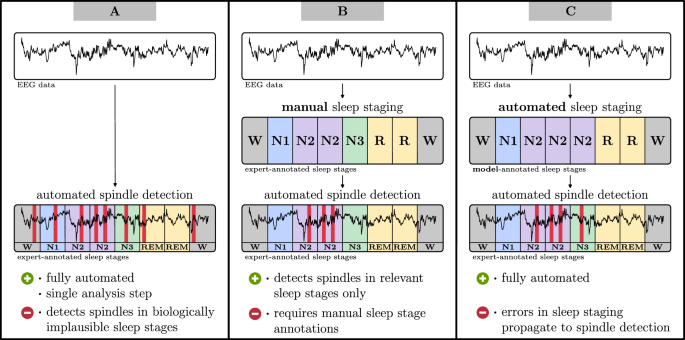
Automatic detection of sleep stages
dataset: The IS-RC dataset contains PSG recordings for each of 70 women recorded in a research study investigating sleep-disordered breathing in midlife (40-57 years) women.18. All 70 recordings were annotated by 10 expert scorers following American Academy of Sleep Medicine (AASM) guidelines.8the annotations of 6 experts are published. We aggregated these annotations into a consensus following the approach outlined by Stephansen et al.19. One recording was discarded due to a mismatch between the annotation file name and the corresponding EEG recording.
The BD (Bipolar EEG Dataset) dataset contains one PSG recording from each of 25 healthy controls and 23 bipolar disorder patients.17. The 48 recordings were annotated by a single expert according to AASM guidelines. Due to differences in channel settings, our analysis focused on a set of EEG channels common to all recordings: F3-A2, F4-A1, C3-A2, C4-A1, O1-A2, O2-A1, and A1-A2. The sampling rate varies between 100 Hz, 200 Hz, or 500 Hz depending on the recording and channel.
All recordings were divided into 30-s epochs and labeled as either wakefulness, N1, N2, N3, or REM sleep stages by an expert annotator.
model: We used the RobustSleepNet (RSN) model for automated sleep staging. This is a deep learning model designed to be insensitive to the number, type, and order of PSG montages.11. Guillot et al. Provides several checkpoints for RSNs trained on EEG, EOG, and EMG data from various datasets35. We used checkpoints trained on 659 recordings from MESA36Mr. OS37S.H.S.38dodo39Department of Defense39,trout40 Dataset. The model accepts an input sequence of 21 sleep epochs (i.e., 10.5 minutes) to ensure sufficient context for the classification of each epoch. Given an input sequence, the model outputs the probabilities for each of the five sleep stages for each epoch. Depending on the model architecture, the input sequence can contain any number of channels.
Follow standard procedures for using RSNs11Each recording was preprocessed before being scored by the model using a fourth-order Butterworth bandpass filter (0.3–30 Hz), downsampled to 60 Hz, and normalized by subtracting the median and dividing by the interquartile range. Amplitudes outside the -20 to 20 range were clipped to these boundaries. To prevent the model from making predictions based on incomplete sequences, we buffered the beginning and end of each preprocessed recording with 20 zero sleep epochs. We then created the input sequence to the model by sliding a window of 21 epochs with a step size of 1 epoch over the buffered recording (i.e., each epoch was part of the 21 input sequence). The resulting 21 predicted probabilities for each sleep epoch were aggregated by calculating the geometric mean to obtain the final prediction for each epoch.11.
evaluation: Given two sets of annotations for a recording, we determined the degree of agreement between the two sets by calculating the macro F1 score as follows. For each sleep stage, we first counted the number of epochs that matched in both annotations as true positives (TP). A false positive (FP) was defined as an epoch that was labeled as a specific sleep stage in one annotation, but a different stage was assigned in the other annotation. Conversely, a false negative (FN) is an epoch that is assigned a different stage in one annotation, but labeled as the specified stage in another annotation. The precision and recall of a stage are calculated as TP / (TP + FP) and TP / (TP + FN), respectively, and the F1 score for that stage is given by 2. \(\times\) (accuracy \(\times\) Recall) / (Precision + Recall). Finally, the macro F1 score was calculated by averaging the stage-specific F1 scores.
Automatic detection of sleep spindles
Sleeping spindles were detected using SUMOv2, an enhanced version of the publicly available SUMO model16. Our improvements focused on increasing robustness to amplitude scale variations and ensuring more reliable spindle detection across diverse datasets.
Dataset: The MASS dataset contains 200 PSG recordings from 200 mostly healthy subjects (15 subjects were diagnosed with mild cognitive impairment) and was sampled at 256 Hz.40. The MODA dataset provides spindle annotations on selected sections of 180 recordings from MASS21,41. Each of these recordings was divided into 10 (30 recordings) or 3 (150 recordings) blocks of artifact-free 115 s N2 sleep. Blocks were annotated for spindles by up to seven human experts and annotated using the C3-A2 or C3-LE EEG channel depending on the recording. In total, the MODA dataset contains 749 blocks annotated by 47 experts (one block was not presented to any expert). Annotations were aggregated into a consensus based on experts’ confidence in the annotations.twenty one. For simplicity, we refer to the combination of the MASS and MODA datasets as the MODA dataset.
The DREAMS dataset consists of eight 30-minute long EEG data segments sampled at 50, 100, or 200 Hz from eight subjects with various medical conditions (insomnia, restless leg syndrome, insomnia, and apnea/hypopnea syndrome).20. Segments were extracted from one night of recordings, regardless of the underlying sleep stage or the presence of artifacts. Each segment was annotated for spindles by two human experts, except for the last two segments, which were only annotated by the first expert. Depending on the segment, experts were presented with the C3-A1 or CZ-A1 EEG channel but were not given any information about the sleep stage identified by another expert. We removed all spindle annotations except N2 sleep based on sleep stages annotated by another expert.
The BD dataset (see also section Automatic detection of sleep stages) contains artifact-free spindle annotations for N1, N2, and N3 sleep stages17. Similar to the original study17we focused on spindles during N2 sleep in our analysis. Spindle annotations are created by an expert and a second expert verifies the annotations in case of uncertainty. Although the BD dataset does not specify which EEG channels were used for annotation, it is reasonable to assume that the experts analyzed the same channels investigated in the study presenting the dataset (F3-A2, F4-A1, C3-A2, and C4-A1).17.
model: Following the SUMO study, we considered the spindle detection task as a single EEG channel segmentation problem.16. SUMOv2 uses the SUMO model architecture. This is a U-Net with two encoder blocks and two decoder blocks. SUMOv2 accepts an input sequence of arbitrary length and outputs two segmentation masks that indicate whether a spindle is present (maximum value of the first mask) or absent (maximum value of the second mask) for each data point in the input sequence. Successive representations of spindle presence were combined to form a final spindle annotation consisting of starting sample and duration.
To detect spindles using SUMOv2 or to train the model, we preprocessed the data by dividing the data into consecutive blocks of N2 sleep according to sleep stage annotations. Each block of N2 sleep was then filtered with a 20th-order Butterworth high-pass filter at 0.3 Hz, followed by a 20th-order Butterworth low-pass filter at 30 Hz, downsampled to 100 Hz, and normalized by subtracting the median amplitude and dividing by the interquartile range. Amplitudes outside the -20 to 20 range were clipped to their respective boundaries.
training: For training SUMOv2, we split the MODA dataset into a training set and a test set. The test set consisted of data from 36 subjects with 3 blocks of 115 seconds each (see the SUMO study for details on how subjects were selected)16). The training set was further divided into 6 cross-validation folds, each containing data from 5 subjects with 10 115-second blocks and 19 subjects with 3 115-second blocks. After optimizing the hyperparameters on this cross-validation split, we retrained the final model on the entire training set, reserving 10% of the data for early stopping. The DREAMS and BD datasets were not part of the training or validation process and were used for testing purposes only.
We trained the model using the Adam optimizer, a batch size of 12, a learning rate of 0.005, and a generalized Dice loss, a variant of the Dice loss that is more robust to class imbalance.42. To prevent overfitting, we trained the model until the validation set’s IoU-F1 score (see next section) no longer improved in 300 consecutive training epochs, or until we reached 800 training epochs.
We found that the original SUMO model is sensitive to variations in EEG amplitude, which poses a challenge for datasets with different amplitude distributions, such as patient groups or other recording settings where spindle activity is less pronounced. To address this issue in SUMOv2, we used data augmentation with random rescaling of EEG amplitudes during training to make the model more robust. Each sample was randomly selected to either upscale (multiply by a random factor of 1 to 2) or downscale (multiply by a random factor of 0.5 to 1) to ensure adaptability to different amplitude distributions.
evaluation: When evaluating SUMOv2 on the BD dataset, we applied the model separately to each of the four EEG channels present in the data and then aggregated the detected spindles across channels by taking a union of annotations (i.e. overlapping annotations in different channels were merged and non-overlapping annotations remained separated).
Follow standard procedures outlined in the MODA studytwenty oneWe post-processed the detected spindles for all datasets by merging spindles shorter than 0.1 seconds that were separated by less than 0.3 seconds, followed by removing spindles with durations less than 0.3 seconds or greater than 2.5 seconds.
We used the Intersection-over-Union (IoU) F1 score to evaluate the model performance. Given two sets of spindle annotations, IoU-F1 scores were calculated for each spindle. Each spindle in the first set was matched with the temporally closest spindle in the second set. A spindle is considered a true positive (TP) if the overlap of two matching spindles divided by the combined spindle duration is greater than 20%. The first and second set of spindles for which there were no matches that met the threshold are considered false positives (FP) and false negatives (FN), respectively. TP, FP, and FN were summed across all records or data segments that were jointly annotated (i.e., when calculating the IoU-F1 score between two experts, we summed TP, FP, and FN across all records annotated by both experts). The IoU-F1 score was calculated as follows. \(2 \cdot \text {TP} / (2 \cdot \text {TP} + \text {FP} + \text {FN})\).
In calculating the pairwise inter-rater agreement level for the MODA dataset, we only considered expert pairs with at least 5 jointly annotated blocks, corresponding to approximately 9.5 minutes of EEG data (280 expert pairs met this criterion).
spindle characteristics: For the detected spindles, we calculated the spindle density, duration, frequency, and amplitude. Spindle density (spindles per minute, SPM) was determined by dividing the number of spindles detected during N2 sleep by the total time of N2 sleep. Spindle duration was measured as the time between the first and last sample of each spindle. To calculate the spindle frequency and amplitude, we first applied a fourth-order Butterworth bandpass filter (10–16 Hz) to the raw EEG signal. The spindle frequency was calculated as the average of the instantaneous frequencies determined as half of the reciprocal of the zero-crossing spacing of the bandpass filtered signal. Spindle amplitude was determined as the mean absolute value of the Hilbert-transformed filtered signal.


