrate it. Integrated API as a wholeWithin a few days it has become a seamless experience from an innovation perspective.”
Whether you're a veteran AI developer or exploring ML for the first time, Windows ML can focus on innovation rather than infrastructure management, making it a joy to your customers with AI-infused applications. Windows ML will typically be available later this year. In the meantime, we look forward to your feedback and how we can leverage Windows ML to create solutions that redefine possibilities. Join today's Windows ML Journey and become part of the next wave of AI innovation!
Editor's Notes – May 19, 2025 – The above section on Windows ML with the ONNX runtime engine has been updated to provide additional details.


